
Actualités des produits
Dans les coulisses : MessageQueue sans verrouillage d'Android 17
Temps de lecture : 16 min

Dans Android 17, les applications ciblant le SDK 37 ou une version ultérieure recevront une nouvelle implémentation de MessageQueue, qui sera sans verrouillage. La nouvelle implémentation améliore les performances et réduit le nombre d'images manquées, mais peut casser les clients qui réfléchissent aux champs et méthodes privés de MessageQueue. Pour en savoir plus sur ce changement de comportement et sur la façon d'en atténuer l'impact, consultez la documentation sur le changement de comportement de MessageQueue. Cet article de blog technique présente la nouvelle architecture de MessageQueue et explique comment analyser les problèmes de contention de verrou à l'aide de Perfetto.
Le Looper pilote le thread UI de chaque application Android. Il extrait le travail d'une MessageQueue, le distribue à un Handler et se répète. Pendant deux décennies, MessageQueue a utilisé un seul verrouillage de moniteur (c'est-à-dire un bloc de code synchronized) pour protéger son état.
Android 17 introduit une mise à jour importante de ce composant : une implémentation sans verrouillage nommée DeliQueue.
Cet article explique comment les verrous affectent les performances de l'UI, comment analyser ces problèmes avec Perfetto, ainsi que les algorithmes et optimisations spécifiques utilisés pour améliorer le thread principal d'Android.
Problème : conflit de verrouillage et inversion de priorité
L'ancienne fonction MessageQueue servait de file d'attente prioritaire protégée par un seul verrou. Si un thread en arrière-plan publie un message pendant que le thread principal effectue la maintenance de la file d'attente, le thread en arrière-plan bloque le thread principal.
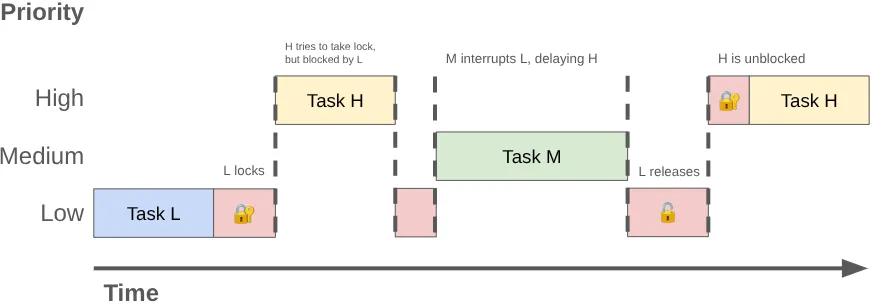
Lorsque deux threads ou plus sont en concurrence pour l'utilisation exclusive du même verrou, on parle de concurrence de verrouillage. Cette contention peut entraîner une inversion de priorité, ce qui peut provoquer des à-coups dans l'interface utilisateur et d'autres problèmes de performances.
L'inversion de priorité peut se produire lorsqu'un thread de haute priorité (comme le thread UI) est mis en attente d'un thread de basse priorité. Prenons l'exemple suivant :
- Un thread d'arrière-plan de faible priorité acquiert le verrou
MessageQueuepour publier le résultat du travail qu'il a effectué. - Un thread de priorité moyenne devient exécutable et le planificateur du noyau lui alloue du temps de processeur, en préemptant le thread de priorité faible.
- Le thread d'UI haute priorité termine sa tâche actuelle et tente de lire la file d'attente, mais il est bloqué, car le thread basse priorité détient le verrou.
Le thread à faible priorité bloque le thread UI, et le travail à priorité moyenne le retarde davantage.
Analyser les conflits avec Perfetto
Vous pouvez diagnostiquer ces problèmes à l'aide de Perfetto. Dans une trace standard, un thread bloqué sur un verrou de moniteur passe à l'état de veille, et Perfetto affiche un segment indiquant le propriétaire du verrou.
Lorsque vous interrogez des données de trace, recherchez les tranches nommées "monitor contention with …" (contention de surveillance avec …), suivies du nom du thread qui possède le verrou et du site de code où le verrou a été acquis.
