


ทีม Android Runtime (ART) ได้ลดเวลาคอมไพล์ลง 18% โดยไม่กระทบต่อโค้ดที่คอมไพล์หรือการถดถอยของหน่วยความจำสูงสุด การปรับปรุงนี้เป็นส่วนหนึ่งของโครงการริเริ่มปี 2025 ของเราในการปรับปรุงเวลาคอมไพล์โดยไม่กระทบต่อการใช้งานหน่วยความจำหรือคุณภาพของโค้ดที่คอมไพล์
การเพิ่มประสิทธิภาพความเร็วในการคอมไพล์เป็นสิ่งสำคัญสำหรับ ART เช่น เมื่อคอมไพล์แบบทันที (JIT) จะส่งผลต่อประสิทธิภาพของแอปพลิเคชันและประสิทธิภาพโดยรวมของอุปกรณ์โดยตรง การคอมไพล์ที่เร็วขึ้นจะช่วยลดเวลาก่อนที่การเพิ่มประสิทธิภาพจะเริ่มทำงาน ซึ่งจะส่งผลให้ผู้ใช้ได้รับประสบการณ์การใช้งานที่ราบรื่นและตอบสนองได้ดียิ่งขึ้น นอกจากนี้ สำหรับทั้ง JIT และ AOT การปรับปรุงความเร็วในการคอมไพล์จะช่วยลดการใช้ทรัพยากรในระหว่างกระบวนการคอมไพล์ ซึ่งจะช่วยยืดอายุการใช้งานแบตเตอรี่และลดความร้อนของอุปกรณ์ โดยเฉพาะในอุปกรณ์ระดับล่าง
การปรับปรุงความเร็วในการคอมไพล์บางส่วนเปิดตัวใน Android เวอร์ชันเดือนมิถุนายน 2025 และส่วนที่เหลือจะพร้อมใช้งานใน Android เวอร์ชันสิ้นปี นอกจากนี้ ผู้ใช้ Android ทุกคนในเวอร์ชัน 12 ขึ้นไปจะมีสิทธิ์รับการปรับปรุงเหล่านี้ผ่านการอัปเดต Mainline
การเพิ่มประสิทธิภาพคอมไพเลอร์ที่เพิ่มประสิทธิภาพ
การเพิ่มประสิทธิภาพคอมไพเลอร์มักเป็นการแลกเปลี่ยนเสมอ คุณไม่สามารถรับความเร็วได้ฟรีๆ แต่ต้องยอมเสียสละบางอย่าง เราตั้งเป้าหมายที่ชัดเจนและท้าทายไว้ว่า จะทำให้คอมไพเลอร์เร็วขึ้น แต่ต้องไม่ทำให้เกิดการถดถอยของหน่วยความจำ และที่สำคัญคือต้องไม่ลดคุณภาพของโค้ดที่สร้างขึ้น หากคอมไพเลอร์เร็วขึ้นแต่แอปทำงานช้าลง เราก็ถือว่าล้มเหลว
แหล่งข้อมูลเดียวที่เรายินดีที่จะใช้คือเวลาในการพัฒนาของเราเองเพื่อเจาะลึก ตรวจสอบ และค้นหาโซลูชันที่ชาญฉลาดซึ่งตรงตามเกณฑ์ที่เข้มงวดเหล่านี้ มาดูรายละเอียดวิธีที่เราใช้ค้นหาจุดที่ควรปรับปรุง รวมถึงค้นหาวิธีแก้ปัญหาที่เหมาะสมสำหรับปัญหาต่างๆ
ค้นหาการเพิ่มประสิทธิภาพที่เป็นไปได้ซึ่งคุ้มค่า
