
In che modo l'ottimizzazione automatica dei prompt migliora la qualità dell'API Prompt di AI generativa di ML Kit
3 minuti di lettura
Ottimizzazione automatica dei prompt (APO)
Per aiutarti a portare in produzione i casi d'uso dell'API Prompt di ML Kit, siamo felici di annunciare l'ottimizzazione automatica dei prompt (APO) per i modelli on-device su Vertex AI. L'ottimizzazione automatica dei prompt è uno strumento che ti aiuta a trovare automaticamente il prompt ottimale per i tuoi casi d'uso.
L'era dell'AI on-device non è più una promessa, ma una realtà di produzione. Con il rilascio di Gemini Nano v3, mettiamo nelle mani degli utenti funzionalità di comprensione del linguaggio e multimodali senza precedenti. Grazie alla famiglia di modelli Gemini Nano, abbiamo un'ampia copertura dei dispositivi supportati nell'ecosistema Android. Tuttavia, per gli sviluppatori che creano la prossima generazione di app intelligenti, l'accesso a un modello potente è solo il primo passo. La vera sfida è la personalizzazione: come si adatta un foundation model a prestazioni di livello esperto per il tuo caso d'uso specifico senza violare i vincoli dell'hardware mobile?
Nel mondo lato server, i modelli linguistici di grandi dimensioni tendono a essere altamente capaci e richiedono meno adattamento al dominio. Anche quando è necessario, le opzioni più avanzate come l'ottimizzazione di LoRA (Low-Rank Adaptation) possono essere opzioni fattibili. Tuttavia, l'architettura unica di Android AICore dà la priorità a un modello di sistema condiviso ed efficiente in termini di memoria. Ciò significa che il deployment di adattatori LoRA personalizzati per ogni singola app comporta delle sfide per questi servizi di sistema condivisi.
Esiste però un percorso alternativo che può essere altrettanto efficace. Sfruttando l'ottimizzazione automatica dei prompt (APO) su Vertex AI, gli sviluppatori possono ottenere una qualità simile all'ottimizzazione, il tutto lavorando senza problemi nell'ambiente di esecuzione Android nativo. Concentrandosi su istruzioni di sistema di qualità superiore, APO consente agli sviluppatori di personalizzare il comportamento del modello con maggiore robustezza e scalabilità rispetto alle soluzioni di ottimizzazione tradizionali.
Nota: Gemini Nano v3 è una versione con qualità ottimizzata del modello Gemma 3N, molto apprezzato. Qualsiasi ottimizzazione dei prompt apportata al modello Gemma 3N open source verrà applicata anche a Gemini Nano v3. Sui dispositivi supportati, le API di AI generativa di ML Kit sfruttano il modello nano-v3 per massimizzare la qualità per gli sviluppatori Android.
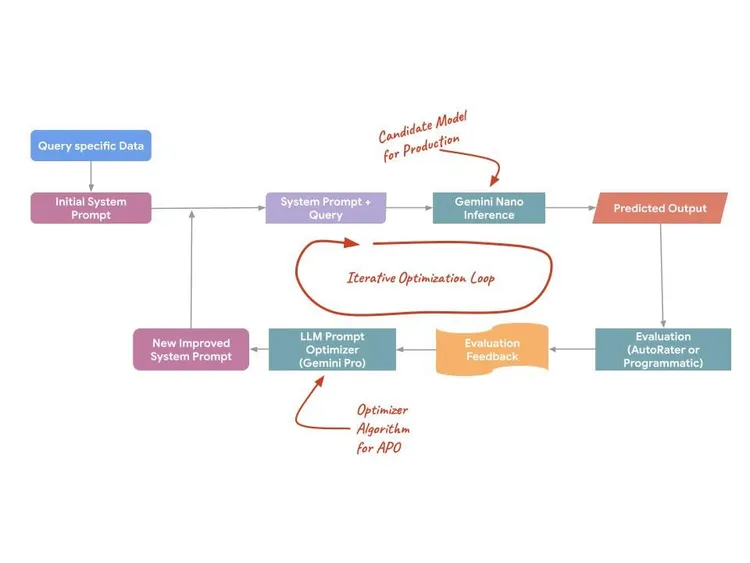
APO tratta il prompt non come un testo statico, ma come una superficie programmabile che può essere ottimizzata. Sfrutta i modelli lato server (come Gemini Pro e Flash) per proporre prompt, valutare le varianti e trovare quella ottimale per la tua attività specifica. Questo processo utilizza tre meccanismi tecnici specifici per massimizzare le prestazioni:
- Analisi automatica degli errori: APO analizza i pattern di errore dei dati di addestramento per identificare automaticamente le debolezze specifiche nel prompt iniziale.
- Distillazione semantica delle istruzioni: analizza enormi esempi di addestramento per distillare il "vero intento" di un'attività, creando istruzioni che riflettono in modo più accurato la distribuzione reale dei dati.
- Test parallelo dei candidati: anziché testare un'idea alla volta, APO genera e testa in parallelo numerosi prompt candidati per identificare il massimo globale per la qualità.
Perché APO può avvicinarsi alla qualità dell'ottimizzazione
È un errore comune pensare che l'ottimizzazione produca sempre una qualità migliore rispetto ai prompt. Per i modelli di base moderni come Gemini Nano v3, l'ingegneria dei prompt può essere efficace di per sé:
- Preservare le funzionalità generali: l'ottimizzazione ( PEFT/LoRA) forza i pesi di un modello a indicizzare eccessivamente una distribuzione specifica dei dati. Questo spesso porta a una "dimenticanza catastrofica", in cui il modello migliora la sintassi specifica, ma peggiora la logica generale e la sicurezza. APO lascia i pesi invariati, preservando le funzionalità del modello di base.
