
18% तेज़ी से कंपाइल होता है, परफ़ॉर्मेंस में कोई कमी नहीं आती
8 मिनट में पढ़ा जा सकता है

Android Runtime (ART) टीम ने कंपाइल होने में लगने वाले समय को 18% तक कम कर दिया है. हालांकि, इससे कंपाइल किए गए कोड या मेमोरी के इस्तेमाल पर कोई असर नहीं पड़ा है. यह सुधार, 2025 में शुरू की गई हमारी उस पहल का हिस्सा था जिसमें कंपाइल होने में लगने वाले समय को कम करने पर फ़ोकस किया गया था. इस पहल में, मेमोरी के इस्तेमाल या कंपाइल किए गए कोड की क्वालिटी से समझौता नहीं किया गया था.
ART के लिए, कंपाइल होने में लगने वाले समय को ऑप्टिमाइज़ करना ज़रूरी है. उदाहरण के लिए, जस्ट-इन-टाइम (जेआईटी) कंपाइलिंग से ऐप्लिकेशन की परफ़ॉर्मेंस और डिवाइस की परफ़ॉर्मेंस पर सीधा असर पड़ता है. तेज़ी से कंपाइल करने पर, ऑप्टिमाइज़ेशन लागू होने में कम समय लगता है. इससे, उपयोगकर्ता को बेहतर और ज़्यादा रिस्पॉन्सिव अनुभव मिलता है. इसके अलावा, जस्ट-इन-टाइम (जेआईटी) और ऐड-ऑफ-टाइम (एओटी) दोनों के लिए, कंपाइल करने में लगने वाले समय को कम करने से, कंपाइलेशन प्रोसेस के दौरान संसाधनों की खपत कम होती है. इससे बैटरी लाइफ़ और डिवाइस के तापमान को फ़ायदा मिलता है. खास तौर पर, कम सुविधाओं वाले डिवाइसों पर.
कंपाइल करने में लगने वाले समय को कम करने से जुड़े कुछ सुधार, Android के जून 2025 वाले वर्शन में लॉन्च किए गए थे. बाकी सुधार, Android के साल के आखिर में रिलीज़ होने वाले वर्शन में उपलब्ध होंगे. इसके अलावा, Android 12 और इसके बाद के वर्शन का इस्तेमाल करने वाले सभी लोग, मेनलाइन अपडेट के ज़रिए इन सुधारों को पा सकते हैं.
ऑप्टिमाइज़ करने वाले कंपाइलर को ऑप्टिमाइज़ करना
कंपाइलर को ऑप्टिमाइज़ करना हमेशा एक समझौता होता है. आपको स्पीड मुफ़्त में नहीं मिल सकती. इसके लिए, आपको कुछ त्याग करना होगा. हमने अपने लिए एक बहुत ही मुश्किल लक्ष्य तय किया है: कंपाइलर को तेज़ बनाना है, लेकिन ऐसा मेमोरी रिग्रेशन को शामिल किए बिना करना है. साथ ही, सबसे ज़रूरी बात यह है कि कंपाइलर से जनरेट होने वाले कोड की क्वालिटी को कम नहीं करना है. अगर कंपाइलर तेज़ है, लेकिन ऐप्लिकेशन धीरे चलते हैं, तो हम फ़ेल हो गए हैं.
हम सिर्फ़ एक संसाधन खर्च करना चाहते थे. वह था, डेवलपमेंट में लगने वाला समय. हम इस समय का इस्तेमाल, इन ज़रूरी शर्तों को पूरा करने वाले बेहतर समाधान ढूंढने के लिए करना चाहते थे. आइए, इस बारे में ज़्यादा जानें कि हम किन चीज़ों को बेहतर बनाने के लिए काम करते हैं. साथ ही, अलग-अलग समस्याओं के सही समाधान कैसे ढूंढते हैं.