ก่อนที่จะเริ่มเพิ่มประสิทธิภาพเมตริกได้ คุณต้องวัดเมตริกนั้นได้ก่อน มิฉะนั้น คุณจะไม่มีทางรู้ว่าได้ปรับปรุงแล้วหรือไม่ โชคดีที่ความเร็วในการคอมไพล์ค่อนข้างสม่ำเสมอ ตราบใดที่คุณใช้ความระมัดระวังบางอย่าง เช่น ใช้อุปกรณ์เครื่องเดียวกันในการวัดก่อนและหลังการเปลี่ยนแปลง และตรวจสอบว่าอุปกรณ์ไม่ได้ระบายความร้อน นอกจากนี้ เรายังมีการวัดผลแบบดีเทอร์มินิสติก เช่น สถิติคอมไพเลอร์ ซึ่งช่วยให้เราเข้าใจสิ่งที่เกิดขึ้นเบื้องหลัง
เนื่องจากทรัพยากรที่เราเสียไปเพื่อการปรับปรุงเหล่านี้คือเวลาในการพัฒนา เราจึงต้องการที่จะทำซ้ำให้ได้เร็วที่สุด ซึ่งหมายความว่าเราได้เลือกแอปตัวแทนจำนวนหนึ่ง (ทั้งแอปของบุคคลที่หนึ่ง แอปของบุคคลที่สาม และระบบปฏิบัติการ Android เอง) เพื่อสร้างต้นแบบโซลูชัน ต่อมาเราได้ยืนยันว่าการติดตั้งใช้งานขั้นสุดท้ายนั้นคุ้มค่าด้วยการทดสอบทั้งแบบด้วยตนเองและแบบอัตโนมัติในวงกว้าง
เมื่อมีชุด APK ที่คัดสรรมาแล้ว เราจะทริกเกอร์การคอมไพล์ด้วยตนเองในเครื่อง รับโปรไฟล์ของการคอมไพล์ และใช้ pprof เพื่อแสดงภาพว่าเราใช้เวลาไปกับส่วนใด
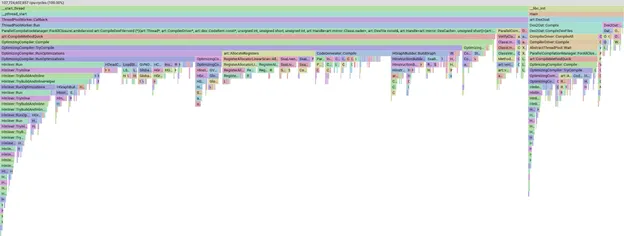
ตัวอย่างกราฟ Flame ของโปรไฟล์ใน pprof
เครื่องมือ pprof มีประสิทธิภาพมากและช่วยให้เราแบ่ง กรอง และจัดเรียงข้อมูลเพื่อดูได้ เช่น เฟสหรือเมธอดของคอมไพเลอร์ที่ใช้เวลานานที่สุด เราจะไม่ลงรายละเอียดเกี่ยวกับ pprof เพียงแต่ให้ทราบว่าหากแถบมีขนาดใหญ่ขึ้น แสดงว่าใช้เวลาในการคอมไพล์นานขึ้น
มุมมองหนึ่งคือมุมมอง "จากล่างขึ้นบน" ซึ่งคุณจะเห็นว่าวิธีใดใช้เวลานานที่สุด ในรูปภาพด้านล่าง เราจะเห็นเมธอดที่ชื่อว่า Kill ซึ่งคิดเป็นเวลาคอมไพล์มากกว่า 1% นอกจากนี้ เราจะพูดถึงวิธีอื่นๆ ที่ได้รับความนิยมในบล็อกโพสต์ในภายหลัง
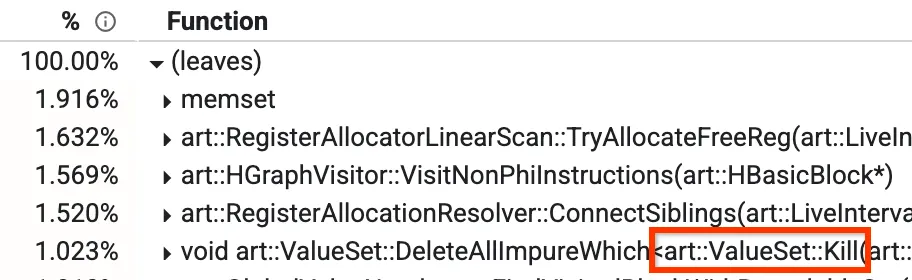
มุมมองจากล่างขึ้นบนของโปรไฟล์