Étude de cas : saccades du Lanceur d'applications
Pour illustrer cela, analysons une trace dans laquelle un utilisateur a rencontré des à-coups lors de la navigation vers l'écran d'accueil sur un téléphone Pixel immédiatement après avoir pris une photo dans l'application Appareil photo. Vous trouverez ci-dessous une capture d'écran de Perfetto montrant les événements ayant précédé le saut d'image :
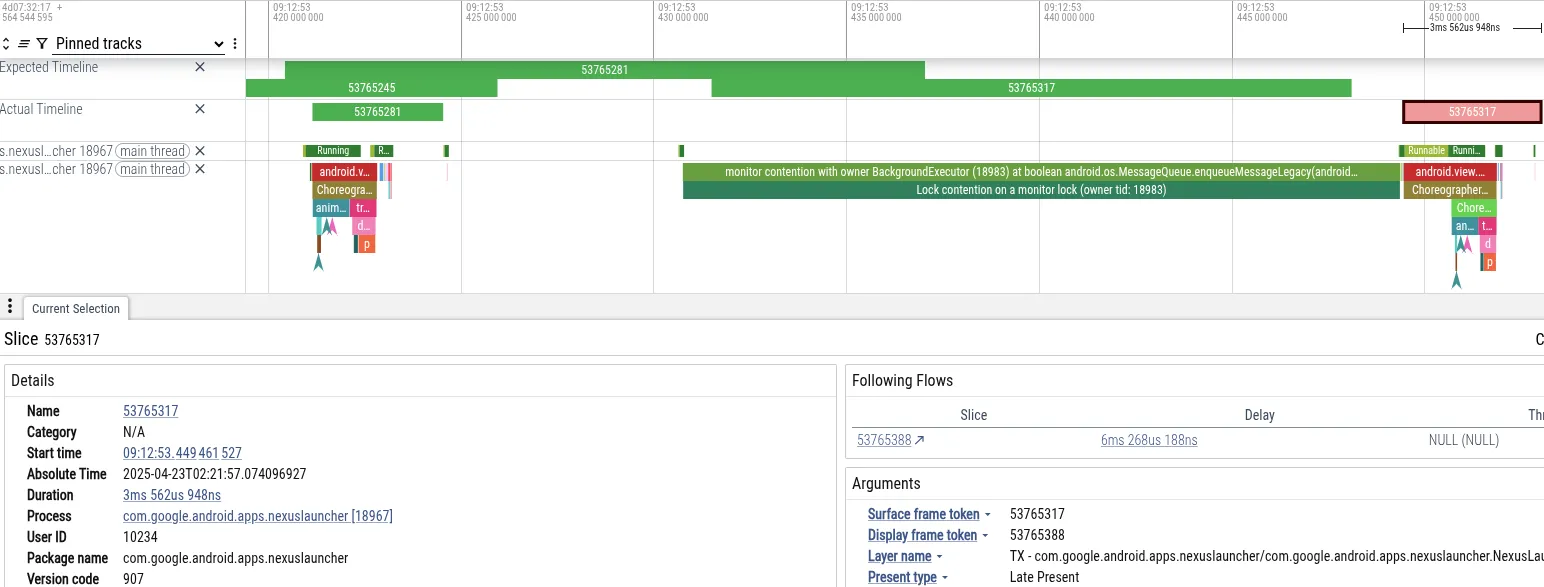
- Symptôme : Le thread principal du lanceur d'applications a manqué son échéance de frame. Il a bloqué pendant 18 ms, ce qui dépasse le délai de 16 ms requis pour le rendu à 60 Hz.
- Diagnostic : Perfetto a montré que le thread principal était bloqué sur le verrou
MessageQueue. Un thread "BackgroundExecutor" possédait le verrou. - Cause première : BackgroundExecutor s'exécute à Process.THREAD_PRIORITY_BACKGROUND (priorité très faible). Elle a effectué une tâche non urgente (vérification des limites d'utilisation des applications). Simultanément, les threads de priorité moyenne utilisaient du temps de processeur pour traiter les données de la caméra. Le planificateur de l'OS a préempté le thread BackgroundExecutor pour exécuter les threads de la caméra.
Cette séquence a entraîné le blocage indirect du thread UI du lanceur d'applications (priorité élevée) par le thread de travail de l'appareil photo (priorité moyenne), qui empêchait le thread d'arrière-plan du lanceur d'applications (priorité faible) de libérer le verrou.
Interroger des traces avec PerfettoSQL
Vous pouvez utiliser PerfettoSQL pour interroger les données de trace pour des modèles spécifiques. Cela peut être utile si vous disposez d'une grande quantité de traces provenant d'appareils utilisateur ou de tests, et que vous recherchez des traces spécifiques qui mettent en évidence un problème.
Par exemple, cette requête permet de trouver les conflits MessageQueue coïncidant avec les images abandonnées (jank) :
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
Dans cet exemple plus complexe, joignez les données de trace qui s'étendent sur plusieurs tables pour identifier la contention MessageQueue lors du démarrage de l'application :
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Vous pouvez utiliser votre LLM préféré pour écrire des requêtes PerfettoSQL afin de trouver d'autres modèles.