काम के संभावित ऑप्टिमाइज़ेशन ढूंढना
किसी मेट्रिक को ऑप्टिमाइज़ करने से पहले, आपको उसे मेज़र करना होगा. ऐसा न करने पर, आपको कभी यह पता नहीं चलेगा कि आपने इसमें सुधार किया है या नहीं. हमारे लिए अच्छी बात यह है कि कंपाइल टाइम की स्पीड में ज़्यादा बदलाव नहीं होता. हालांकि, इसके लिए आपको कुछ सावधानियां बरतनी होंगी. जैसे, बदलाव से पहले और बाद में मेज़रमेंट के लिए एक ही डिवाइस का इस्तेमाल करना. साथ ही, यह पक्का करना कि आपके डिवाइस का तापमान ज़्यादा न हो. इसके अलावा, हमारे पास कंपाइलर के आंकड़ों जैसे डिटरमिनिस्टिक मेज़रमेंट भी होते हैं. इनसे हमें यह समझने में मदद मिलती है कि बैकग्राउंड में क्या हो रहा है.
इन सुधारों के लिए, हम डेवलपमेंट में लगने वाले समय को कम कर रहे थे. इसलिए, हम चाहते थे कि हम जितनी जल्दी हो सके उतनी जल्दी बदलाव कर पाएं. इसका मतलब है कि हमने कुछ ऐप्लिकेशन (पहले पक्ष के ऐप्लिकेशन, तीसरे पक्ष के ऐप्लिकेशन, और Android ऑपरेटिंग सिस्टम का मिक्स) को चुना, ताकि हम समाधानों का प्रोटोटाइप बना सकें. बाद में, हमने मैन्युअल और अपने-आप होने वाली टेस्टिंग की मदद से यह पुष्टि की कि फ़ाइनल तौर पर लागू किया गया बदलाव, काम का है.
चुने गए एपीके के उस सेट की मदद से, हम मैन्युअल तरीके से स्थानीय तौर पर कंपाइल करने की प्रोसेस शुरू करेंगे. इसके बाद, कंपाइलेशन की प्रोफ़ाइल पाएंगे. साथ ही, pprof का इस्तेमाल करके यह देखेंगे कि हम कहां समय बिता रहे हैं.
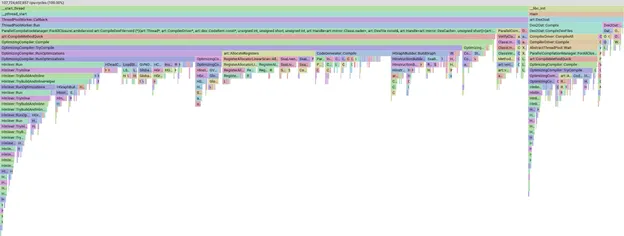
pprof में किसी प्रोफ़ाइल के फ़्लेम ग्राफ़ का उदाहरण
pprof टूल बहुत काम का है. इसकी मदद से, हम डेटा को स्लाइस, फ़िल्टर, और क्रम से लगा सकते हैं. उदाहरण के लिए, यह देखने के लिए कि कंपाइलर के किन फ़ेज़ या तरीकों में ज़्यादा समय लग रहा है. हम pprof के बारे में ज़्यादा जानकारी नहीं देंगे. बस यह जान लें कि अगर बार बड़ा है, तो इसका मतलब है कि कंपाइल होने में ज़्यादा समय लगा.
इनमें से एक व्यू “बॉटम अप” होता है. इसमें यह देखा जा सकता है कि कौनसे तरीके में सबसे ज़्यादा समय लग रहा है. नीचे दी गई इमेज में, हमें Kill नाम का एक तरीका दिख रहा है. इसमें कंपाइल होने में एक प्रतिशत से ज़्यादा समय लगता है. इस ब्लॉग पोस्ट में, अन्य लोकप्रिय तरीकों के बारे में भी बाद में बताया जाएगा.