ในคอมไพเลอร์การเพิ่มประสิทธิภาพของเรามีเฟสที่เรียกว่าการกำหนดหมายเลขค่าส่วนกลาง (GVN) คุณไม่ต้องกังวลว่าฟังก์ชันนี้จะทำอะไรโดยรวม แต่ส่วนที่เกี่ยวข้องคือการทราบว่าฟังก์ชันนี้มีเมธอดชื่อ `Kill` ซึ่งจะลบบางโหนดตามตัวกรอง ซึ่งใช้เวลานานเนื่องจากต้องวนซ้ำผ่านโหนดทั้งหมดและตรวจสอบทีละรายการ เราพบว่ามีบางกรณีที่เรารู้ล่วงหน้าว่าการตรวจสอบจะเป็นเท็จ ไม่ว่าเราจะมีโหนดที่ใช้งานได้ในขณะนั้นก็ตาม ในกรณีเช่นนี้ เราสามารถข้ามการทำซ้ำไปเลย ซึ่งจะช่วยลดอัตราการเกิดข้อผิดพลาดจาก 1.023% ลงมาเหลือประมาณ 0.3% และปรับปรุงเวลาทำงานของ GVN ได้ประมาณ 15%
การเพิ่มประสิทธิภาพที่คุ้มค่า
เราได้พูดถึงวิธีวัดและวิธีตรวจหาว่ามีการใช้เวลาไปกับอะไรบ้าง แต่ทั้งหมดนี้เป็นเพียงจุดเริ่มต้นเท่านั้น ขั้นตอนถัดไปคือวิธีเพิ่มประสิทธิภาพเวลาที่ใช้ในการคอมไพล์
โดยปกติแล้ว ในกรณีเช่น `Kill` ด้านบน เราจะดูวิธีวนซ้ำผ่านโหนดและทำให้เร็วขึ้น เช่น ทำสิ่งต่างๆ แบบขนานหรือปรับปรุงอัลกอริทึมเอง อันที่จริงแล้ว เราได้ลองทำแบบนั้นในตอนแรก และเมื่อไม่พบวิธีแก้ปัญหา เราก็ฉุกคิดขึ้นมาได้ว่าวิธีแก้ปัญหาคือการไม่ทำซ้ำเลย (ในบางกรณี) เมื่อทำการเพิ่มประสิทธิภาพประเภทนี้ คุณอาจมองข้ามภาพรวมไปได้ง่ายๆ
ในกรณีอื่นๆ เราใช้เทคนิคที่แตกต่างกัน 2-3 อย่าง ซึ่งรวมถึง
- ใช้ฮิวริสติกเพื่อตัดสินว่าการเพิ่มประสิทธิภาพจะให้ผลลัพธ์ที่คุ้มค่าหรือไม่ จึงข้ามได้
- การใช้โครงสร้างข้อมูลเพิ่มเติมเพื่อแคชข้อมูลที่คำนวณแล้ว
- เปลี่ยนโครงสร้างข้อมูลปัจจุบันเพื่อเพิ่มความเร็ว
- คำนวณผลลัพธ์แบบเลื่อนเวลาเพื่อหลีกเลี่ยงการวนซ้ำในบางกรณี
- ใช้การแยกส่วนที่เหมาะสม - ฟีเจอร์ที่ไม่จำเป็นอาจทำให้โค้ดทำงานช้าลง
- หลีกเลี่ยงการติดตามพอยน์เตอร์ที่ใช้บ่อยผ่านการโหลดหลายครั้ง
เราจะทราบได้อย่างไรว่าการเพิ่มประสิทธิภาพคุ้มค่าที่จะทำหรือไม่
คุณไม่ต้องทำอะไรเลย หลังจากตรวจพบว่าพื้นที่หนึ่งใช้เวลาคอมไพล์มาก และหลังจากใช้เวลาในการพัฒนาเพื่อพยายามปรับปรุงแล้ว บางครั้งคุณก็อาจไม่พบวิธีแก้ปัญหา อาจไม่มีอะไรต้องทำ ใช้เวลานานเกินไปในการติดตั้งใช้งาน ทำให้ตัวชี้วัดอื่นลดลงอย่างมาก เพิ่มความซับซ้อนของฐานของโค้ด ฯลฯ สำหรับการเพิ่มประสิทธิภาพที่ประสบความสำเร็จทุกครั้งที่คุณเห็นในบล็อกโพสต์นี้ โปรดทราบว่ายังมีอีกมากมายที่ไม่ได้ผล
