

我們希望您能更快速輕鬆地建構優質 Android 應用程式,而其中一種方法就是提供 AI 輔助功能,協助您提升工作效率。我們瞭解您需要真正瞭解 Android 平台細微差異的 AI,因此我們一直在評估 LLM 執行 Android 開發工作的成效。我們今天推出了第一版 Android Bench,這是 Android 開發專用的官方 LLM 排行榜。
我們的目標是為模型建立者提供基準,以評估 LLM 在 Android 開發方面的能力。我們為優質 Android 開發作業建立明確可靠的基準,協助模型建立者找出缺口並加快改善速度,進而讓開發人員能更有效率地工作,並從更多實用模型中選擇 AI 輔助功能,最終在 Android 生態系統中打造更高品質的應用程式。
以實際的 Android 開發工作為設計依據
我們針對一系列常見的 Android 開發領域,精心挑選了一組工作,並以此建立基準。這些挑戰的難度各異,且皆來自公開的 GitHub Android 存放區。例如解決 Android 版本間的重大變更、處理特定領域的工作 (例如穿戴式裝置的網路連線),以及遷移至最新版 Jetpack Compose 等。
每次評估都會嘗試讓 LLM 修正工作回報的問題,然後我們使用單元或檢測設備測試進行驗證。這種與模型無關的方法可讓我們評估模型導覽複雜程式碼集、瞭解依附元件,以及解決您每天遇到的問題。
我們與 JetBrains 等多家 LLM 製作公司驗證了這項方法。
「評估 AI 對 Android 的影響是一項艱鉅的挑戰,因此我們很高興看到如此健全且實際的架構。我們積極進行基準測試,而 Android Bench 是一項獨特且值得歡迎的工具。這正是 Android 開發人員目前需要的嚴格評估方法。」
- JetBrains AI 整合部門主管 Kirill Smelov。
第一個 Android Bench 結果
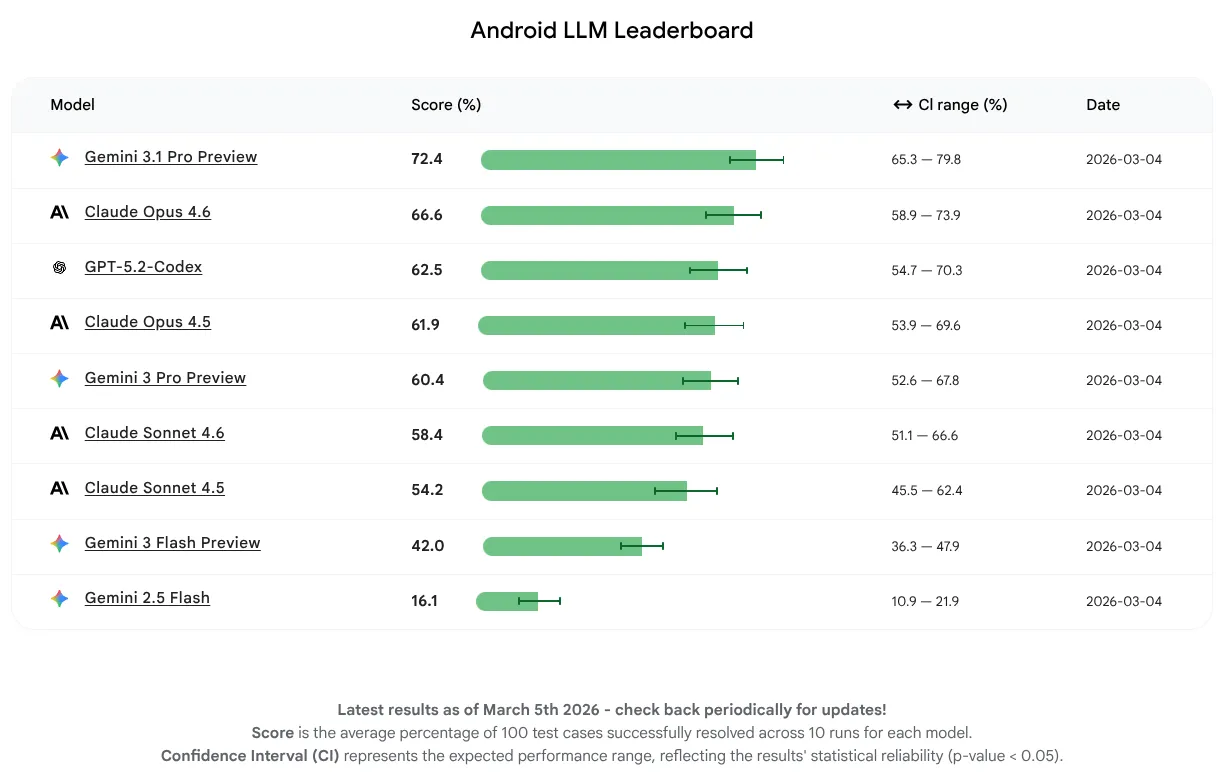
在這次的初步發布中,我們希望純粹評估模型效能,而非著重於代理或工具使用。模型能順利完成 16% 至 72% 的工作。這個範圍很廣,顯示部分大型語言模型已具備 Android 知識的強大基礎,其他模型則有更多進步空間。無論模型目前的狀態如何,我們都預期會持續改善,因為我們鼓勵 LLM 製作工具提升模型,以利 Android 開發作業。
在首發版本中,Gemini 3.1 Pro 的平均分數最高,緊隨其後的是 Claude Opus 4.6。在最新穩定版的 Android Studio 中使用 API 金鑰,即可試用我們評估的所有模型,為 Android 專案提供 AI 輔助功能。
向開發人員和 LLM 製作方提供透明度資訊
我們重視公開透明的做法,因此已在 GitHub 上公開我們的評估方法、資料集和測試架構。
任何公開基準的挑戰之一,就是資料汙染的風險,也就是模型在訓練過程中可能看過評估工作。我們已採取多項措施,確保結果反映的是真實推論,而非記憶或猜測,包括徹底手動審查代理路徑,或整合 Canary 字串來阻止訓練。
展望未來,我們將持續發展方法,確保資料集完整性,同時改善基準的後續版本,例如增加工作數量和複雜度。
我們期待 Android Bench 能長期提升 AI 輔助功能。我們的願景是縮短概念與優質程式碼之間的差距。我們正在為未來奠定基礎,讓您在 Android 上實現任何想像。
撰寫者:
繼續閱讀
-


產品新訊
在 2026 年的 Google I/O 大會上,我們為 Android 開發人員發布了 17 項重大公告,重點包括以代理程式為主的生產力、以 Compose First 做為 UI 標準,以及適用於擴大生態系統的高效能媒體和適應性開發。
Matthew McCullough • 閱讀時間:8 分鐘
-

產品新訊
在今天的 Android Show 中,我們宣布 Android 將從作業系統轉型為智慧系統,為您帶來更多應用程式互動商機。
Matthew McCullough • 4 分鐘可讀完
-

產品新訊
我們今天推出最新的先進開放式模型 Gemma 4,這款模型具備複雜的推論和自主工具呼叫功能,可提升 Android 開發體驗。
Matthew McCullough • 閱讀時間:2 分鐘
隨時掌握最新消息
每週透過電子郵件接收最新的 Android 開發洞察資料。
