


لقد قلّل فريق وقت تشغيل Android (ART) وقت التجميع بنسبة% 18 بدون التأثير في الرمز المُجمَّع أو أيّ حالات تراجع في الحد الأقصى للذاكرة. كان هذا التحسين جزءًا من مبادرتنا لعام 2025 لتحسين وقت التجميع بدون التأثير في استخدام الذاكرة أو جودة الرمز المُجمَّع.
يُعدّ تحسين سرعة وقت التجميع أمرًا بالغ الأهمية في ART. على سبيل المثال، عند تجميع الرمز في الوقت المناسب (JIT)، يؤثر ذلك بشكل مباشر في كفاءة التطبيقات وأداء الجهاز بشكل عام. تؤدي عمليات التجميع الأسرع إلى تقليل الوقت قبل بدء التحسينات، ما يؤدي إلى تجربة مستخدم أكثر سلاسة واستجابة. علاوةً على ذلك، بالنسبة إلى كل من JIT وAOT (التجميع المسبق)، تؤدي التحسينات في سرعة وقت التجميع إلى تقليل استهلاك الموارد أثناء عملية التجميع، ما يفيد عمر البطارية ودرجة حرارة الجهاز، لا سيما على الأجهزة المنخفضة المستوى.
تم إطلاق بعض هذه التحسينات في سرعة وقت التجميع في إصدار Android لشهر يونيو 2025، وستتوفّر البقية في إصدار نهاية العام من Android. علاوةً على ذلك، يكون جميع مستخدمي Android الذين يستخدمون الإصدارات 12 والإصدارات الأحدث مؤهّلين لتلقّي هذه التحسينات من خلال التحديثات الرئيسية.
تحسين المحسِّن المُحسِّن
يُعدّ تحسين المحسِّن دائمًا لعبة مقايضات. لا يمكنك الحصول على السرعة مجانًا، بل عليك التنازل عن شيء ما. لقد وضعنا لأنفسنا هدفًا واضحًا وصعبًا للغاية: جعل المحسِّن أسرع، ولكن بدون إدخال حالات تراجع في الذاكرة، والأهم من ذلك، بدون تقليل جودة الرمز الذي ينتجه. إذا كان المحسِّن أسرع ولكن التطبيقات تعمل بشكل أبطأ، فهذا يعني أنّنا فشلنا.
المورد الوحيد الذي كنّا على استعداد لإنفاقه هو وقت التطوير الخاص بنا للبحث بعمق والتحقيق والعثور على حلول ذكية تفي بهذه المعايير الصارمة. لنلقِ نظرة فاحصة على طريقة عملنا للعثور على مجالات التحسين، بالإضافة إلى إيجاد الحلول المناسبة للمشاكل المختلفة.
العثور على التحسينات المحتمَلة القيّمة
قبل أن تتمكّن من البدء في تحسين مقياس، يجب أن تكون قادرًا على قياسه. وإلا، لن تتمكّن من التأكّد من تحسينه أم لا. لحسن حظنا، تكون سرعة وقت التجميع متّسقة إلى حد ما طالما أنّك تتّخذ بعض الاحتياطات، مثل استخدام الجهاز نفسه الذي تستخدمه للقياس قبل وبعد إجراء تغيير، والتأكّد من عدم حدوث انخفاض في أداء جهازك بسبب ارتفاع درجة الحرارة. بالإضافة إلى ذلك، لدينا أيضًا قياسات محدّدة، مثل إحصاءات المحسِّن التي تساعدنا في فهم ما يحدث تحت الغطاء.
بما أنّ المورد الذي كنّا نضحّي به من أجل هذه التحسينات هو وقت التطوير، أردنا أن نتمكّن من إجراء التكرار بأسرع ما يمكن. وهذا يعني أنّنا اخترنا مجموعة من التطبيقات التمثيلية (مزيج من تطبيقات الطرف الأول وتطبيقات الطرف الثالث ونظام التشغيل Android نفسه) لإنشاء نماذج أولية للحلول. في وقت لاحق، تحقّقنا من أنّ التنفيذ النهائي كان يستحق ذلك من خلال الاختبار اليدوي والآلي على نطاق واسع.