หากคุณอยู่ในสถานการณ์ที่คล้ายกัน ให้ลองประมาณว่าคุณจะปรับปรุงเมตริกได้มากน้อยเพียงใดโดยทำงานให้น้อยที่สุด ซึ่งหมายความว่า
- การประมาณโดยใช้เมตริกที่คุณรวบรวมไว้แล้ว หรือเพียงแค่ความรู้สึก
- การประมาณด้วยต้นแบบแบบคร่าวๆ
- ใช้โซลูชัน
อย่าลืมพิจารณาการประเมินข้อเสียของโซลูชัน เช่น หากคุณจะใช้โครงสร้างข้อมูลเพิ่มเติม คุณยินดีที่จะใช้หน่วยความจำเท่าใด
เจาะลึก
มาดูการเปลี่ยนแปลงบางอย่างที่เราได้ดำเนินการกันเลย
เราได้ทำการเปลี่ยนแปลงเพื่อเพิ่มประสิทธิภาพเมธอดที่ชื่อ FindReferenceInfoOf วิธีนี้จะค้นหาแบบเชิงเส้นของเวกเตอร์เพื่อหารายการ เราได้อัปเดตโครงสร้างข้อมูลดังกล่าวเพื่อให้ระบบจัดทำดัชนีตามรหัสของคำสั่ง เพื่อให้ FindReferenceInfoOf เป็น O(1) แทนที่จะเป็น O(n) นอกจากนี้ เรายังจัดสรรเวกเตอร์ล่วงหน้าเพื่อหลีกเลี่ยงการปรับขนาด เราเพิ่มหน่วยความจำเล็กน้อยเนื่องจากต้องเพิ่มฟิลด์พิเศษที่นับจำนวนรายการที่เราแทรกในเวกเตอร์ แต่ก็เป็นการแลกเปลี่ยนที่คุ้มค่าเนื่องจากหน่วยความจำสูงสุดไม่ได้เพิ่มขึ้น ซึ่งช่วยเร่งระยะ LoadStoreAnalysis ได้ 34-66% และช่วยปรับปรุงเวลาในการคอมไพล์ได้ประมาณ 0.5-1.8%
เรามีการใช้งาน HashSet ที่กำหนดเองซึ่งเราใช้ในหลายที่ การสร้างโครงสร้างข้อมูลนี้ใช้เวลานานพอสมควรและเราพบสาเหตุแล้ว เมื่อหลายปีก่อน โครงสร้างข้อมูลนี้ใช้ในไม่กี่ที่ที่ใช้ HashSet ขนาดใหญ่มาก และได้รับการปรับแต่งให้เหมาะกับกรณีนั้น แต่ปัจจุบันมีการใช้ในทิศทางตรงกันข้าม โดยมีรายการเพียงไม่กี่รายการและมีอายุการใช้งานสั้น ซึ่งหมายความว่าเราเสียรอบการทำงานไปโดยเปล่าประโยชน์จากการสร้าง HashSet ขนาดใหญ่ แต่เราใช้เพียงไม่กี่รายการก่อนที่จะทิ้ง การเปลี่ยนแปลงนี้ช่วยให้เราปรับปรุงเวลาคอมไพล์ได้ประมาณ 1.3-2% นอกจากนี้ การใช้งานหน่วยความจำยังลดลงประมาณ 0.5-1% เนื่องจากเราไม่ได้ใช้โครงสร้างข้อมูลขนาดใหญ่เท่าเมื่อก่อน
