
Notizie sui prodotti
Migliorare lo sviluppo Android assistito dall'AI e i modelli LLM con Android Bench
Lettura di 2 minuti


Vogliamo rendere più facile e veloce la creazione di app per Android di alta qualità e uno dei modi in cui ti aiutiamo a essere più produttivo è mettere l'AI a portata di mano. Sappiamo che vuoi un'AI che comprenda davvero le sfumature della piattaforma Android, motivo per cui abbiamo misurato il rendimento dei modelli LLM nelle attività di sviluppo Android. Oggi abbiamo rilasciato la prima versione di Android Bench, la nostra classifica ufficiale dei modelli LLM per lo sviluppo Android.
Il nostro obiettivo è fornire ai creatori di modelli un benchmark per valutare le funzionalità dei modelli LLM per lo sviluppo Android. Stabilendo una base di riferimento chiara e affidabile per lo sviluppo Android di alta qualità, aiutiamo i creatori di modelli a identificare le lacune e ad accelerare i miglioramenti, il che consente agli sviluppatori di lavorare in modo più efficiente con una gamma più ampia di modelli utili da scegliere per l'assistenza AI, il che alla fine porterà ad app di qualità superiore nell'ecosistema Android.
Progettato con attività di sviluppo Android reali
Abbiamo creato il benchmark curando un insieme di attività in una serie di aree di sviluppo Android comuni. È composto da sfide reali di varia difficoltà, provenienti da repository Android pubblici di GitHub. Gli scenari includono la risoluzione di modifiche che causano interruzioni tra le release di Android, attività specifiche del dominio come la rete su wearable e la migrazione all'ultima versione di Jetpack Compose, solo per citarne alcuni.
Ogni valutazione tenta di far risolvere al modello LLM il problema segnalato nell'attività, che poi verifichiamo utilizzando test unitari o di strumentazione. Questo approccio indipendente dal modello ci consente di misurare la capacità di un modello di navigare in codebase complesse, comprendere le dipendenze e risolvere il tipo di problemi che incontri ogni giorno.
Abbiamo convalidato questa metodologia con diversi produttori di modelli LLM, tra cui JetBrains.
"Misurare l'impatto dell'AI su Android è una sfida enorme, quindi è fantastico vedere un framework così solido e realistico. Sebbene siamo attivi nel benchmarking, Android Bench è un'aggiunta unica e gradita. Questa metodologia è esattamente il tipo di valutazione rigorosa di cui gli sviluppatori Android hanno bisogno in questo momento."
- Kirill Smelov, Head of AI Integrations presso JetBrains.
I primi risultati di Android Bench
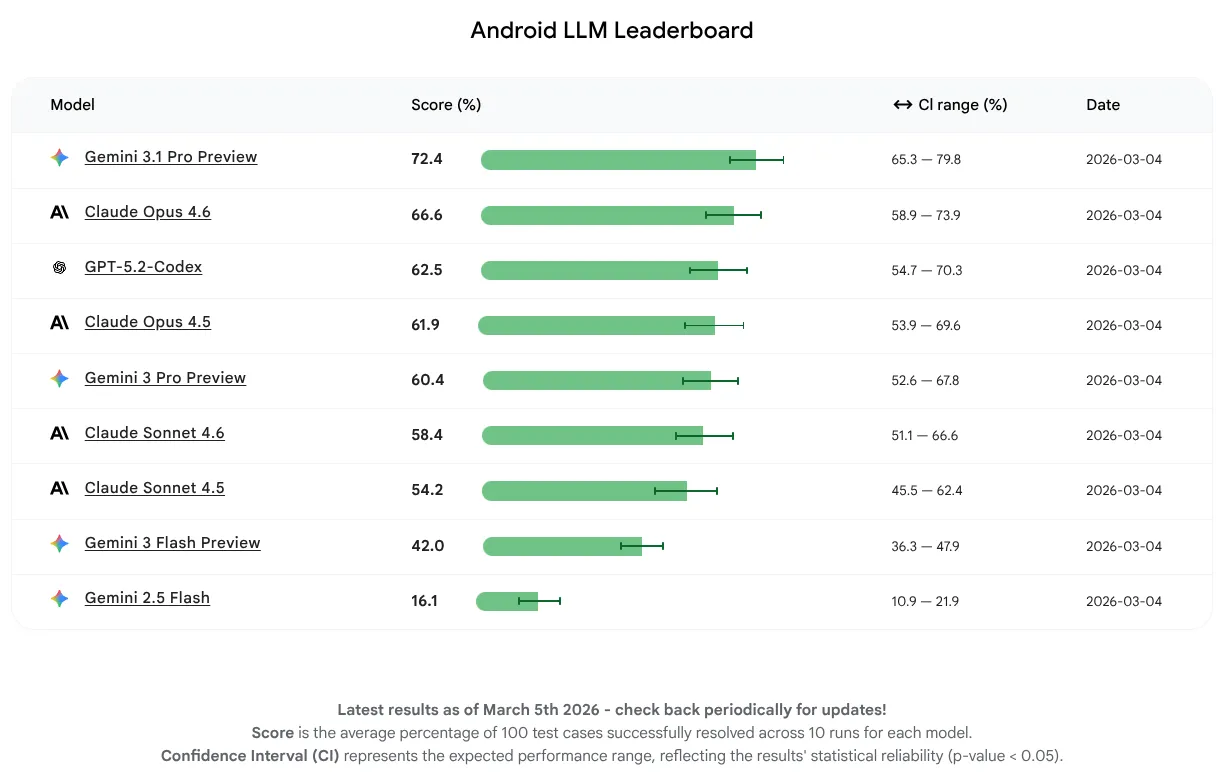