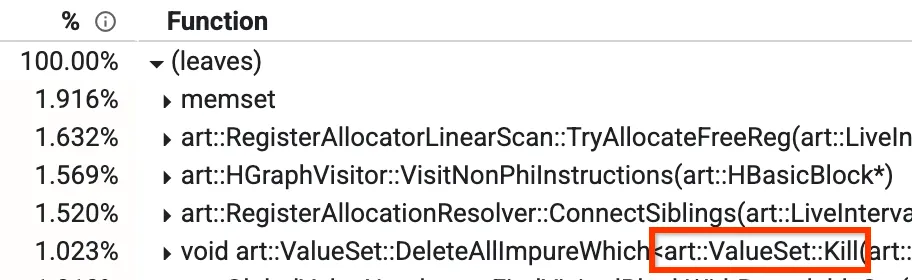
प्रोफ़ाइल का बॉटम अप व्यू
हमारे ऑप्टिमाइज़िंग कंपाइलर में, ग्लोबल वैल्यू नंबरिंग (जीवीएन) नाम का एक फ़ेज़ होता है. आपको इस बात की चिंता करने की ज़रूरत नहीं है कि यह पूरी तरह से क्या करता है. हालांकि, यह जानना ज़रूरी है कि इसमें `Kill` नाम का एक तरीका है. इसके तहत, यह फ़िल्टर के हिसाब से कुछ नोड मिटा देगा. इसमें समय लगता है, क्योंकि इसे सभी नोड पर जाकर एक-एक करके जांच करनी होती है. हमें पता चला है कि कुछ मामलों में, हमें पहले से ही पता होता है कि जांच में गड़बड़ी होगी. भले ही, उस समय हमारे पास कितने भी नोड चालू हों. ऐसे मामलों में, हम इटरेशन को पूरी तरह से छोड़ सकते हैं. इससे, जीवीएन के रनटाइम में ~15% की बढ़ोतरी होती है और यह 1.023% से घटकर ~0.3% हो जाता है.
काम के ऑप्टिमाइज़ेशन लागू करना
हमने यह बताया कि परफ़ॉर्मेंस को कैसे मेज़र किया जाए और यह कैसे पता लगाया जाए कि समय कहां खर्च हो रहा है. हालांकि, यह सिर्फ़ शुरुआत है. अगला चरण, कंपाइल करने में लगने वाले समय को ऑप्टिमाइज़ करने का तरीका है.
आम तौर पर, ऊपर दिए गए `Kill` जैसे मामले में, हम यह देखते हैं कि नोड को कैसे दोहराया जाता है. साथ ही, हम इसे तेज़ी से करने के लिए, उदाहरण के तौर पर, चीज़ों को पैरलल में करते हैं या एल्गोरिदम में सुधार करते हैं. दरअसल, हमने शुरुआत में यही तरीका आज़माया था. जब हमें कोई समाधान नहीं मिला, तब हमें लगा कि “एक मिनट रुको…” और हमने देखा कि कुछ मामलों में, समस्या को ठीक करने के लिए कुछ भी करने की ज़रूरत नहीं थी! इस तरह के ऑप्टिमाइज़ेशन करते समय, यह देखना ज़रूरी है कि आपके कैंपेन के लिए क्या सही है.
अन्य मामलों में, हमने कुछ अलग-अलग तकनीकों का इस्तेमाल किया. इनमें ये शामिल हैं:
- ह्यूरिस्टिक्स का इस्तेमाल करके यह तय करना कि क्या ऑप्टिमाइज़ेशन से काम के नतीजे नहीं मिलेंगे. इसलिए, इसे स्किप किया जा सकता है
- कंप्यूट किए गए डेटा को कैश मेमोरी में सेव करने के लिए, अतिरिक्त डेटा स्ट्रक्चर का इस्तेमाल करना
- डेटा को तेज़ी से प्रोसेस करने के लिए, मौजूदा डेटा स्ट्रक्चर में बदलाव करना
- कुछ मामलों में साइकल से बचने के लिए, नतीजों को धीरे-धीरे कंप्यूट करना
- सही ऐब्स्ट्रैक्शन का इस्तेमाल करें - गै़रज़रूरी सुविधाओं से कोड की स्पीड कम हो सकती है
- बार-बार इस्तेमाल किए जाने वाले पॉइंटर को कई लोड के ज़रिए ट्रैक करने से बचें
हमें कैसे पता चलेगा कि ऑप्टिमाइज़ेशन करना फ़ायदेमंद है या नहीं?