Chez Google, nous utilisons BigTrace pour exécuter des requêtes PerfettoSQL sur des millions de traces. Nous avons ainsi confirmé que ce que nous avions observé de manière anecdotique était en fait un problème systémique. Les données ont révélé que la contention de verrouillage MessageQueue avait un impact sur les utilisateurs de l'ensemble de l'écosystème, ce qui justifie la nécessité d'un changement architectural fondamental.
Solution : concurrence sans verrouillage
Nous avons résolu le problème de contention MessageQueue en implémentant une structure de données sans verrou, en utilisant des opérations de mémoire atomiques plutôt que des verrous exclusifs pour synchroniser l'accès à l'état partagé. Une structure de données ou un algorithme est sans verrouillage si au moins un thread peut toujours progresser, quel que soit le comportement de planification des autres threads. Cette propriété est généralement difficile à atteindre et ne vaut généralement pas la peine d'être recherchée pour la plupart des codes.
Primitives atomiques
Les logiciels sans verrouillage s'appuient souvent sur des primitives atomiques de lecture-modification-écriture fournies par le matériel.
Sur les anciennes générations de processeurs ARM64, les atomiques utilisaient une boucle Load-Link/Store-Conditional (LL/SC). Le processeur charge une valeur et marque l'adresse. Si un autre thread écrit à cette adresse, le magasin échoue et la boucle effectue une nouvelle tentative. Étant donné que les threads peuvent continuer à essayer et à réussir sans attendre un autre thread, cette opération est sans verrouillage.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr(afficher dans Compiler Explorer)
Les architectures ARM plus récentes (ARMv8.1) sont compatibles avec les grandes extensions système (LSE), qui incluent des instructions sous la forme de Compare-And-Swap (CAS) ou Load-And-Add (démontrées ci-dessous). Dans Android 17, nous avons ajouté la prise en charge du compilateur Android Runtime (ART) pour détecter quand LSE est compatible et émettre des instructions optimisées :
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Dans nos benchmarks, le code à forte contention qui utilise CAS permet d'obtenir un gain de vitesse d'environ 3x par rapport à la variante LL/SC.
Le langage de programmation Java propose des primitives atomiques via java.util.concurrent.atomic, qui s'appuient sur ces instructions et d'autres instructions CPU spécialisées.
Structure des données : DeliQueue
Pour supprimer la contention de verrouillage de MessageQueue, nos ingénieurs ont conçu une nouvelle structure de données appelée DeliQueue. DeliQueue sépare l'insertion Message du traitement Message :
- Liste de
Messages(pile Treiber) : pile sans verrouillage. N'importe quel thread peut envoyer de nouveauxMessagesici sans conflit. - File d'attente prioritaire (tas min) : tas de
Messagesà gérer, appartenant exclusivement au thread Looper (aucune synchronisation ni aucun verrou ne sont donc nécessaires pour y accéder).
Mise en file d'attente : envoi à une pile Treiber
La liste des Messages est conservée dans une pile Treiber [1], une pile sans verrouillage qui utilise une boucle CAS pour mettre à jour le pointeur de tête.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Code source basé sur Java Concurrency in Practice [2], disponible en ligne et publié dans le domaine public
Tout producteur peut envoyer de nouveaux Message à la pile à tout moment. C'est comme prendre un ticket à la charcuterie : votre numéro est déterminé par l'heure à laquelle vous êtes arrivé, mais l'ordre dans lequel vous recevez votre nourriture n'a pas besoin de correspondre. Comme il s'agit d'une pile liée, chaque Message est une sous-pile. Vous pouvez voir à quoi ressemblait la file d'attente Message à tout moment en suivant l'en-tête et en itérant vers l'avant. Vous ne verrez aucun nouveau Message ajouté en haut, même s'ils sont ajoutés pendant votre parcours.
Dequeue : transfert groupé vers un tas min
Pour trouver le prochain Message à traiter, Looper traite les nouveaux Message de la pile Treiber en parcourant la pile à partir du haut et en itérant jusqu'à ce qu'il trouve le dernier Message qu'il a traité précédemment. À mesure que Looper parcourt la pile, il insère des Message dans le tas min ordonné par date limite. Étant donné que Looper possède exclusivement le tas de mémoire, il ordonne et traite les Message sans verrous ni atomiques.

En parcourant la pile, Looper crée également des liens entre les Message empilés et leurs prédécesseurs, formant ainsi une liste doublement chaînée. La création de la liste chaînée est sécurisée, car les liens pointant vers le bas de la pile sont ajoutés via l'algorithme de pile Treiber avec CAS, et les liens pointant vers le haut de la pile ne sont lus et modifiés que par le thread Looper. Ces liens retour sont ensuite utilisés pour supprimer les Message à partir de points arbitraires de la pile en temps O(1).