เราปรับปรุงเวลาคอมไพล์ประมาณ 0.5-1% โดยส่งโครงสร้างข้อมูลตามการอ้างอิงไปยัง Lambda เพื่อหลีกเลี่ยงการคัดลอก เรามองข้ามเรื่องนี้ไปในการตรวจสอบครั้งแรกและปล่อยให้เรื่องนี้อยู่ในโค้ดเบสของเรามาหลายปี การดูโปรไฟล์ใน pprof ทำให้เราสังเกตเห็นว่าเมธอดเหล่านี้สร้างและทำลายโครงสร้างข้อมูลจำนวนมาก ซึ่งนำไปสู่การตรวจสอบและเพิ่มประสิทธิภาพ
เราเร่งระยะที่เขียนเอาต์พุตที่คอมไพล์แล้วด้วยการแคชค่าที่คำนวณแล้ว ซึ่งส่งผลให้เวลาในการคอมไพล์ทั้งหมดดีขึ้นประมาณ 1.3-2.8% แต่การทำบัญชีเพิ่มเติมนั้นมากเกินไป และการทดสอบอัตโนมัติของเราได้แจ้งเตือนเราถึงการถดถอยของหน่วยความจำ ต่อมาเราได้ตรวจสอบโค้ดเดิมอีกครั้งและใช้เวอร์ชันใหม่ ซึ่งไม่เพียงแต่แก้ไขการถดถอยของหน่วยความจำ แต่ยังปรับปรุงเวลาในการคอมไพล์ได้อีกประมาณ 0.5-1.8% ในการเปลี่ยนแปลงครั้งที่ 2 นี้ เราต้องปรับโครงสร้างและจินตนาการใหม่ว่าระยะนี้ควรทำงานอย่างไร เพื่อกำจัดโครงสร้างข้อมูล 1 ใน 2 โครงสร้าง
เรามีเฟสในคอมไพเลอร์การเพิ่มประสิทธิภาพซึ่งจะแทรกฟังก์ชันคอลเพื่อเพิ่มประสิทธิภาพ เราใช้ทั้งฮิวริสติกก่อนทำการคำนวณ และการตรวจสอบขั้นสุดท้ายหลังจากทำงานเสร็จแต่ก่อนที่จะสรุปการแทรกในบรรทัด เพื่อเลือกวิธีการที่จะแทรกในบรรทัด หากตรวจพบว่าการแทรกโค้ดไม่คุ้มค่า (เช่น จะมีการเพิ่มคำสั่งใหม่มากเกินไป) เราจะไม่แทรกโค้ดการเรียกใช้เมธอด
เราย้ายการตรวจสอบ 2 รายการจากหมวดหมู่ "การตรวจสอบขั้นสุดท้าย" ไปยังหมวดหมู่ "ฮิวริสติก" เพื่อประเมินว่าการแทรกอินไลน์จะสำเร็จหรือไม่ก่อนที่จะทำการคำนวณที่ใช้เวลานาน เนื่องจากนี่เป็นการประมาณค่า จึงอาจไม่ถูกต้อง 100% แต่เราได้ยืนยันแล้วว่าฮิวริสติกใหม่ของเราครอบคลุม 99.9% ของสิ่งที่ฝังไว้ก่อนหน้านี้โดยไม่ส่งผลต่อประสิทธิภาพ ฮิวริสติกใหม่เหล่านี้อย่างหนึ่งคือเรื่องรีจิสเตอร์ DEX ที่จำเป็น (ปรับปรุงขึ้นประมาณ 0.2-1.3%) และอีกอย่างคือเรื่องจำนวนคำสั่ง (ปรับปรุงขึ้นประมาณ 2%)