सबसे अच्छी बात यह है कि आपको ऐसा करने की ज़रूरत नहीं है. जब आपको पता चलता है कि किसी कोड को कंपाइल करने में बहुत ज़्यादा समय लग रहा है और उसे बेहतर बनाने के लिए डेवलपमेंट में काफ़ी समय लग चुका है, तो कभी-कभी आपको कोई समाधान नहीं मिल पाता. ऐसा हो सकता है कि कुछ भी न किया जा सके, लागू करने में बहुत समय लगे, इससे दूसरी मेट्रिक में काफ़ी गिरावट आए, कोड बेस की जटिलता बढ़ जाए वगैरह. इस ब्लॉग पोस्ट में आपको हर सफल ऑप्टिमाइज़ेशन के बारे में बताया गया है. हालांकि, ऐसे कई ऑप्टिमाइज़ेशन हैं जो सफल नहीं हुए.
अगर आपके साथ भी ऐसा ही हो रहा है, तो यह अनुमान लगाने की कोशिश करें कि कम से कम काम करके, मेट्रिक को कितना बेहतर बनाया जा सकता है. इसका मतलब है कि क्रम से:
- पहले से इकट्ठा की गई मेट्रिक के आधार पर अनुमान लगाना या सिर्फ़ अंदाज़ा लगाना
- तेज़ी से तैयार किए गए प्रोटोटाइप की मदद से अनुमान लगाना
- कोई समाधान लागू करें.
अपने समाधान की कमियों का अनुमान लगाना न भूलें. उदाहरण के लिए, अगर आपको अतिरिक्त डेटा स्ट्रक्चर पर भरोसा करना है, तो आपको कितनी मेमोरी का इस्तेमाल करना है?
ज़्यादा जानकारी
आइए, अब हम उन बदलावों के बारे में जानते हैं जिन्हें हमने लागू किया है.
हमने FindReferenceInfoOf नाम के तरीके को ऑप्टिमाइज़ करने के लिए बदलाव किया है. इस तरीके में, किसी एंट्री को खोजने के लिए वेक्टर की लीनियर सर्च की जा रही थी. हमने उस डेटा स्ट्रक्चर को अपडेट किया है, ताकि उसे निर्देश के आईडी के हिसाब से इंडेक्स किया जा सके. इससे FindReferenceInfoOf, O(n) के बजाय O(1) हो जाएगा. साथ ही, हमने वेक्टर को पहले से ही असाइन कर दिया है, ताकि उसका साइज़ न बदले. हमने मेमोरी को थोड़ा बढ़ा दिया है, क्योंकि हमें एक और फ़ील्ड जोड़ना था. इससे यह पता चलता है कि हमने वेक्टर में कितनी एंट्री डाली हैं. हालांकि, मेमोरी में ज़्यादा बढ़ोतरी नहीं हुई है, इसलिए यह एक छोटा सा बदलाव है. इससे LoadStoreAnalysis फ़ेज़ में 34 से 66% तक की तेज़ी आई. इससे कंपाइल होने में लगने वाले समय में ~0.5 से 1.8% तक की कमी आई.