Per questa release iniziale, volevamo misurare esclusivamente il rendimento del modello e non concentrarci sull'utilizzo di agenti o strumenti. I modelli sono stati in grado di completare correttamente il 16-72% delle attività. Si tratta di un'ampia gamma che dimostra che alcuni modelli LLM hanno già una solida base di conoscenza di Android, mentre altri hanno più margini di miglioramento. Indipendentemente dalla situazione attuale dei modelli, prevediamo un miglioramento continuo man mano che incoraggiamo i produttori di modelli LLM a migliorare i propri modelli per lo sviluppo Android.
Il modello LLM con il punteggio medio più alto per questa prima release è Gemini 3.1 Pro, seguito da vicino da Claude Opus 4.6. Puoi provare tutti i modelli che abbiamo valutato per l'assistenza AI per i tuoi progetti Android utilizzando le chiavi API nell'ultima versione stabile di Android Studio.
Fornire trasparenza a sviluppatori e produttori di modelli LLM
Apprezziamo un approccio aperto e trasparente, quindi abbiamo reso la nostra metodologia, il nostro set di dati e il nostro harness di test disponibili pubblicamente su GitHub.
Una sfida per qualsiasi benchmark pubblico è il rischio di contaminazione dei dati, in cui i modelli potrebbero aver visto le attività di valutazione durante il processo di addestramento. Abbiamo adottato misure per garantire che i nostri risultati riflettano un ragionamento genuino anziché la memorizzazione o la supposizione, inclusa una revisione manuale approfondita delle traiettorie degli agenti o l'integrazione di una stringa canary per scoraggiare l'addestramento.
In futuro, continueremo a far evolvere la nostra metodologia per preservare l'integrità del set di dati, apportando al contempo miglioramenti per le future release del benchmark, ad esempio aumentando la quantità e la complessità delle attività.
Non vediamo l'ora di scoprire come Android Bench può migliorare l'assistenza AI a lungo termine. La nostra visione è quella di colmare il divario tra il concetto e il codice di qualità. Stiamo gettando le basi per un futuro in cui, indipendentemente da ciò che immagini, potrai crearlo su Android.
Scritto da:
Continua a leggere
-

Notizie sui prodotti
Come annunciato oggi durante The Android Show, Android sta passando da un sistema operativo a un sistema di intelligence, creando maggiori opportunità di coinvolgimento con le tue app.
Matthew McCullough • Lettura di 4 minuti
-

Notizie sui prodotti
Oggi miglioriamo lo sviluppo Android con Gemma 4, il nostro modello aperto all'avanguardia più recente progettato con funzionalità di ragionamento complesso e chiamata di strumenti autonomi.
Matthew McCullough • Lettura di 2 minuti
-

Notizie sui prodotti
Oggi Android 17 ha raggiunto ufficialmente la stabilità della piattaforma con la versione beta 3. Ciò significa che la superficie API è bloccata. Puoi eseguire i test di compatibilità finali e inviare le app destinate ad Android 17 al Play Store.
Matthew McCullough • Lettura di 5 minuti
Resta al passo con le novità
Ricevi ogni settimana nella tua casella di posta gli ultimi approfondimenti sullo sviluppo Android
