
أخبار المنتجات
تحسين تطوير تطبيقات Android بمساعدة الذكاء الاصطناعي وتطوير النماذج اللغوية الكبيرة باستخدام Android Bench
قراءة لمدة دقيقتَين


نريد أن نسهّل عليك ونزيد من سرعة إنشاء تطبيقات Android عالية الجودة، وإحدى الطرق التي نساعدك بها على زيادة إنتاجيتك هي توفير الذكاء الاصطناعي بين يديك. نعلم أنّك تريد ذكاءً اصطناعيًا يفهم بدقة الفروقات الدقيقة في نظام Android الأساسي، ولهذا السبب، كنّا نقيس أداء النماذج اللغوية الكبيرة في مهام تطوير Android. أطلقنا اليوم الإصدار الأول من Android Bench، وهو لوحة الصدارة الرسمية للنماذج اللغوية الكبيرة لتطوير Android.
هدفنا هو تزويد صنّاع النماذج بمقياس لتقييم إمكانات النماذج اللغوية الكبيرة لتطوير Android. من خلال وضع أساس واضح وموثوق به لما يبدو عليه تطوير Android عالي الجودة، نساعد صنّاع النماذج في تحديد الثغرات وتسريع التحسينات، ما يمنح المطوّرين القدرة على العمل بكفاءة أكبر باستخدام مجموعة أوسع من النماذج المفيدة التي يمكنهم الاختيار من بينها للحصول على المساعدة من الذكاء الاصطناعي، ما سيؤدي في النهاية إلى تطبيقات أعلى جودة في جميع أنحاء منظومة Android المتكاملة.
تم تصميمه باستخدام مهام تطوير Android في العالم الحقيقي
أنشأنا المقياس من خلال تنظيم مجموعة مهام ضمن مجموعة من مجالات تطوير Android الشائعة. ويتألف من تحديات حقيقية متفاوتة الصعوبة، تم استخلاصها من مستودعات GitHub العامة لتطبيقات Android. تشمل السيناريوهات حلّ التغييرات التي تؤدي إلى حدوث أعطال في إصدارات Android، والمهام الخاصة بالمجال، مثل إنشاء شبكة على الأجهزة القابلة للارتداء، والانتقال إلى أحدث إصدار من Jetpack Compose، على سبيل المثال لا الحصر.
تحاول كل عملية تقييم أن تجعل نموذجًا لغويًا كبيرًا يحلّ المشكلة التي تم الإبلاغ عنها في المهمة، ثم نتحقّق من ذلك باستخدام اختبارات الوحدات أو اختبارات الأجهزة. يسمح لنا هذا النهج المستقل عن النموذج بقياس قدرة النموذج على التنقّل في قواعد الرموز المعقدة، وفهم التبعيات، وحلّ نوع المشاكل التي تواجهها كل يوم.
تحقّقنا من صحة هذه المنهجية مع العديد من صنّاع النماذج اللغوية الكبيرة، بما في ذلك JetBrains.
“قياس تأثير الذكاء الاصطناعي على Android هو تحدٍ كبير، لذا من الرائع أن نرى إطارًا قويًا وواقعيًا كهذا. في حين أنّنا نعمل بنشاط على قياس أدائنا، فإنّ Android Bench هو إضافة فريدة ومرحب بها. هذه المنهجية هي بالضبط نوع التقييم الدقيق الذي يحتاجه مطوّرو Android الآن.”
- Kirill Smelov، رئيس عمليات دمج الذكاء الاصطناعي في JetBrains.
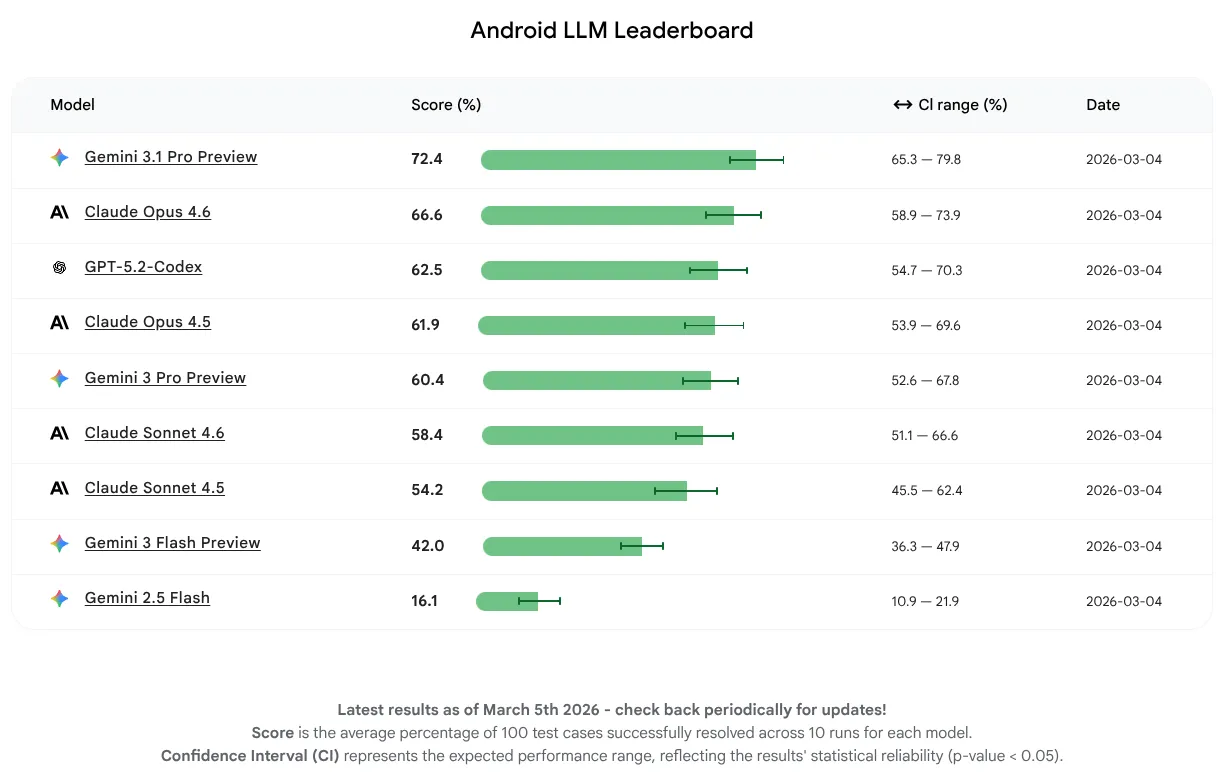
النتائج الأولى من Android Bench