باستخدام مجموعة ملفات APK التي تم اختيارها بعناية، كنّا نُشغّل عملية تجميع يدوية محليًا، ونحصل على ملف شخصي لعملية التجميع، ونستخدم pprof لتصوّر الأماكن التي نقضي فيها وقتنا.
مثال على الرسم البياني الناري لملف شخصي في pprof
أداة pprof فعّالة جدًا وتسمح لنا بتقسيم البيانات وتصفيتها وفرزها لمعرفة، على سبيل المثال، مراحل المحسِّن أو الطرق التي تستغرق معظم الوقت. لن نتناول بالتفصيل أداة pprof نفسها، ولكن يكفي أن تعرف أنّه إذا كان الشريط أكبر، فهذا يعني أنّه استغرق وقتًا أطول في عملية التجميع.
أحد هذه العروض هو العرض "من أسفل إلى أعلى" الذي يمكنك من خلاله معرفة الطرق التي تستغرق معظم الوقت. في الصورة أدناه، يمكننا رؤية طريقة تُسمى Kill، تمثّل أكثر من% 1 من وقت التجميع. ستتم أيضًا مناقشة بعض الطرق الرئيسية الأخرى لاحقًا في مشاركة المدونة.
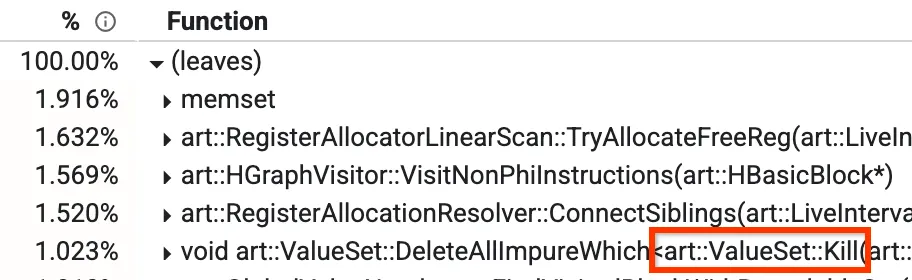
عرض "من أسفل إلى أعلى" لملف شخصي
في المحسِّن المُحسِّن، هناك مرحلة تُسمى Global Value Numbering (GVN). ليس عليك القلق بشأن ما تفعله بشكل عام، ولكن الجزء ذو الصلة هو معرفة أنّها تتضمّن طريقة تُسمى `Kill` ستحذف بعض العُقد وفقًا لفلتر. يستغرق ذلك وقتًا طويلاً لأنّه يجب تكرار جميع العُقد والتحقّق منها واحدةً تلو الأخرى. لاحظنا أنّ هناك بعض الحالات التي نعرف فيها مسبقًا أنّ عملية التحقّق ستكون غير صحيحة، بغض النظر عن العُقد التي لدينا نشطة في تلك المرحلة. في هذه الحالات، يمكننا تخطّي التكرار تمامًا، ما يؤدي إلى خفض النسبة من% 1.023 إلى% 0.3 تقريبًا وتحسين وقت تشغيل GVN بنسبة %15 تقريبًا.
تنفيذ التحسينات القيّمة
لقد تناولنا كيفية القياس وكيفية رصد الوقت الذي يتم إنفاقه، ولكن هذه مجرد البداية. الخطوة التالية هي كيفية تحسين الوقت الذي يتم إنفاقه في التجميع.
في العادة، في حالة مثل حالة `Kill` أعلاه، كنّا نلقي نظرة على كيفية تكرار العُقد وننفّذ ذلك بشكل أسرع، على سبيل المثال، من خلال تنفيذ الإجراءات بالتوازي أو تحسين الخوارزمية نفسها. في الواقع، هذا ما جرّبناه في البداية، ولم ندرك أنّ الحل هو عدم التكرار على الإطلاق (في بعض الحالات) إلا عندما لم نتمكّن من العثور على أي شيء آخر يمكننا فعله. عند إجراء هذا النوع من التحسينات، من السهل عدم رؤية الصورة الكبيرة.