हमारे पास HashSet का कस्टम वर्शन है, जिसका इस्तेमाल हम कई जगहों पर करते हैं. इस डेटा स्ट्रक्चर को बनाने में काफ़ी समय लग रहा था. हमें इसकी वजह पता चल गई है. कई साल पहले, इस डेटा स्ट्रक्चर का इस्तेमाल सिर्फ़ कुछ जगहों पर किया जाता था. ये ऐसी जगहें थीं जहां बहुत बड़े HashSets का इस्तेमाल किया जाता था. इसलिए, इसे उन जगहों के लिए ऑप्टिमाइज़ किया गया था. हालांकि, आजकल इसका इस्तेमाल उल्टी दिशा में किया जाता है. इसमें कुछ ही एंट्री होती हैं और यह कम समय के लिए होता है. इसका मतलब है कि हमने इस बड़े HashSet को बनाकर, साइकल बर्बाद किए. हालांकि, हमने इसका इस्तेमाल सिर्फ़ कुछ एंट्री के लिए किया और फिर इसे हटा दिया. इस बदलाव से, हमने कंपाइल होने में लगने वाले समय को ~1.3 से 2% तक कम किया है. इसके अलावा, मेमोरी का इस्तेमाल भी ~0.5-1% तक कम हो गया, क्योंकि अब हम पहले की तरह बड़े डेटा स्ट्रक्चर का इस्तेमाल नहीं कर रहे थे.
हमने कंपाइल होने में लगने वाले समय को ~0.5-1% तक कम किया है. इसके लिए, हमने लैम्ब्डा को डेटा स्ट्रक्चर को रेफ़रंस के तौर पर पास किया है, ताकि उन्हें कॉपी करने से बचा जा सके. यह एक ऐसी समस्या थी जो मूल समीक्षा में नहीं मिली थी और सालों तक हमारे कोडबेस में बनी रही. pprof में मौजूद प्रोफ़ाइलों को देखने के बाद, हमें पता चला कि ये तरीके कई डेटा स्ट्रक्चर बना रहे हैं और उन्हें मिटा रहे हैं. इसलिए, हमने इनकी जांच की और इन्हें ऑप्टिमाइज़ किया.
हमने कंपाइल किए गए आउटपुट को लिखने वाले फ़ेज़ की स्पीड बढ़ा दी है. इसके लिए, हमने कैलकुलेट की गई वैल्यू को कैश मेमोरी में सेव किया है. इससे कंपाइल करने में लगने वाले कुल समय में ~1.3 से 2.8% की कमी आई है. हालांकि, ज़्यादा बुककीपिंग की वजह से हमें काफ़ी परेशानी हुई. साथ ही, ऑटोमेटेड टेस्टिंग की वजह से हमें मेमोरी रिग्रेशन के बारे में सूचना मिली. बाद में, हमने उसी कोड की दोबारा जांच की और नया वर्शन लागू किया. इससे न सिर्फ़ मेमोरी रिग्रेशन की समस्या ठीक हुई, बल्कि कंपाइल होने में लगने वाला समय भी ~0.5-1.8% तक कम हो गया! दूसरे बदलाव में, हमें इस फ़ेज़ के काम करने के तरीके को फिर से तैयार करना पड़ा, ताकि दो डेटा स्ट्रक्चर में से एक को हटाया जा सके.
हमारे ऑप्टिमाइज़िंग कंपाइलर में एक फ़ेज़ होता है, जो बेहतर परफ़ॉर्मेंस पाने के लिए फ़ंक्शन कॉल को इनलाइन करता है. हम यह तय करने के लिए कि किन तरीकों को इनलाइन करना है, कंप्यूटेशन करने से पहले और काम पूरा करने के बाद, दोनों बार अनुमानित तरीकों का इस्तेमाल करते हैं. हालांकि, इनलाइन करने की प्रोसेस को फ़ाइनल करने से ठीक पहले, हम आखिरी बार जांच करते हैं. अगर इनमें से किसी भी तरीके से यह पता चलता है कि इनलाइन करने से फ़ायदा नहीं होगा (उदाहरण के लिए, बहुत सारे नए निर्देश जोड़े जाएंगे), तो हम तरीके को इनलाइन नहीं करते.