أردنا في هذا الإصدار الأولي قياس أداء النموذج فقط وعدم التركيز على استخدام الوكيل أو الأدوات. تمكّنت النماذج من إكمال %16 إلى %72 من المهام بنجاح. هذا نطاق واسع يوضّح أنّ بعض النماذج اللغوية الكبيرة لديها أساس قوي بالفعل لمعرفة Android، بينما لدى البعض الآخر مجال أكبر للتحسين. بغض النظر عن مستوى النماذج الآن، نتوقّع تحسينًا مستمرًا لأنّنا نشجّع صنّاع النماذج اللغوية الكبيرة على تحسين نماذجهم لتطوير Android.
النموذج اللغوي الكبير الذي حصل على أعلى متوسّط نقاط في هذا الإصدار الأول هو Gemini 3.1 Pro، يليه مباشرةً Claude Opus 4.6. يمكنك تجربة جميع النماذج التي قيّمناها للحصول على المساعدة من الذكاء الاصطناعي في مشاريع Android باستخدام مفاتيح واجهة برمجة التطبيقات في أحدث إصدار ثابت من استوديو Android.
تزويد المطوّرين وصنّاع النماذج اللغوية الكبيرة بالشفافية
نقدّر النهج المفتوح والشفاف، لذا أتحنا منهجيتنا ومجموعة البيانات ومجموعة الاختبارات للجميع على GitHub.
أحد التحديات التي تواجه أي مقياس عام هو خطر تلوّث البيانات، حيث قد تكون النماذج قد اطّلعت على مهام التقييم أثناء عملية التدريب. اتّخذنا إجراءات لضمان أنّ نتائجنا تعكس الاستدلال الحقيقي بدلاً من الحفظ أو التخمين، بما في ذلك إجراء مراجعة يدوية شاملة لمسارات الوكيل، أو دمج سلسلة تحذير لمنع التدريب.
في المستقبل، سنواصل تطوير منهجيتنا للحفاظ على سلامة مجموعة البيانات، مع إجراء تحسينات أيضًا على الإصدارات المستقبلية من المقياس، على سبيل المثال، زيادة كمية المهام وتعقيدها.
نتطلّع إلى الطريقة التي يمكن أن يحسّن بها Android Bench المساعدة من الذكاء الاصطناعي على المدى الطويل. تتمثل رؤيتنا في سدّ الفجوة بين المفهوم والرمز البرمجي عالي الجودة. نحن نضع الأساس لمستقبل يمكنك فيه إنشاء أي شيء تتخيله على Android.
كتبه:
متابعة القراءة
-

أخبار المنتجات
أعلنّا اليوم خلال The Android Show أنّ Android ينتقل من نظام تشغيل إلى نظام ذكاء اصطناعي، ما يخلق المزيد من فرص التفاعل مع تطبيقاتك.
Matthew McCullough • قراءة لمدة 4 دقائق
-

أخبار المنتجات
نعمل اليوم على تحسين تطوير Android باستخدام Gemma 4، وهو أحدث نموذج مفتوح ومتطوّر تم تصميمه بإمكانات استدلال معقدة واستدعاء أدوات تلقائي.
Matthew McCullough • قراءة لمدة دقيقتَين
-

أخبار المنتجات
وصل Android 17 رسميًا إلى مرحلة ثبات النظام الأساسي اليوم مع الإصدار التجريبي 3. يعني ذلك أنّ واجهة برمجة التطبيقات ثابتة، ويمكنك إجراء اختبار التوافق النهائي ونشر تطبيقاتك التي تستهدف Android 17 على "متجر Play".
Matthew McCullough • قراءة لمدة 5 دقائق
البقاء على اطّلاع على آخر التحديثات
يمكنك تلقّي أحدث الإحصاءات حول تطوير Android في بريدك الوارد أسبوعيًا.