في حالات أخرى، استخدمنا مجموعة من التقنيات المختلفة، بما في ذلك:
- استخدام الإرشادات التجريبية لتحديد ما إذا كان التحسين لن يؤدي إلى نتائج قيّمة وبالتالي يمكن تخطّيه
- استخدام بُنى بيانات إضافية لتخزين البيانات المحسوبة مؤقتًا
- تغيير بُنى البيانات الحالية للحصول على زيادة في السرعة
- حساب النتائج بشكل غير فوري لتجنُّب الدورات في بعض الحالات
- استخدام التجريد المناسب: يمكن أن تؤدي الميزات غير الضرورية إلى إبطاء الرمز
- تجنُّب تتبُّع مؤشر مستخدَم بشكل متكرر من خلال العديد من عمليات التحميل
كيف نعرف ما إذا كانت التحسينات تستحق المتابعة؟
هذا هو الجزء الأنيق، لا يمكنك معرفة ذلك. بعد رصد أنّ أحد المجالات يستهلك الكثير من وقت التجميع وبعد تخصيص وقت التطوير لمحاولة تحسينه، قد لا تتمكّن في بعض الأحيان من العثور على حل. ربما ليس هناك ما يمكن فعله، أو سيستغرق التنفيذ وقتًا طويلاً جدًا، أو سيؤدي إلى تراجع مقياس آخر بشكل كبير، أو زيادة تعقيد قاعدة الرموز، وما إلى ذلك. مقابل كل تحسين ناجح يمكنك رؤيته في مشاركة المدونة هذه، اعلم أنّ هناك عددًا لا يُحصى من التحسينات الأخرى التي لم تتحقق.
إذا كنت في موقف مشابه، حاوِل تقدير مقدار تحسين المقياس من خلال بذل أقل قدر ممكن من العمل. وهذا يعني، بالترتيب:
- التقدير باستخدام المقاييس التي سبق لك جمعها، أو مجرد شعور داخلي
- التقدير باستخدام نموذج أولي سريع وغير دقيق
- تنفيذ حل
لا تنسَ تقدير عيوب الحل. على سبيل المثال، إذا كنت ستعتمد على بُنى بيانات إضافية، فما مقدار الذاكرة التي أنت على استعداد لاستخدامها؟
نظرة مفصَّلة
بدون مقدمات، لنلقِ نظرة على بعض التغييرات التي نفّذناها.
لقد نفّذنا تغييرًا لتحسين طريقة تُسمى FindReferenceInfoOf. كانت هذه الطريقة تجري بحثًا خطيًا عن متّجه للعثور على إدخال. لقد عدّلنا بنية البيانات هذه لتتم فهرستها حسب رقم تعريف التعليمات، بحيث تكون FindReferenceInfoOf هي O(1) بدلاً من O(n). أيضًا، خصّصنا المتّجه مسبقًا لتجنُّب تغيير حجمه. لقد زدنا الذاكرة قليلاً لأنّه كان علينا إضافة حقل إضافي يحسب عدد الإدخالات التي أدرجناها في المتّجه، ولكن كان هذا تضحية صغيرة لأنّ الحد الأقصى للذاكرة لم يزد. أدى ذلك إلى تسريع مرحلة LoadStoreAnalysis بنسبة تتراوح بين %34 و%66، ما يؤدي بدوره إلى تحسين وقت التجميع بنسبة تتراوح بين %0.5 و%1.8 تقريبًا.
لدينا تنفيذ مخصّص لـ HashSet نستخدمه في عدة أماكن. كان إنشاء بنية البيانات هذه يستغرق وقتًا طويلاً، وقد اكتشفنا السبب. قبل سنوات عديدة، كانت بنية البيانات هذه تُستخدم في عدد قليل فقط من الأماكن التي كانت تستخدم HashSets كبيرة جدًا، وتم تعديلها لتحسينها من أجل ذلك. ومع ذلك، كانت تُستخدم في الوقت الحالي في الاتجاه المعاكس مع عدد قليل فقط من الإدخالات وعمر قصير. وهذا يعني أنّنا كنّا نضيّع الدورات من خلال إنشاء HashSet كبير جدًا، ولكننا كنّا نستخدمه لعدد قليل فقط من الإدخالات قبل تجاهله. من خلال هذا التغيير، حسّنّا وقت التجميع بنسبة تتراوح بين %1.3 و%2 تقريبًا. كميزة إضافية، انخفض استخدام الذاكرة بنسبة تتراوح بين %0.5 و%1 تقريبًا لأنّنا لم نكن نستخدم بُنى بيانات كبيرة كما كان من قبل.
