


ทีม Android Runtime (ART) ได้ลดเวลาคอมไพล์ลง 18% โดยไม่ลดทอนคุณภาพของโค้ดที่คอมไพล์แล้วหรือการถดถอยของหน่วยความจำสูงสุด การปรับปรุงนี้เป็นส่วนหนึ่งของความคิดริเริ่มในปี 2025 ของเราในการปรับปรุงเวลาคอมไพล์โดยไม่ลดการใช้งานหน่วยความจำหรือคุณภาพของโค้ดที่คอมไพล์แล้ว
การเพิ่มประสิทธิภาพความเร็วในการคอมไพล์เป็นสิ่งสำคัญสำหรับ ART เช่น เมื่อคอมไพล์แบบ Just-In-Time (JIT) จะส่งผลโดยตรงต่อประสิทธิภาพของแอปพลิเคชันและประสิทธิภาพโดยรวมของอุปกรณ์ การคอมไพล์ที่เร็วขึ้นจะช่วยลดเวลาก่อนที่การเพิ่มประสิทธิภาพจะเริ่มทำงาน ซึ่งจะส่งผลให้ประสบการณ์ของผู้ใช้ราบรื่นและตอบสนองได้ดียิ่งขึ้น นอกจากนี้ ทั้งสำหรับ JIT และ Ahead-Of-Time (AOT) การปรับปรุงความเร็วในการคอมไพล์จะช่วยลดการใช้ทรัพยากรในระหว่างกระบวนการคอมไพล์ ซึ่งเป็นประโยชน์ต่อระยะเวลาการใช้งานแบตเตอรี่และอุณหภูมิของอุปกรณ์ โดยเฉพาะอย่างยิ่งในอุปกรณ์ระดับล่าง
การปรับปรุงความเร็วในการคอมไพล์บางส่วนเปิดตัวใน Android เวอร์ชันที่เผยแพร่ในเดือนมิถุนายน 2025 และส่วนที่เหลือจะพร้อมใช้งานใน Android เวอร์ชันที่เผยแพร่ในช่วงสิ้นปี นอกจากนี้ ผู้ใช้ Android ทุกคนในเวอร์ชัน 12 ขึ้นไปมีสิทธิ์รับการปรับปรุงเหล่านี้ผ่านการอัปเดต Mainline
การเพิ่มประสิทธิภาพคอมไพเลอร์ที่เพิ่มประสิทธิภาพ
การเพิ่มประสิทธิภาพคอมไพเลอร์มักจะต้องมีการแลกเปลี่ยนเสมอ คุณไม่สามารถได้ความเร็วมาฟรีๆ แต่ต้องยอมเสียบางอย่างไป เราตั้งเป้าหมายที่ชัดเจนและท้าทายไว้ว่า จะทำให้คอมไพเลอร์เร็วขึ้น แต่ต้องไม่ทำให้เกิดการถดถอยของหน่วยความจำ และที่สำคัญคือต้องไม่ลดคุณภาพของโค้ดที่คอมไพเลอร์สร้างขึ้น หากคอมไพเลอร์เร็วขึ้นแต่แอปทำงานช้าลง เราก็ถือว่าล้มเหลว
ทรัพยากรเดียวที่เรายินดีที่จะใช้คือเวลาในการพัฒนาของเราเองเพื่อเจาะลึก ตรวจสอบ และค้นหาวิธีแก้ปัญหาที่ชาญฉลาดซึ่งตรงตามเกณฑ์ที่เข้มงวดเหล่านี้ มาดูรายละเอียดเพิ่มเติมเกี่ยวกับวิธีที่เราทำงานเพื่อค้นหาจุดที่ควรปรับปรุง รวมถึงค้นหาวิธีแก้ปัญหาที่เหมาะสมสำหรับปัญหาต่างๆ
การค้นหาการเพิ่มประสิทธิภาพที่เป็นไปได้และคุ้มค่า