- Seguire le istruzioni e scoprire le strategie: Gemini Nano v3 è stato addestrato rigorosamente per seguire istruzioni di sistema complesse. APO sfrutta questa funzionalità trovando la struttura di istruzioni esatta che sblocca le funzionalità latenti del modello, spesso scoprendo strategie che potrebbero essere difficili da trovare per gli ingegneri umani.
Per convalidare questo approccio, abbiamo valutato APO in diversi carichi di lavoro di produzione. La nostra convalida ha mostrato miglioramenti costanti dell'accuratezza del 5-8% in vari casi d'uso.In più funzionalità on-device implementate, APO ha fornito miglioramenti significativi della qualità.
| Use Case | Tipo di attività | Descrizione dell'attività | Metrica | Miglioramento APO |
| Classificazione degli argomenti | Classificazione del testo | Classifica un articolo di notizie in argomenti come finanza, sport e così via | Accuratezza | +5% |
| Classificazione degli intent | Classificazione del testo | Classifica una query del servizio clienti in intent | Accuratezza | +8,0% |
| Traduzione di pagine web | Traduzione del testo | Traduci una pagina web dall'inglese a una lingua locale | BLEU | +8,57% |
Un flusso di lavoro di sviluppo end-to-end senza interruzioni
È un errore comune pensare che l'ottimizzazione produca sempre una qualità migliore rispetto ai prompt. Per i modelli di base moderni come Gemini Nano v3, l'ingegneria dei prompt può essere efficace di per sé:
- Preservare le funzionalità generali: l'ottimizzazione ( PEFT/LoRA) forza i pesi di un modello a indicizzare eccessivamente una distribuzione specifica dei dati. Questo spesso porta a una "dimenticanza catastrofica", in cui il modello migliora la sintassi specifica, ma peggiora la logica generale e la sicurezza. APO lascia i pesi invariati, preservando le funzionalità del modello di base.
- Seguire le istruzioni e scoprire le strategie: Gemini Nano v3 è stato addestrato rigorosamente per seguire istruzioni di sistema complesse. APO sfrutta questa funzionalità trovando la struttura di istruzioni esatta che sblocca le funzionalità latenti del modello, spesso scoprendo strategie che potrebbero essere difficili da trovare per gli ingegneri umani.
Per convalidare questo approccio, abbiamo valutato APO in diversi carichi di lavoro di produzione. La nostra convalida ha mostrato miglioramenti costanti dell'accuratezza del 5-8% in vari casi d'uso.In più funzionalità on-device implementate, APO ha fornito miglioramenti significativi della qualità.
Conclusione
Il rilascio dell'ottimizzazione automatica dei prompt (APO) segna un punto di svolta per l'AI generativa on-device. Colmando il divario tra i modelli di base e le prestazioni di livello esperto, offriamo agli sviluppatori gli strumenti per creare applicazioni mobile più robuste. Che tu stia iniziando a utilizzare l'ottimizzazione zero-shot o che tu stia scalando la produzione con il perfezionamento basato sui dati, il percorso verso l'intelligenza on-device di alta qualità è ora più chiaro. Inizia oggi stesso a utilizzare i casi d'uso on-device in produzione con l'API Prompt di ML Kit e l'ottimizzazione automatica dei prompt di Vertex AI.
Link pertinenti:



-


 Novità sui prodotti
Novità sui prodottiIn Google, ci impegniamo a portare i modelli di AI più capaci direttamente sui dispositivi Android che hai in tasca. Oggi siamo felici di annunciare il rilascio del nostro ultimo modello open allo stato dell'arte: Gemma 4.
Caren Chang, David Chou • 3 minuti di lettura -
 Novità sui prodotti
Novità sui prodottiL'AI semplifica la creazione di esperienze app personalizzate che trasformano i contenuti nel formato giusto per gli utenti. In precedenza, abbiamo consentito agli sviluppatori di eseguire l'integrazione con Gemini Nano tramite le API di AI generativa di ML Kit, progettate per casi d'uso specifici come il riepilogo e la descrizione delle immagini.
Caren Chang, Chengji Yan, Penny Li • 2 minuti di lettura -

 Novità sui prodotti
Novità sui prodottiFornire un'esperienza online sicura e proteggere gli utenti da danni è una priorità assoluta su Google Play.
Paul Feng • 2 minuti di lettura
Ricevi ogni settimana nella tua casella di posta le ultime informazioni sullo sviluppo di Android.