เรามีการใช้งาน BitVector ที่กำหนดเองซึ่งเราใช้ในหลายที่ เราได้แทนที่คลาส BitVector ที่ปรับขนาดได้ด้วย BitVectorView ที่ง่ายกว่าสำหรับเวกเตอร์บิตขนาดคงที่บางรายการ ซึ่งจะช่วยลดการอ้อมค้อมบางอย่างและการตรวจสอบช่วงรันไทม์ รวมถึงเร่งการสร้างออบเจ็กต์บิตเวกเตอร์
นอกจากนี้ คลาส BitVectorView ยังได้รับการสร้างเทมเพลตในประเภทพื้นที่เก็บข้อมูลพื้นฐาน (แทนที่จะใช้ uint32_t เสมอเหมือน BitVector เก่า) ซึ่งช่วยให้การดำเนินการบางอย่าง เช่น Union() ประมวลผลบิตได้พร้อมกันเป็น 2 เท่าในแพลตฟอร์ม 64 บิต ตัวอย่างของฟังก์ชันที่ได้รับผลกระทบจะลดลงมากกว่า 1% โดยรวมเมื่อคอมไพล์ระบบปฏิบัติการ Android การดำเนินการนี้เกิดขึ้นจากการเปลี่ยนแปลงหลายอย่าง [1, 2, 3, 4, 5, 6]
หากเราพูดถึงการเพิ่มประสิทธิภาพทั้งหมดโดยละเอียด เราคงต้องอยู่ที่นี่ทั้งวัน หากสนใจการเพิ่มประสิทธิภาพเพิ่มเติม โปรดดูการเปลี่ยนแปลงอื่นๆ ที่เราได้ดำเนินการ
- เพิ่มการบันทึกบัญชีเพื่อปรับปรุงเวลาในการคอมไพล์ประมาณ 0.6-1.6%
- คำนวณข้อมูลแบบเลื่อนเวลาเพื่อหลีกเลี่ยงวงจร หากเป็นไปได้
- ปรับโครงสร้างโค้ดเพื่อข้ามงานการคำนวณล่วงหน้าเมื่อไม่ได้ใช้งาน
- หลีกเลี่ยงการโหลดเชนที่ขึ้นต่อกันเมื่อรับตัวจัดสรรจากที่อื่นได้ง่ายๆ
- อีกกรณีหนึ่งของการเพิ่มการตรวจสอบเพื่อหลีกเลี่ยงงานที่ไม่จำเป็น
- หลีกเลี่ยงการแยกสาขาบ่อยๆ ในประเภทรีจิสเตอร์ (core/FP) ในตัวจัดสรรรีจิสเตอร์
- ตรวจสอบว่ามีการเริ่มต้นอาร์เรย์บางรายการในเวลาคอมไพล์ อย่าใช้ clang ในการดำเนินการนี้
- ล้างข้อมูลลูปบางรายการ ใช้ลูปช่วงที่ Clang เพิ่มประสิทธิภาพได้ดีกว่าเนื่องจากไม่จำเป็นต้องโหลดพอยน์เตอร์ภายในของคอนเทนเนอร์ซ้ำเนื่องจากผลข้างเคียงของลูป หลีกเลี่ยงการเรียกใช้ฟังก์ชันเสมือน `HInstruction::GetInputRecords()` ในลูปผ่าน `InputAt(.)` แบบอินไลน์สำหรับอินพุตแต่ละรายการ
- หลีกเลี่ยงฟังก์ชัน Accept() สำหรับรูปแบบผู้เข้าชมโดยใช้ประโยชน์จากการเพิ่มประสิทธิภาพคอมไพเลอร์
บทสรุป