ก่อนที่จะเริ่มเพิ่มประสิทธิภาพเมตริก คุณต้องวัดเมตริกนั้นได้ มิฉะนั้น คุณจะไม่มีทางแน่ใจได้ว่าได้ปรับปรุงเมตริกนั้นแล้วหรือไม่ โชคดีที่ความเร็วในการคอมไพล์ค่อนข้างสม่ำเสมอ ตราบใดที่คุณใช้ความระมัดระวังบางอย่าง เช่น ใช้อุปกรณ์เครื่องเดียวกับที่ใช้ในการวัดก่อนและหลังการเปลี่ยนแปลง และตรวจสอบว่าคุณไม่ได้จำกัดความเร็วของอุปกรณ์เนื่องจากความร้อน นอกจากนี้ เรายังมีการวัดที่กำหนดได้ เช่น สถิติคอมไพเลอร์ ซึ่งช่วยให้เราเข้าใจสิ่งที่เกิดขึ้นเบื้องหลัง
เนื่องจากทรัพยากรที่เราเสียไปเพื่อการปรับปรุงเหล่านี้คือเวลาในการพัฒนา เราจึงต้องการทำซ้ำให้เร็วที่สุดเท่าที่จะทำได้ ซึ่งหมายความว่าเราได้เลือกแอปที่เป็นตัวแทนมาจำนวนหนึ่ง (ทั้งแอปของบุคคลที่หนึ่ง แอปของบุคคลที่สาม และระบบปฏิบัติการ Android เอง) เพื่อสร้างต้นแบบโซลูชัน ต่อมา เราได้ยืนยันว่าการติดตั้งใช้งานขั้นสุดท้ายนั้นคุ้มค่าด้วยการทดสอบทั้งแบบแมนนวลและแบบอัตโนมัติในวงกว้าง
เราจะทริกเกอร์การคอมไพล์แบบแมนนวลในเครื่องด้วยชุด APK ที่เลือกไว้ จากนั้นรับโปรไฟล์การคอมไพล์ และใช้ pprof เพื่อแสดงภาพว่าเราใช้เวลาไปกับส่วนใดบ้าง
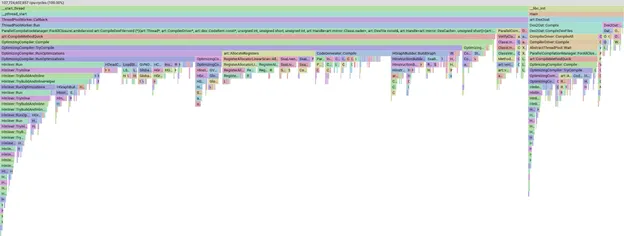
ตัวอย่างกราฟ Flame Graph ของโปรไฟล์ใน pprof
เครื่องมือ pprof มีประสิทธิภาพมากและช่วยให้เราแบ่ง กรอง และจัดเรียงข้อมูลเพื่อดูได้ เช่น ระยะการคอมไพล์หรือเมธอดใดใช้เวลามากที่สุด เราจะไม่ลงรายละเอียดเกี่ยวกับ pprof เอง เพียงแค่ทราบว่าหากแถบมีขนาดใหญ่ขึ้น แสดงว่าการคอมไพล์ใช้เวลานานขึ้น
มุมมองหนึ่งคือมุมมอง "จากล่างขึ้นบน" ซึ่งคุณจะเห็นเมธอดที่ใช้เวลามากที่สุด ในรูปภาพด้านล่าง เราจะเห็นเมธอดที่ชื่อว่า Kill ซึ่งใช้เวลาคอมไพล์มากกว่า 1% นอกจากนี้ เราจะพูดถึงเมธอดยอดนิยมอื่นๆ ในบล็อกโพสต์นี้ด้วย
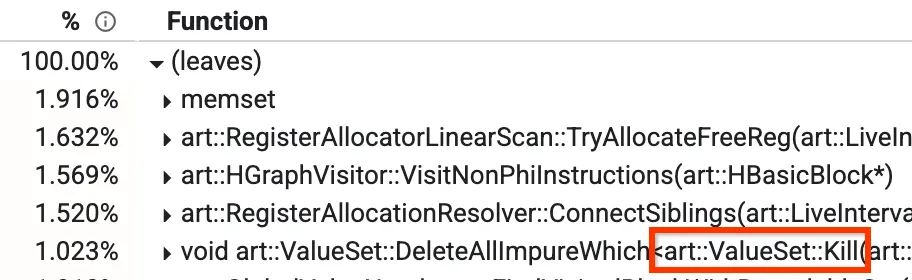
มุมมองจากล่างขึ้นบนของโปรไฟล์