Cette conception permet une insertion O(1) pour les producteurs (les threads qui publient le travail dans la file d'attente) et un traitement amorti O(log N) pour le consommateur (le Looper).
L'utilisation d'un tas minimal pour ordonner les Message corrige également un défaut fondamental de l'ancien MessageQueue, où les Message étaient conservés dans une liste à un seul lien (enracinée en haut). Dans l'ancienne implémentation, la suppression de l'en-tête était O(1), mais l'insertion avait un cas le plus défavorable de O(N), ce qui entraînait une mauvaise mise à l'échelle pour les files d'attente surchargées. À l'inverse, l'insertion et la suppression dans le min-heap sont logarithmiques, ce qui offre des performances moyennes compétitives, mais excelle en termes de latence de queue.
Ancienne (verrouillée) MessageQueue | DeliQueue | |
| Insérer | O(N) | O(1) pour le thread d'appel O(logN) pour le thread |
| Retirer de la tête | O(1) | O(logN) |
Dans l'ancienne implémentation de la file d'attente, les producteurs et le consommateur utilisaient un verrou pour coordonner l'accès exclusif à la liste chaînée sous-jacente. Dans DeliQueue, la pile Treiber gère l'accès simultané, et le consommateur unique gère l'ordre de sa file d'attente de tâches.
Suppression : cohérence grâce aux pierres tombales
DeliQueue est une structure de données hybride qui combine une pile Treiber sans verrouillage et un tas min-heap à thread unique. La synchronisation de ces deux structures sans verrou global présente un défi unique : un message peut être physiquement présent dans la pile, mais logiquement supprimé de la file d'attente.
Pour résoudre ce problème, DeliQueue utilise une technique appelée "tombstoning". Chaque Message suit sa position dans la pile à l'aide des pointeurs vers l'arrière et vers l'avant, de son index dans le tableau du tas et d'un indicateur booléen indiquant s'il a été supprimé. Lorsqu'un Message est prêt à s'exécuter, le thread Looper CAS son indicateur de suppression, puis le supprime du tas de mémoire et de la pile.
Lorsqu'un autre thread doit supprimer un Message, il ne l'extrait pas immédiatement de la structure de données. En revanche, il effectue les opérations suivantes :
- Suppression logique : le thread utilise un CAS pour définir de manière atomique l'indicateur de suppression de
Messagesur "true" (vrai) au lieu de "false" (faux). LeMessagereste dans la structure de données comme preuve de sa suppression en attente, ce que l'on appelle une "pierre tombale". Une fois qu'unMessageest marqué pour suppression, DeliQueue le traite comme s'il n'existait plus dans la file d'attente chaque fois qu'il est trouvé. - Nettoyage différé : la suppression effective de la structure de données est la responsabilité du thread
Looperet est différée. Plutôt que de modifier la pile ou le tas, le thread de suppression ajouteMessageà une autre pile de liste libre sans verrouillage. - Suppression structurelle : seul le
Looperpeut interagir avec le tas ou supprimer des éléments de la pile. Lorsqu'il se réveille, il efface la liste libre et traite lesMessagequ'elle contenait. ChaqueMessageest ensuite dissocié de la pile et supprimé du tas.
Cette approche permet de conserver toute la gestion du tas en monothread. Il minimise le nombre d'opérations simultanées et de barrières de mémoire requises, ce qui rend le chemin critique plus rapide et plus simple.
Traversal : courses aux données du modèle de mémoire Java bénignes
La plupart des API de simultanéité, telles que Future dans la bibliothèque standard Java, ou Job et Deferred de Kotlin, incluent un mécanisme permettant d'annuler le travail avant qu'il ne soit terminé. Une instance de l'une de ces classes correspond à une unité de travail sous-jacente. L'appel de cancel sur un objet annule les opérations spécifiques qui lui sont associées.
Les appareils Android actuels sont dotés de processeurs multicœurs et d'une récupération de mémoire concurrente et générationnelle. Toutefois, lors du développement initial d'Android, il était trop coûteux d'allouer un objet à chaque unité de travail. Par conséquent, Handler d'Android accepte l'annulation via de nombreuses surcharges de removeMessages. Au lieu de supprimer un Message spécifique, il supprime tous les Message correspondant aux critères spécifiés. En pratique, cela nécessite d'itérer sur tous les Message insérés avant l'appel de removeMessages et de supprimer ceux qui correspondent.