لقد حسّنّا وقت التجميع بنسبة تتراوح بين %0.5 و%1 تقريبًا من خلال تمرير بُنى البيانات حسب المرجع إلى الدالة lambda لتجنُّب نسخها. كان هذا شيئًا لم يتم ملاحظته في المراجعة الأصلية وبقي في قاعدة الرموز لسنوات. بفضل إلقاء نظرة على الملفات الشخصية في pprof، لاحظنا أنّ هذه الطرق كانت تنشئ وتدمّر الكثير من بُنى البيانات، ما دفعنا إلى التحقيق فيها وتحسينها.
لقد سرّعنا المرحلة التي تكتب الناتج المُجمَّع من خلال تخزين القيم المحسوبة مؤقتًا، ما أدّى إلى تحسين وقت التجميع الإجمالي بنسبة تتراوح بين %1.3 و%2.8 تقريبًا. للأسف، كانت عملية تسجيل البيانات الإضافية كبيرة جدًا، ونبّهتنا الاختبارات الآلية إلى تراجع الذاكرة. في وقت لاحق، ألقينا نظرة ثانية على الرمز نفسه ونفّذنا إصدارًا جديدًا لم يعالج تراجع الذاكرة فحسب، بل حسّن أيضًا وقت التجميع بنسبة تتراوح بين %0.5 و%1.8 إضافية تقريبًا. في هذا التغيير الثاني، كان علينا إعادة تصميم طريقة عمل هذه المرحلة وإعادة تخيّلها للتخلّص من إحدى بُنيتَي البيانات.
لدينا مرحلة في المحسِّن المُحسِّن تدمج استدعاءات الدوال للحصول على أداء أفضل. لاختيار الطرق التي سيتم دمجها، نستخدم كلاً من الإرشادات التجريبية قبل إجراء أي عملية حسابية، وعمليات التحقّق النهائية بعد إجراء العمل ولكن قبل الانتهاء من عملية الدمج مباشرةً. إذا رصد أي من هذه العمليات أنّ عملية الدمج لا تستحق ذلك (على سبيل المثال، ستتم إضافة عدد كبير جدًا من التعليمات الجديدة)، فلن ندمج طلب الإجراء.
نقلنا عمليتَي تحقّق من فئة "عمليات التحقّق النهائية" إلى فئة "الإرشادات التجريبية" لتقدير ما إذا كانت عملية الدمج ستنجح أم لا قبل إجراء أي عملية حسابية تستغرق وقتًا طويلاً. بما أنّ هذا تقدير، فهو ليس مثاليًا، ولكن تحقّقنا من أنّ إرشاداتنا التجريبية الجديدة تغطي% 99.9 من المحتوى الذي تم دمجه من قبل بدون التأثير في الأداء. كانت إحدى هذه الإرشادات التجريبية الجديدة حول سجلّات DEX المطلوبة (تحسين بنسبة تتراوح بين %0.2 و%1.3 تقريبًا)، والأخرى حول عدد التعليمات (تحسين بنسبة %2 تقريبًا).
لدينا تنفيذ مخصّص لـ BitVector نستخدمه في عدة أماكن. استبدلنا فئة BitVector القابلة لتغيير الحجم بـ BitVectorView أبسط لبعض متجهات البت ذات الحجم الثابت. يؤدي ذلك إلى إزالة بعض عمليات التوجيه غير المباشر وعمليات التحقّق من النطاق في وقت التشغيل، ويسرّع عملية إنشاء كائنات متجهات البت.
علاوةً على ذلك، تم إنشاء فئة BitVectorView كنموذج لنوع التخزين الأساسي (بدلاً من استخدام uint32_t دائمًا كـ BitVector القديم). يسمح ذلك لبعض العمليات، مثل Union()، بمعالجة ضعف عدد البتات معًا على الأنظمة الأساسية 64 بت. انخفضت عيّنات الدوال المتأثرة بأكثر من% 1 إجمالاً عند تجميع نظام التشغيل Android. تم إجراء ذلك من خلال عدة تغييرات [1, 2, 3, 4, 5, 6]
إذا تحدّثنا بالتفصيل عن جميع التحسينات، فسنبقى هنا طوال اليوم. إذا كنت مهتمًا ببعض التحسينات الإضافية، يمكنك إلقاء نظرة على بعض التغييرات الأخرى التي نفّذناها:
- إضافة تسجيل البيانات لتحسين أوقات التجميع بنسبة تتراوح بين %0.6 و%1.6 تقريبًا
- حساب البيانات بشكل غير فوري لتجنُّب الدورات، إن أمكن.