ในคอมไพเลอร์ที่เพิ่มประสิทธิภาพของเรา มีระยะที่เรียกว่า Global Value Numbering (GVN) คุณไม่จำเป็นต้องกังวลเกี่ยวกับสิ่งที่ GVN ทำโดยรวม แต่ส่วนที่เกี่ยวข้องคือการทราบว่า GVN มีเมธอดที่ชื่อว่า `Kill` ซึ่งจะลบบางโหนดตามตัวกรอง การดำเนินการนี้ใช้เวลานานเนื่องจากต้องทำซ้ำผ่านโหนดทั้งหมดและตรวจสอบทีละโหนด เราสังเกตเห็นว่ามีบางกรณีที่เรารู้ล่วงหน้าว่าการตรวจสอบจะเป็นเท็จ ไม่ว่าจะมีโหนดใดที่ใช้งานได้ในขณะนั้น ในกรณีเหล่านี้ เราสามารถข้ามการทำซ้ำทั้งหมดได้ ซึ่งจะลดเวลาจาก 1.023% ลงเหลือประมาณ 0.3% และปรับปรุงรันไทม์ของ GVN ประมาณ 15%
การติดตั้งใช้งานการเพิ่มประสิทธิภาพที่คุ้มค่า
เราได้พูดถึงวิธีวัดและวิธีตรวจหาจุดที่ใช้เวลาไป แต่ทั้งหมดนี้เป็นเพียงจุดเริ่มต้น ขั้นตอนถัดไปคือวิธีเพิ่มประสิทธิภาพเวลาที่ใช้ในการคอมไพล์
โดยปกติแล้ว ในกรณีเช่น `Kill` ที่กล่าวถึงข้างต้น เราจะดูวิธีทำซ้ำผ่านโหนดและดำเนินการให้เร็วขึ้น เช่น ทำสิ่งต่างๆ แบบขนานกันหรือปรับปรุงอัลกอริทึมเอง อันที่จริงแล้ว เราได้ลองทำแบบนั้นก่อน และเมื่อไม่พบสิ่งที่จะทำ เราก็เกิดความคิดขึ้นมาว่า "เดี๋ยวนะ..." และเห็นว่าวิธีแก้ปัญหาคือ (ในบางกรณี) ไม่ต้องทำซ้ำเลย! เมื่อทำการเพิ่มประสิทธิภาพประเภทนี้ คุณอาจมองข้ามภาพรวมไปได้ง่ายๆ
ในกรณีอื่นๆ เราใช้เทคนิคต่างๆ มากมาย ซึ่งรวมถึง
- ใช้ฮิวริสติกเพื่อตัดสินว่าการเพิ่มประสิทธิภาพจะให้ผลลัพธ์ที่คุ้มค่าหรือไม่ และจึงข้ามการเพิ่มประสิทธิภาพนั้นได้
- ใช้โครงสร้างข้อมูลเพิ่มเติมเพื่อแคชข้อมูลที่คำนวณแล้ว
- เปลี่ยนโครงสร้างข้อมูลปัจจุบันเพื่อเพิ่มความเร็ว
- คำนวณผลลัพธ์แบบเลซี่เพื่อหลีกเลี่ยงการวนซ้ำในบางกรณี
- ใช้การแยกส่วนที่เหมาะสม ฟีเจอร์ที่ไม่จำเป็นอาจทำให้โค้ดทำงานช้าลง
- หลีกเลี่ยงการติดตามพอยน์เตอร์ที่ใช้บ่อยผ่านการโหลดหลายครั้ง
เราจะทราบได้อย่างไรว่าการเพิ่มประสิทธิภาพนั้นคุ้มค่าที่จะทำต่อ
คุณไม่จำเป็นต้องทราบ หลังจากตรวจพบว่าส่วนหนึ่งใช้เวลาคอมไพล์มาก และหลังจากใช้เวลาในการพัฒนาเพื่อพยายามปรับปรุงส่วนนั้นแล้ว บางครั้งคุณก็ไม่สามารถหาวิธีแก้ปัญหาได้ อาจไม่มีอะไรให้ทำ การติดตั้งใช้งานจะใช้เวลานานเกินไป การดำเนินการนั้นจะทำให้เมตริกอื่นถดถอยลงอย่างมาก เพิ่มความซับซ้อนของฐานของโค้ด ฯลฯ การเพิ่มประสิทธิภาพที่สำเร็จทุกครั้งที่คุณเห็นในบล็อกโพสต์นี้มีอีกมากมายนับไม่ถ้วนที่ไม่ประสบความสำเร็จ