Lors d'une itération vers l'avant, un thread ne nécessite qu'une seule opération atomique ordonnée pour lire l'en-tête actuel de la pile. Ensuite, des lectures de champ ordinaires sont utilisées pour trouver le prochain Message. Si le thread Looper modifie les champs next tout en supprimant les Message, l'écriture de Looper et la lecture d'un autre thread ne sont pas synchronisées. Il s'agit d'une course aux données. En temps normal, une condition de concurrence est un bug grave qui peut entraîner d'énormes problèmes dans votre application (fuites, boucles infinies, plantages, blocages, etc.). Toutefois, dans certaines conditions spécifiques, les conflits de données peuvent être bénins dans le modèle de mémoire Java. Supposons que nous commencions avec une pile de :

Nous effectuons une lecture atomique de l'en-tête et voyons A. Le pointeur suivant de A pointe vers B. En même temps que nous traitons B, le looper peut supprimer B et C en mettant à jour A pour qu'il pointe vers C, puis vers D.
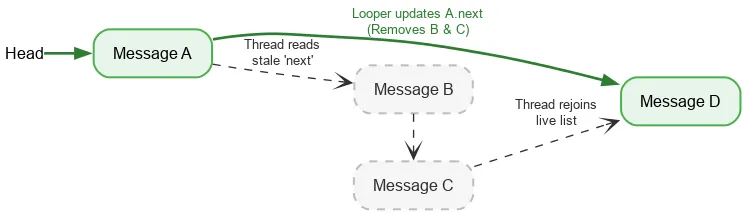
Même si B et C sont supprimés de manière logique, B conserve son pointeur suivant vers C et C vers D. Le thread de lecture continue de parcourir les nœuds supprimés détachés et rejoint finalement la pile active à D.
En concevant DeliQueue pour gérer les conflits entre la traversée et la suppression, nous permettons une itération sécurisée et sans verrouillage.
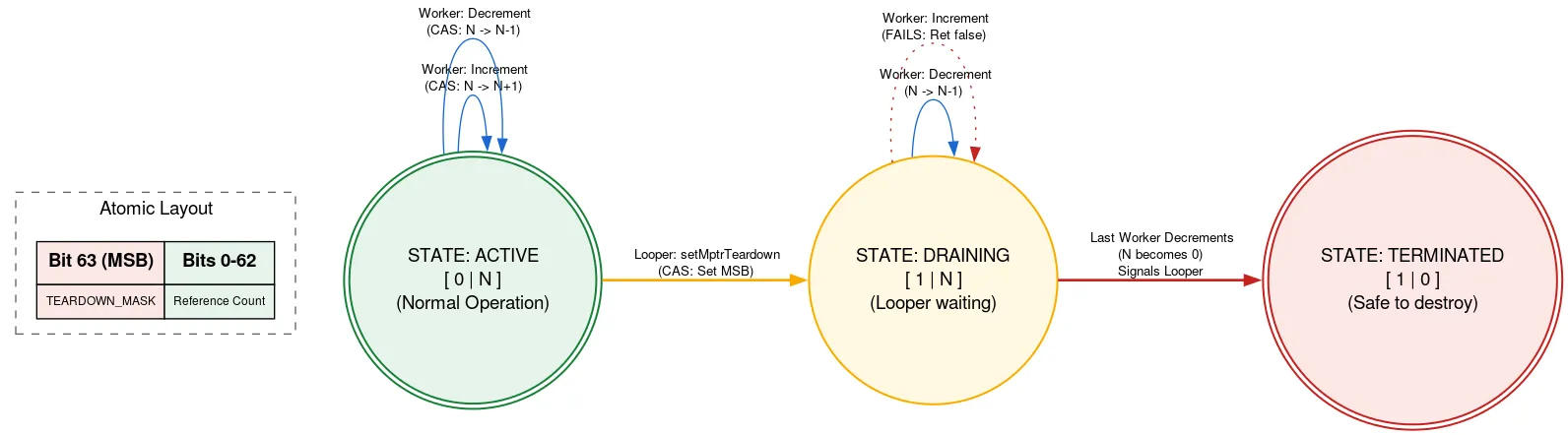
Quitting: Native refcount
Looper est soutenu par une allocation native qui doit être libérée manuellement une fois que Looper a quitté. Si un autre thread ajoute des Message alors que le Looper est en train de se fermer, il pourrait utiliser l'allocation native après sa libération, ce qui constitue une violation de la sécurité de la mémoire. Pour éviter cela, nous utilisons un compteur de références tagué, où un bit de l'atome est utilisé pour indiquer si le Looper est en train de quitter.