हमने दो जांचों को “फ़ाइनल जांच” कैटगरी से “अनुभव के आधार पर अनुमान लगाने वाली” कैटगरी में ट्रांसफ़र कर दिया है. इससे हमें यह अनुमान लगाने में मदद मिलती है कि इनलाइनिंग सफल होगी या नहीं. इससे पहले कि हम कोई भी समय लेने वाली गणना करें, हमें यह अनुमान लगाने में मदद मिलती है. यह अनुमान है, इसलिए यह पूरी तरह से सटीक नहीं है. हालांकि, हमने पुष्टि की है कि हमारे नए ह्यूरिस्टिक, परफ़ॉर्मेंस पर असर डाले बिना, पहले से इनलाइन किए गए 99.9% कॉन्टेंट को कवर करते हैं. इनमें से एक नई ह्यूरिस्टिक, ज़रूरी DEX रजिस्टर के बारे में थी. इससे ~0.2 से 1.3% का सुधार हुआ. दूसरी ह्यूरिस्टिक, निर्देशों की संख्या के बारे में थी. इससे ~2% का सुधार हुआ.
हमारे पास BitVector का कस्टम वर्शन है, जिसका इस्तेमाल हम कई जगहों पर करते हैं. हमने कुछ तय साइज़ वाले बिट वेक्टर के लिए, BitVectorView को BitVector क्लास से बदल दिया है. BitVectorView का साइज़ बदला जा सकता है. इससे कुछ इनडायरेक्शन और रन-टाइम रेंज की जांच खत्म हो जाती है. साथ ही, बिट वेक्टर ऑब्जेक्ट बनाने की प्रोसेस तेज़ हो जाती है.
इसके अलावा, BitVectorView क्लास को अंडरलाइंग स्टोरेज टाइप पर टेंप्लेट किया गया था. हालांकि, पुराने BitVector के तौर पर हमेशा uint32_t का इस्तेमाल किया जाता था. इससे कुछ कार्रवाइयां की जा सकती हैं. जैसे, Union() फ़ंक्शन का इस्तेमाल करके, 64-बिट प्लैटफ़ॉर्म पर एक साथ दो गुना बिट प्रोसेस की जा सकती हैं. Android OS को कंपाइल करते समय, असर डालने वाले फ़ंक्शन के सैंपल में कुल मिलाकर 1% से ज़्यादा की कमी आई. यह बदलाव कई बार किया गया है [1, 2, 3, 4, 5, 6]
अगर हम सभी ऑप्टिमाइज़ेशन के बारे में विस्तार से बात करें, तो हमें पूरा दिन लग जाएगा! अगर आपको कुछ और ऑप्टिमाइज़ेशन के बारे में जानना है, तो हमने जो अन्य बदलाव किए हैं उन्हें देखें:
- कंपाइलेशन में लगने वाले समय को ~0.6-1.6% तक कम करने के लिए, बुककीपिंग की सुविधा जोड़ें.
- अगर हो सके, तो साइकल से बचने के लिए डेटा को धीरे-धीरे प्रोसेस करें.
- हमारे कोड को रीफ़ैक्टर करें, ताकि जब प्रीकंप्यूटिंग का इस्तेमाल न किया जाए, तब उसे स्किप किया जा सके.
- जब ऐलोकेटर को अन्य जगहों से आसानी से हासिल किया जा सकता है, तब कुछ डिपेंडेंट लोड चेन से बचें.
- ज़रूरत से ज़्यादा काम से बचने के लिए, जांच जोड़ने का एक और उदाहरण.
- रजिस्टर ऐलोकेटर में, रजिस्टर टाइप (कोर/एफ़पी) पर बार-बार ब्रांचिंग से बचें.
- पक्का करें कि कंपाइल टाइम पर कुछ ऐरे शुरू किए गए हों. इसके लिए, clang पर भरोसा न करें.