หากคุณอยู่ในสถานการณ์ที่คล้ายกัน ให้ลองประมาณว่าคุณจะปรับปรุงเมตริกได้มากน้อยเพียงใดโดยทำงานให้น้อยที่สุดเท่าที่จะทำได้ ซึ่งหมายความว่าให้ทำตามลำดับต่อไปนี้
- ประมาณการโดยใช้เมตริกที่คุณได้รวบรวมไว้แล้ว หรือเพียงแค่ใช้ความรู้สึก
- ประมาณการโดยใช้ต้นแบบแบบเร็วและไม่ละเอียด
- ติดตั้งใช้งานโซลูชัน
อย่าลืมพิจารณาประมาณการข้อเสียของโซลูชันด้วย เช่น หากคุณจะใช้โครงสร้างข้อมูลเพิ่มเติม คุณยินดีที่จะใช้หน่วยความจำเท่าใด
เจาะลึกลงไปอีก
มาดูการเปลี่ยนแปลงบางอย่างที่เราติดตั้งใช้งานกัน
เราได้ติดตั้งใช้งานการเปลี่ยนแปลงเพื่อเพิ่มประสิทธิภาพเมธอดที่ชื่อว่า FindReferenceInfoOf เมธอดนี้ทำการค้นหาแบบเชิงเส้นของเวกเตอร์เพื่อค้นหารายการ เราได้อัปเดตโครงสร้างข้อมูลนั้นให้มีการจัดทำดัชนีตามรหัสของคำสั่ง เพื่อให้ FindReferenceInfoOf เป็น O(1) แทนที่จะเป็น O(n) นอกจากนี้ เรายังได้จัดสรรเวกเตอร์ไว้ล่วงหน้าเพื่อหลีกเลี่ยงการปรับขนาด เราได้เพิ่มหน่วยความจำเล็กน้อยเนื่องจากต้องเพิ่มช่องเพิ่มเติมที่นับจำนวนรายการที่เราแทรกลงในเวกเตอร์ แต่ก็เป็นการเสียสละเพียงเล็กน้อยเนื่องจากหน่วยความจำสูงสุดไม่ได้เพิ่มขึ้น การดำเนินการนี้ทำให้ระยะ LoadStoreAnalysis เร็วขึ้น 34-66% ซึ่งจะช่วยปรับปรุงเวลาคอมไพล์ประมาณ 0.5-1.8%
เรามีการติดตั้งใช้งาน HashSet แบบกำหนดเองที่เราใช้ในหลายๆ ที่ การสร้างโครงสร้างข้อมูลนี้ใช้เวลานานพอสมควร และเราได้ทราบสาเหตุแล้ว เมื่อหลายปีก่อน โครงสร้างข้อมูลนี้ใช้ในไม่กี่ที่เท่านั้นที่ใช้ HashSet ขนาดใหญ่มาก และมีการปรับแต่งให้เหมาะกับการใช้งานนั้น อย่างไรก็ตาม ปัจจุบันมีการใช้โครงสร้างข้อมูลนี้ในทางตรงกันข้าม โดยมีรายการเพียงไม่กี่รายการและมีอายุการใช้งานสั้น ซึ่งหมายความว่าเราเสียรอบการทำงานไปกับการสร้าง HashSet ขนาดใหญ่ แต่ใช้เพียงไม่กี่รายการก่อนที่จะทิ้ง ด้วยการเปลี่ยนแปลงนี้ เราปรับปรุงเวลาคอมไพล์ได้ประมาณ 1.3-2% นอกจากนี้ การใช้งานหน่วยความจำยังลดลงประมาณ 0.5-1% เนื่องจากเราไม่ได้ใช้โครงสร้างข้อมูลขนาดใหญ่เท่าเมื่อก่อน