Avant d'utiliser l'allocation native, un thread lit l'atomic refcount. Si le bit de sortie est défini, il indique que Looper est en train de quitter et que l'allocation native ne doit pas être utilisée. Si ce n'est pas le cas, il tente d'effectuer une CAS pour incrémenter le nombre de threads actifs à l'aide de l'allocation native. Une fois qu'il a fait ce qu'il devait faire, il décrémente le nombre. Si le bit de sortie a été défini après son incrément, mais avant sa décrémentation, et que le nombre est maintenant nul, le thread Looper est réactivé.
Lorsque le thread Looper est prêt à se fermer, il utilise CAS pour définir le bit de fermeture dans l'atome. Si le nombre de références était de 0, il peut procéder à la libération de son allocation native. Dans le cas contraire, il se met en veille, sachant qu'il sera réactivé lorsque le dernier utilisateur de l'allocation native décrémentera le nombre de références. Cette approche signifie que le thread Looper attend la progression des autres threads, mais uniquement lorsqu'il se termine. Cela ne se produit qu'une seule fois et n'est pas sensible aux performances. Le reste du code permet d'utiliser l'allocation native sans aucun verrouillage.
L'implémentation comporte de nombreuses autres astuces et complexités. Pour en savoir plus sur DeliQueue, consultez le code source.
Optimisation : programmation sans branchement
Lors du développement et des tests de DeliQueue, l'équipe a exécuté de nombreux benchmarks et a soigneusement profilé le nouveau code. Un problème identifié à l'aide de l'outil simpleperf était lié aux vidages de pipeline causés par le code du comparateur Message.
Un comparateur standard utilise des sauts conditionnels, avec la condition pour décider quel Message vient en premier simplifiée ci-dessous :
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Ce code est compilé en sauts conditionnels (instructions b.le et cbnz). Lorsque le processeur rencontre une branche conditionnelle, il ne peut pas savoir si la branche est prise tant que la condition n'est pas calculée. Il ne sait donc pas quelle instruction lire ensuite et doit deviner, à l'aide d'une technique appelée prédiction de branchement. Dans le cas d'une recherche binaire, la direction de la branche sera différente de manière imprévisible à chaque étape. Il est donc probable que la moitié des prédictions soient erronées. La prédiction de branchement est souvent inefficace dans les algorithmes de recherche et de tri (comme celui utilisé dans un tas min), car le coût d'une mauvaise prédiction est supérieur à l'amélioration obtenue en cas de prédiction correcte. Lorsque le prédicteur de branchement se trompe, il doit jeter le travail effectué après avoir supposé la valeur prédite et recommencer à partir du chemin réellement emprunté. C'est ce qu'on appelle un vidage du pipeline.
Pour identifier ce problème, nous avons profilé nos benchmarks à l'aide du compteur de performances branch-misses, qui enregistre les traces de pile où le prédicteur de branche se trompe. Nous avons ensuite visualisé les résultats avec Google pprof, comme indiqué ci-dessous :
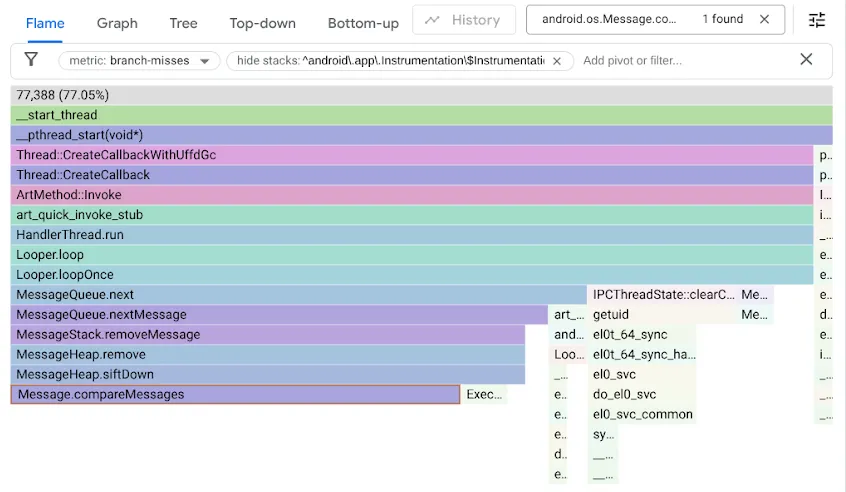
Rappelez-vous que le code MessageQueue d'origine utilisait une liste chaînée simple pour la file d'attente ordonnée. L'insertion parcourrait la liste dans l'ordre trié sous forme de recherche linéaire, s'arrêtant au premier élément qui dépasse le point d'insertion et liant le nouvel Message devant lui. Pour retirer la tête, il suffisait de la dissocier. Alors que DeliQueue utilise un tas min, où les mutations nécessitent de réorganiser certains éléments (en les déplaçant vers le haut ou vers le bas) avec une complexité logarithmique dans une structure de données équilibrée, où toute comparaison a une chance égale de diriger la traversée vers un enfant de gauche ou un enfant de droite. Le nouvel algorithme est asymptotiquement plus rapide, mais expose un nouveau goulot d'étranglement, car le code de recherche s'arrête sur les échecs de branchement la moitié du temps.