- إعادة تصميم الرمز لتخطّي عملية الحساب المسبق للعمل عندما لن يتم استخدامه
- تجنُّب بعض سلاسل التحميل التابعة عندما يمكن الحصول على أداة تخصيص الذاكرة بسهولة من أماكن أخرى
- حالة أخرى لإضافة عملية تحقّق لتجنُّب العمل غير الضروري.
- تجنُّب التفرّع المتكرر على نوع السجل (أساسي/FP) في أداة تخصيص السجل
- التأكّد من تهيئة بعض الصفائف في وقت التجميع لا تعتمد على clang لإجراء ذلك.
- تنظيف بعض الحلقات. استخدام حلقات النطاق التي يمكن أن يحسّنها clang بشكل أفضل لأنّه لا يحتاج إلى إعادة تحميل المؤشرات الداخلية للحاوية بسبب الآثار الجانبية للحلقة تجنُّب استدعاء الدالة الافتراضية `HInstruction::GetInputRecords()` في الحلقة من خلال `InputAt(.)` المُضمَّنة لكل إدخال
- تجنُّب دوال Accept() لنمط الزائر من خلال استغلال تحسين المحسِّن
الخاتمة
لقد أدّى تفانينا في تحسين سرعة وقت التجميع في ART إلى تحقيق تحسينات كبيرة، ما جعل Android أكثر سلاسة وكفاءة، مع المساهمة أيضًا في تحسين عمر البطارية ودرجة حرارة الجهاز. من خلال تحديد التحسينات وتنفيذها بعناية، أثبتنا أنّه من الممكن تحقيق مكاسب كبيرة في وقت التجميع بدون التأثير في استخدام الذاكرة أو جودة الرمز.
تضمّنت رحلتنا إنشاء ملفات شخصية باستخدام أدوات مثل pprof، والاستعداد للتكرار، وأحيانًا حتى التخلي عن الطرق الأقل جدوى. لم تؤدِّ الجهود الجماعية لفريق ART إلى تقليل وقت التجميع بنسبة ملحوظة فحسب، بل وضعت أيضًا الأساس للتحسينات المستقبلية.
تتوفّر كل هذه التحسينات في تحديث نهاية العام من Android لعام 2025، ولإصدار Android 12 والإصدارات الأحدث من خلال التحديثات الرئيسية. نأمل أن يقدّم هذا التحليل المتعمّق لعملية التحسين إحصاءات قيّمة حول تعقيدات هندسة المحسِّن ومكافآتها.
تأليف:
متابعة القراءة
-


أخبار المنتجات
أعلنّا اليوم خلال The Android Show أنّ Android ينتقل من نظام تشغيل إلى نظام ذكاء اصطناعي، ما يخلق المزيد من فرص التفاعل مع تطبيقاتك.
Matthew McCullough • مدّة القراءة: 4 دقائق
-


أخبار المنتجات
تتطوّر المنظومة المتكاملة للأجهزة الجوّالة باستمرار، ما يؤدي إلى ظهور فرص وتهديدات جديدة. من خلال هذه التغييرات، يظلّ Android وGoogle Play ملتزمَين بضمان استمرار مليارات المستخدمين في الاستمتاع بتطبيقاتهم بثقة وازدهار ابتكارات المطوّرين.
Vijaya Kaza • مدّة القراءة: 3 دقائق
-


أخبار المنتجات
إصدار أبريل 2026 من Jetpack Compose مستقر. يتضمّن هذا الإصدار الإصدار 1.11 من وحدات Compose الأساسية (راجِع عملية الربط الكاملة لقائمة إدارة حزم البرامج)، وأدوات تصحيح الأخطاء للعناصر المشتركة، وأحداث لوحة التتبّع، والمزيد.
Meghan Mehta • مدّة القراءة: 5 دقائق
البقاء على اطّلاع على آخر التحديثات
يمكنك تلقّي أحدث الإحصاءات حول تطوير Android في بريدك الوارد أسبوعيًا.