เราได้ปรับปรุงเวลาคอมไพล์ประมาณ 0.5-1% โดยส่งโครงสร้างข้อมูลตามการอ้างอิงไปยังแลมดาเพื่อหลีกเลี่ยงการคัดลอกโครงสร้างข้อมูล การดำเนินการนี้เป็นสิ่งที่ถูกมองข้ามไปในการตรวจสอบครั้งแรกและอยู่ในฐานโค้ดของเรามาหลายปี เราสังเกตเห็นว่าเมธอดเหล่านี้สร้างและทำลายโครงสร้างข้อมูลจำนวนมากจากการดูโปรไฟล์ใน pprof ซึ่งนำไปสู่การตรวจสอบและเพิ่มประสิทธิภาพเมธอดเหล่านั้น
เราได้เพิ่มความเร็วในระยะที่เขียนเอาต์พุตที่คอมไพล์แล้วโดยการแคชค่าที่คำนวณแล้ว ซึ่งช่วยปรับปรุงเวลาคอมไพล์ทั้งหมดประมาณ 1.3-2.8% น่าเสียดายที่การบันทึกเพิ่มเติมมากเกินไปและการทดสอบอัตโนมัติของเราได้แจ้งเตือนเราถึงการถดถอยของหน่วยความจำ ต่อมา เราได้ตรวจสอบโค้ดเดียวกันอีกครั้งและติดตั้งใช้งานเวอร์ชันใหม่ที่ไม่เพียงแต่จัดการกับการถดถอยของหน่วยความจำเท่านั้น แต่ยังปรับปรุงเวลาคอมไพล์เพิ่มขึ้นอีกประมาณ 0.5-1.8% ด้วย ในการเปลี่ยนแปลงครั้งที่ 2 นี้ เราต้องปรับโครงสร้างและจินตนาการใหม่ว่าระยะนี้ควรทำงานอย่างไร เพื่อกำจัดโครงสร้างข้อมูล 1 ใน 2 รายการ
เรามีระยะหนึ่งในคอมไพเลอร์ที่เพิ่มประสิทธิภาพซึ่งจะอินไลน์การเรียกใช้ฟังก์ชันเพื่อเพิ่มประสิทธิภาพ เราใช้ทั้งฮิวริสติกก่อนที่จะทำการคำนวณ และการตรวจสอบขั้นสุดท้ายหลังจากทำงานเสร็จแล้วแต่ก่อนที่จะสรุปการอินไลน์ เพื่อเลือกเมธอดที่จะอินไลน์ หากการตรวจสอบใดๆ เหล่านั้นตรวจพบว่าการอินไลน์ไม่คุ้มค่า (เช่น จะมีการเพิ่มคำสั่งใหม่มากเกินไป) เราจะไม่ทำการอินไลน์การเรียกใช้เมธอด
เราได้ย้ายการตรวจสอบ 2 รายการจากหมวดหมู่ "การตรวจสอบขั้นสุดท้าย" ไปยังหมวดหมู่ "ฮิวริสติก" เพื่อประมาณว่าการอินไลน์จะสำเร็จหรือไม่ก่อนที่จะทำการคำนวณที่ใช้เวลานาน เนื่องจากเป็นการประมาณการ จึงอาจไม่สมบูรณ์แบบ แต่เราได้ยืนยันว่าฮิวริสติกใหม่ของเราครอบคลุม 99.9% ของสิ่งที่เคยอินไลน์ไว้ก่อนหน้านี้โดยไม่ส่งผลต่อประสิทธิภาพ ฮิวริสติกใหม่รายการหนึ่งเกี่ยวกับรีจิสเตอร์ DEX ที่จำเป็น (ปรับปรุงประมาณ 0.2-1.3%) และอีกรายการหนึ่งเกี่ยวกับจำนวนคำสั่ง (ปรับปรุงประมาณ 2%)