Nous avons constaté que les échecs de branchement ralentissaient notre code de tas de mémoire. Nous avons donc optimisé le code à l'aide de la programmation sans branchement :
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Pour comprendre l'optimisation, désassemblez les deux exemples dans Compiler Explorer et utilisez LLVM-MCA, un simulateur de processeur qui peut générer une estimation de la chronologie des cycles de processeur.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Notez la branche conditionnelle b.le, qui évite de comparer les champs insertSeq si le résultat est déjà connu grâce à la comparaison des champs when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Ici, l'implémentation sans branchement prend moins de cycles et d'instructions que le chemin le plus court à travers le code avec branchement. Elle est meilleure dans tous les cas. L'implémentation plus rapide et l'élimination des branches mal prédites ont permis d'améliorer certains de nos benchmarks par un facteur 5.
Toutefois, cette technique n'est pas toujours applicable. Les approches sans branchement nécessitent généralement d'effectuer un travail qui sera jeté. Si la branche est prévisible la plupart du temps, ce travail gaspillé peut ralentir votre code. De plus, la suppression d'une branche introduit souvent une dépendance aux données. Les processeurs modernes exécutent plusieurs opérations par cycle, mais ils ne peuvent pas exécuter une instruction tant que ses entrées provenant d'une instruction précédente ne sont pas prêtes. En revanche, un processeur peut spéculer sur les données des branches et travailler à l'avance si une branche est prédite correctement.
Tests et validation
Valider l'exactitude des algorithmes sans verrouillage est notoirement difficile.
En plus des tests unitaires standards pour la validation continue pendant le développement, nous avons également écrit des tests de résistance rigoureux pour vérifier les invariants de la file d'attente et tenter d'induire des conflits de données s'ils existaient. Dans nos laboratoires de test, nous avons pu exécuter des millions d'instances de test sur des appareils émulés et sur du matériel réel.
Avec l'instrumentation Java ThreadSanitizer (JTSan), nous pouvons utiliser les mêmes tests pour détecter également certaines conditions de concurrence dans notre code. JTSan n'a détecté aucune course aux données problématique dans DeliQueue, mais a étonnamment détecté deux bugs de concurrence dans le framework Robolectric, que nous avons rapidement corrigés.
Pour améliorer nos capacités de débogage, nous avons créé de nouveaux outils d'analyse. Vous trouverez ci-dessous un exemple illustrant un problème dans le code de la plate-forme Android, où un thread surcharge un autre thread avec des Message, ce qui entraîne un backlog important, visible dans Perfetto grâce à la fonctionnalité d'instrumentation MessageQueue que nous avons ajoutée.