ความมุ่งมั่นของเราในการปรับปรุงความเร็วในการคอมไพล์ของ ART ทำให้เกิดการปรับปรุงอย่างมีนัยสำคัญ ซึ่งช่วยให้ Android ทำงานได้ราบรื่นและมีประสิทธิภาพมากขึ้น รวมถึงช่วยให้แบตเตอรี่ใช้งานได้นานขึ้นและอุปกรณ์ระบายความร้อนได้ดีขึ้นด้วย การระบุและการเพิ่มประสิทธิภาพอย่างขยันขันแข็งแสดงให้เห็นว่าการเพิ่มประสิทธิภาพในเวลาคอมไพล์อย่างมากเป็นไปได้โดยไม่กระทบต่อการใช้งานหน่วยความจำหรือคุณภาพของโค้ด
เส้นทางของเราเกี่ยวข้องกับการสร้างโปรไฟล์ด้วยเครื่องมือต่างๆ เช่น pprof ความเต็มใจที่จะทำซ้ำ และบางครั้งก็ต้องละทิ้งแนวทางที่ให้ผลลัพธ์น้อยกว่า ความพยายามร่วมกันของทีม ART ไม่เพียงแต่ลดเวลาคอมไพล์ลงได้เป็นเปอร์เซ็นต์ที่น่าสังเกตเท่านั้น แต่ยังเป็นการวางรากฐานสำหรับการพัฒนาในอนาคตอีกด้วย
การปรับปรุงทั้งหมดนี้พร้อมใช้งานในการอัปเดต Android ช่วงสิ้นปี 2025 และสำหรับ Android 12 ขึ้นไปผ่านการอัปเดต Mainline เราหวังว่าการเจาะลึกกระบวนการเพิ่มประสิทธิภาพนี้จะให้ข้อมูลเชิงลึกที่มีคุณค่าเกี่ยวกับความซับซ้อนและผลตอบแทนของการทำงานด้านวิศวกรรมคอมไพเลอร์
เขียนโดย
อ่านต่อ
-


ข่าวสารผลิตภัณฑ์
เราที่ Google Play มุ่งมั่นที่จะมอบประสบการณ์การใช้งานที่ดีที่สุดแก่ผู้ใช้ พร้อมทั้งดูแลให้นักพัฒนาแอปมีเครื่องมือและความสามารถในการปรับตัวเพื่อประสบความสำเร็จ
Paul Feng • ใช้เวลาอ่าน 3 นาที
-


ข่าวสารผลิตภัณฑ์
เมื่อปีที่แล้ว เราได้เปิดตัวการยืนยันนักพัฒนาแอป Android เพื่อเสริมความแข็งแกร่งด้านความปลอดภัยของระบบนิเวศและหยุดไม่ให้ผู้ไม่ประสงค์ดีซ่อนตัวอยู่เบื้องหลังการไม่เปิดเผยตัวตนเพื่อเผยแพร่แอปที่เป็นอันตราย
Matthew Forsythe • ใช้เวลาอ่าน 2 นาที
-



ข่าวสารผลิตภัณฑ์
ตั้งแต่การซ้อนทับแบบเสริมไปจนถึงสภาพแวดล้อมที่สมจริงอย่างเต็มรูปแบบ ระบบนิเวศ Android XR กำลังขยายตัวอย่างรวดเร็ว โดย Samsung Galaxy XR พร้อมให้บริการแล้ววันนี้
Stevan Silva, Vinny DaSilva • ใช้เวลาอ่าน 3 นาที
รับข่าวสาร
รับข้อมูลเชิงลึกด้านการพัฒนาแอป Android ล่าสุดส่งตรงถึงกล่องจดหมายของคุณทุกสัปดาห์