เรามีการติดตั้งใช้งาน BitVector แบบกำหนดเองที่เราใช้ในหลายๆ ที่ เราได้แทนที่คลาส BitVector ที่ปรับขนาดได้ด้วย BitVectorView ที่ง่ายกว่าสำหรับเวกเตอร์บิตขนาดคงที่บางรายการ การดำเนินการนี้จะกำจัดทางอ้อมบางส่วนและการตรวจสอบช่วงรันไทม์ และเพิ่มความเร็วในการสร้างออบเจ็กต์เวกเตอร์บิต
นอกจากนี้ คลาส BitVectorView ยังได้รับการสร้างเทมเพลตตามประเภทพื้นที่เก็บข้อมูลพื้นฐาน (แทนที่จะใช้ uint32_t เสมอเหมือน BitVector แบบเก่า) การดำเนินการนี้ช่วยให้การดำเนินการบางอย่าง เช่น Union() สามารถประมวลผลบิตได้ 2 เท่าพร้อมกันในแพลตฟอร์ม 64 บิต ตัวอย่างฟังก์ชันที่ได้รับผลกระทบจะลดลงมากกว่า 1% โดยรวมเมื่อคอมไพล์ระบบปฏิบัติการ Android การดำเนินการนี้ทำผ่านการเปลี่ยนแปลงหลายรายการ [1, 2, 3, 4, 5, 6]
หากเราพูดถึงการเพิ่มประสิทธิภาพทั้งหมดโดยละเอียด เราคงต้องอยู่ที่นี่ทั้งวัน หากคุณสนใจการเพิ่มประสิทธิภาพเพิ่มเติม โปรดดูการเปลี่ยนแปลงอื่นๆ ที่เราติดตั้งใช้งาน
- เพิ่มการบันทึก เพื่อปรับปรุงเวลาคอมไพล์ประมาณ 0.6-1.6%
- คำนวณข้อมูลแบบเลซี่ เพื่อหลีกเลี่ยงการวนซ้ำ หากเป็นไปได้
- ปรับโครงสร้างโค้ด เพื่อข้ามการทำงานก่อนการคำนวณเมื่อจะไม่มีการใช้งาน
- หลีกเลี่ยงการโหลดเชนที่ขึ้นอยู่กับกัน เมื่อได้รับตัวจัดสรรจากที่อื่นได้ง่าย
- อีกกรณีหนึ่งของการเพิ่มการตรวจสอบเพื่อหลีกเลี่ยงการทำงานที่ไม่จำเป็น
- หลีกเลี่ยงการแยกสาขาบ่อยๆ ตามประเภทรีจิสเตอร์ (Core/FP) ในตัวจัดสรรรีจิสเตอร์
- ตรวจสอบว่ามีการเริ่มต้นอาร์เรย์บางรายการในเวลาคอมไพล์ อย่าพึ่งพา Clang ในการดำเนินการนี้
- ล้างการวนซ้ำบางรายการ ใช้การวนซ้ำช่วงที่ Clang เพิ่มประสิทธิภาพได้ดีกว่าเนื่องจากไม่จำเป็นต้องโหลดพอยน์เตอร์ภายในของคอนเทนเนอร์ซ้ำเนื่องจากผลข้างเคียงของการวนซ้ำ หลีกเลี่ยงการเรียกใช้ฟังก์ชันเสมือน `HInstruction::GetInputRecords()` ในการวนซ้ำผ่าน `InputAt(.)` ที่อินไลน์สำหรับอินพุตแต่ละรายการ
- หลีกเลี่ยงฟังก์ชัน Accept() สำหรับรูปแบบ Visitor โดยใช้ประโยชน์จากการเพิ่มประสิทธิภาพคอมไพเลอร์