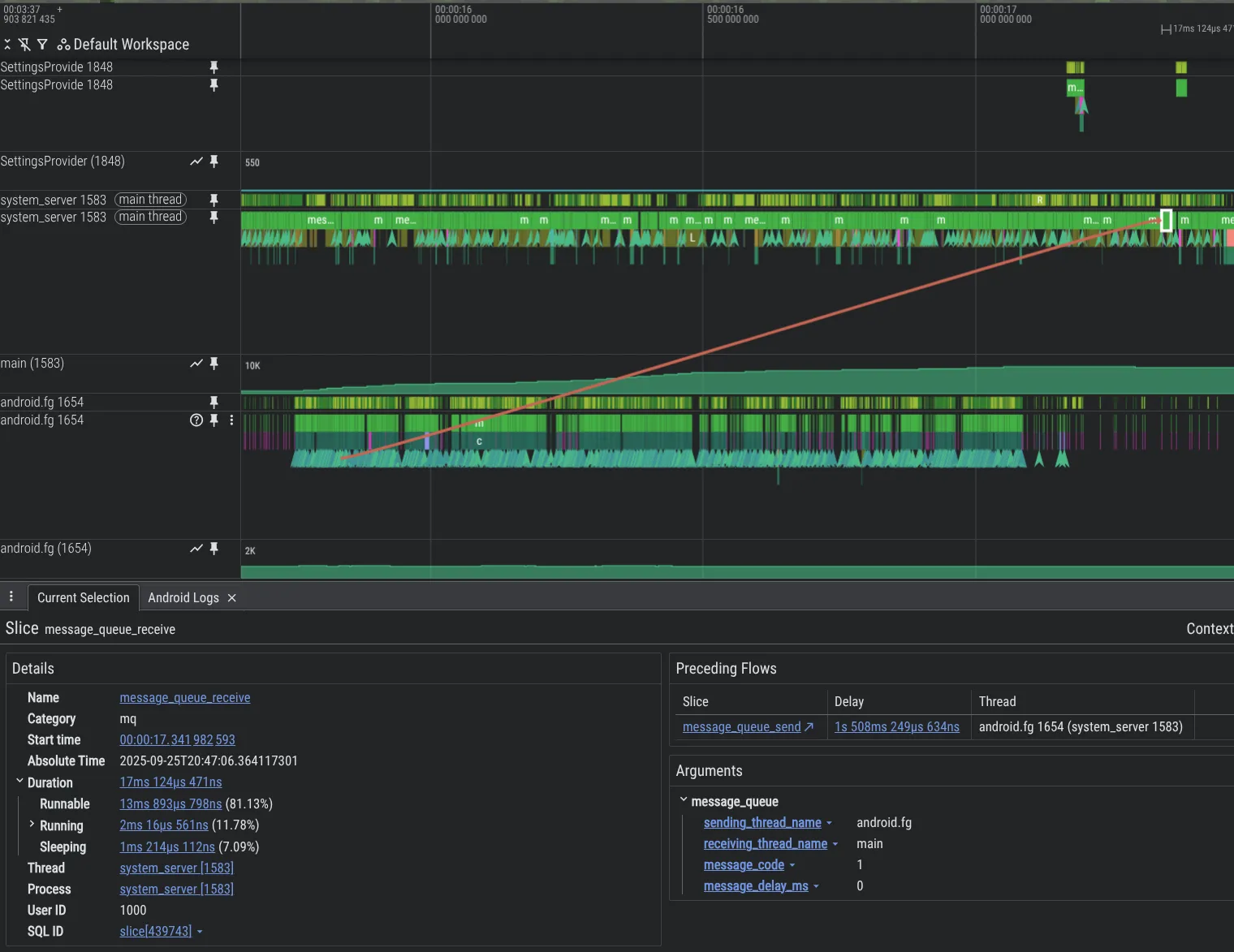
Pour activer le traçage MessageQueue dans le processus system_server, incluez les éléments suivants dans votre configuration Perfetto :
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Conséquences
DeliQueue améliore les performances du système et des applications en éliminant les verrous de MessageQueue.
- Benchmarks synthétiques : les insertions multithread dans les files d'attente occupées sont jusqu'à 5 000 fois plus rapides que l'ancienne
MessageQueue, grâce à une meilleure simultanéité (pile Treiber) et à des insertions plus rapides (min-heap). - Dans les traces Perfetto obtenues auprès de nos bêta-testeurs internes, nous constatons une réduction de 15% du temps passé par le thread principal de l'application dans les conflits de verrouillage.
- Sur les mêmes appareils de test, la réduction de la contention de verrouillage entraîne des améliorations significatives de l'expérience utilisateur, par exemple :
- -4% d'images manquées dans les applications.
- -7,7% d'images manquées dans les interactions avec l'UI du système et le lanceur d'applications.
- -9,1 % de temps écoulé entre le démarrage de l'application et le premier frame affiché, au 95e centile.
Étapes suivantes
DeliQueue est déployé dans les applications sous Android 17. Les développeurs d'applications doivent consulter l'article sur la préparation de votre application pour le nouveau MessageQueue sans verrouillage sur le blog des développeurs Android pour savoir comment tester leurs applications.
Références
[1] Treiber, R.K., 1986. Programmation système : faire face au parallélisme. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Écrit par :
Lire la suite
-


Actualités des produits
L'année dernière, nous avons introduit la validation des développeurs Android pour renforcer la sécurité de l'écosystème et empêcher les personnes malintentionnées de se cacher derrière l'anonymat pour publier des applications dangereuses.
Matthew Forsythe • 2 min de lecture
-



Actualités des produits
Des calques de réalité augmentée aux environnements entièrement immersifs, l'écosystème Android XR se développe rapidement. Le Samsung Galaxy XR est déjà disponible.
Stevan Silva, Vinny DaSilva • Temps de lecture : 3 min
-


Actualités des produits
Chaque année, Google I/O apporte de nouvelles annonces et ressources pour les écosystèmes et les produits, y compris le développement Android. Le développement se tournant vers l'IA et les outils assistés par des agents, nous avons élargi nos offres pour mieux vous accompagner, quelle que soit la façon dont vous décidez de développer pour Android.
Simona Milanovic • 2 min de lecture
Restez informé
Recevez chaque semaine les dernières informations sur le développement Android directement dans votre boîte de réception.