- कुछ लूप हटाएं. रेंज लूप का इस्तेमाल करें, ताकि clang उन्हें बेहतर तरीके से ऑप्टिमाइज़ कर सके. ऐसा इसलिए, क्योंकि लूप के साइड इफ़ेक्ट की वजह से, इसे कंटेनर के इंटरनल पॉइंटर को फिर से लोड करने की ज़रूरत नहीं होती. हर इनपुट के लिए, इनलाइन किए गए `InputAt(.)` के ज़रिए लूप में वर्चुअल फ़ंक्शन `HInstruction::GetInputRecords()` को कॉल करने से बचें.
- विज़िटर पैटर्न के लिए, कंपाइलर ऑप्टिमाइज़ेशन का इस्तेमाल करके Accept() फ़ंक्शन से बचें.
नतीजा
हमारा मकसद, एआरटी की कंपाइल-टाइम स्पीड को बेहतर बनाना है. इसमें हमें काफ़ी सफलता मिली है. इससे Android ज़्यादा बेहतर और असरदार हो गया है. साथ ही, बैटरी लाइफ़ और डिवाइस के तापमान को बेहतर बनाने में भी मदद मिली है. हमने ऑप्टिमाइज़ेशन की पहचान करके उन्हें लागू किया है. इससे हमने यह दिखाया है कि मेमोरी के इस्तेमाल या कोड की क्वालिटी से समझौता किए बिना, कंपाइल होने में लगने वाले समय को कम किया जा सकता है.
इस प्रोसेस में, हमने pprof जैसे टूल का इस्तेमाल करके प्रोफ़ाइलिंग की. साथ ही, हमने बार-बार कोशिश की और कभी-कभी कम फ़ायदेमंद तरीकों को छोड़ भी दिया. एआरटी टीम के सामूहिक प्रयासों से, कंपाइल होने में लगने वाला समय काफ़ी कम हो गया है. साथ ही, इससे आने वाले समय में होने वाले सुधारों के लिए भी रास्ता खुल गया है.
ये सभी सुधार, साल 2025 के आखिर में Android के अपडेट में उपलब्ध होंगे. साथ ही, Android 12 और उसके बाद के वर्शन के लिए, ये मेनलाइन अपडेट के ज़रिए उपलब्ध होंगे. हमें उम्मीद है कि ऑप्टिमाइज़ेशन की हमारी प्रोसेस के बारे में ज़्यादा जानकारी देने से, आपको कंपाइलर इंजीनियरिंग की जटिलताओं और फ़ायदों के बारे में अहम जानकारी मिली होगी!
-

 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंGoogle Play पर, हम उपयोगकर्ताओं को सबसे अच्छा अनुभव देने के लिए प्रतिबद्ध हैं. साथ ही, हम यह भी पक्का करते हैं कि डेवलपर के पास सफल होने के लिए ज़रूरी टूल और अडैप्टेबिलिटी हो.
Paul Feng • तीन मिनट में पढ़ा जा सकता है -

 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंपिछले साल, हमने Android डेवलपर की पहचान की पुष्टि करने की सुविधा लॉन्च की थी. इससे, हमने अपने नेटवर्क की सुरक्षा को बेहतर बनाया था. साथ ही, बुरे मकसद से काम करने वाले लोगों या ग्रुप को नुकसान पहुंचाने वाले ऐप्लिकेशन रिलीज़ करने से रोका था. ये लोग अपनी पहचान छिपाकर ऐसा करते थे.
Matthew Forsythe • दो मिनट में पढ़ें -


 प्रॉडक्ट से जुड़ी खबरें
प्रॉडक्ट से जुड़ी खबरेंऑगमेंटेड ओवरले से लेकर पूरी तरह से इमर्सिव एनवायरमेंट तक, Android XR का इकोसिस्टम तेज़ी से बढ़ रहा है. Samsung Galaxy XR, आज से ही उपलब्ध है.
Stevan Silva, Vinny DaSilva • तीन मिनट में पढ़ा जा सकता है
Android डेवलपमेंट से जुड़ी नई अहम जानकारी, हर हफ़्ते अपने इनबॉक्स में पाएं.