บทสรุป
ความมุ่งมั่นของเราในการปรับปรุงความเร็วในการคอมไพล์ของ ART ได้ผลลัพธ์ที่สำคัญ ซึ่งทำให้ Android ทำงานได้ราบรื่นและมีประสิทธิภาพมากขึ้น รวมถึงช่วยยืดระยะเวลาการใช้งานแบตเตอรี่และลดความร้อนของอุปกรณ์ การระบุและติดตั้งใช้งานการเพิ่มประสิทธิภาพอย่างขยันขันแข็งแสดงให้เห็นว่าการปรับปรุงเวลาคอมไพล์อย่างมากเป็นไปได้โดยไม่ลดการใช้งานหน่วยความจำหรือคุณภาพของโค้ด
การเดินทางของเราเกี่ยวข้องกับการสร้างโปรไฟล์ด้วยเครื่องมือต่างๆ เช่น pprof ความเต็มใจที่จะทำซ้ำ และบางครั้งก็ละทิ้งแนวทางที่ไม่ค่อยได้ผล ความพยายามร่วมกันของทีม ART ไม่เพียงแต่ลดเวลาคอมไพล์ลงได้มากเท่านั้น แต่ยังวางรากฐานสำหรับการพัฒนาในอนาคตด้วย
การปรับปรุงทั้งหมดนี้พร้อมใช้งานในการอัปเดต Android ช่วงสิ้นปี 2025 และสำหรับ Android 12 ขึ้นไปผ่านการอัปเดต Mainline เราหวังว่าการเจาะลึกกระบวนการเพิ่มประสิทธิภาพของเรานี้จะให้ข้อมูลเชิงลึกที่มีคุณค่าเกี่ยวกับความซับซ้อนและผลตอบแทนของวิศวกรรมคอมไพเลอร์
-

 ข่าวสารเกี่ยวกับผลิตภัณฑ์
ข่าวสารเกี่ยวกับผลิตภัณฑ์ที่ Google Play เรามุ่งมั่นที่จะมอบประสบการณ์การใช้งานที่ดีที่สุดแก่ผู้ใช้ พร้อมทั้งตรวจสอบว่านักพัฒนาแอปมีเครื่องมือและความสามารถในการปรับตัวเพื่อประสบความสำเร็จ
Paul Feng • ใช้เวลาอ่าน 3 นาที -

 ข่าวสารเกี่ยวกับผลิตภัณฑ์
ข่าวสารเกี่ยวกับผลิตภัณฑ์เมื่อปีที่แล้ว เราได้เปิดตัวการยืนยันนักพัฒนาแอป Android เพื่อเสริมความปลอดภัยของระบบนิเวศและหยุดผู้ไม่ประสงค์ดีไม่ให้ซ่อนตัวอยู่เบื้องหลังการไม่เปิดเผยตัวตนเพื่อเผยแพร่แอปที่เป็นอันตราย
Matthew Forsythe • ใช้เวลาอ่าน 2 นาที -


 ข่าวสารเกี่ยวกับผลิตภัณฑ์
ข่าวสารเกี่ยวกับผลิตภัณฑ์ระบบนิเวศ Android XR กำลังขยายตัวอย่างรวดเร็ว ตั้งแต่การซ้อนทับแบบเสริมไปจนถึงสภาพแวดล้อมที่สมจริงอย่างเต็มรูปแบบ โดย Samsung Galaxy XR พร้อมจำหน่ายแล้ววันนี้
Stevan Silva, Vinny DaSilva • ใช้เวลาอ่าน 3 นาที
รับข้อมูลเชิงลึกล่าสุดเกี่ยวกับการพัฒนา Android ส่งตรงถึงกล่องจดหมายของคุณ ทุกสัปดาห์
