

ב-Android 17, אפליקציות שמטרגטות SDK בגרסה 37 ואילך יקבלו הטמעה חדשה של MessageQueue, שבה ההטמעה לא דורשת נעילה. ההטמעה החדשה משפרת את הביצועים ומפחיתה את מספר הפריימים החסרים, אבל היא עלולה לגרום לשיבוש בלקוחות שמשקפים שדות ושיטות פרטיים של MessageQueue. כדי לקבל מידע נוסף על השינוי בהתנהגות ועל דרכים לצמצום ההשפעה, אפשר לעיין במסמכי השינוי בהתנהגות של MessageQueue. בפוסט הזה בבלוג הטכני מוסבר על הארכיטקטורה החדשה של MessageQueue ואיך אפשר לנתח בעיות שקשורות למאבקים על נעילה באמצעות Perfetto.
Looper מפעיל את שרשור ה-UI של כל אפליקציה ל-Android. הוא שולף עבודה מ-MessageQueue, מעביר אותה ל-Handler וחוזר חלילה. במשך שני עשורים, MessageQueue השתמש בנעילת צג יחידה (כלומר, MessageQueue בלוק קוד) כדי להגן על המצב שלו.synchronized
ב-Android 17 מוצג עדכון משמעותי לרכיב הזה: הטמעה ללא נעילה בשם DeliQueue.
בפוסט הזה מוסבר איך נעילות משפיעות על ביצועי ממשק המשתמש, איך לנתח את הבעיות האלה באמצעות Perfetto, ואילו אלגוריתמים ואופטימיזציות ספציפיים משמשים לשיפור השרשור הראשי ב-Android.
הבעיה: התנגשות נעילה והיפוך סדר עדיפויות
הגרסה הקודמת של MessageQueue פעלה כרשימת המתנה ממוינת שמוגנת על ידי נעילה יחידה. אם שרשור ברקע מפרסם הודעה בזמן שהשרשור הראשי מבצע תחזוקה של התור, השרשור ברקע חוסם את השרשור הראשי.
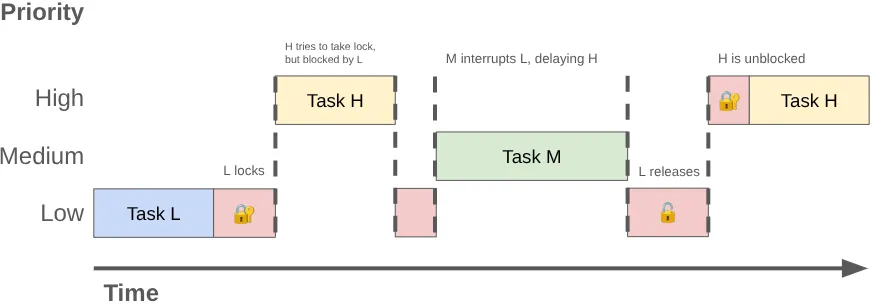
כששני ת'רדים או יותר מתחרים על שימוש בלעדי באותו נעילה, זה נקרא תחרות על נעילה. התחרות הזו עלולה לגרום להיפוך עדיפות, שמוביל לבעיות בביצועים ולתנודות בממשק המשתמש.
היפוך עדיפויות יכול לקרות כשגורמים ל-thread בעדיפות גבוהה (כמו שרשור UI) להמתין ל-thread בעדיפות נמוכה. נניח שיש לכם את הרצף הבא:
- שרשור ברקע עם עדיפות נמוכה מקבל את הנעילה
MessageQueueכדי לפרסם את תוצאת העבודה שהוא ביצע. - תהליך עם עדיפות בינונית הופך לניתן להרצה, והמתזמן של ליבת מערכת ההפעלה מקצה לו זמן מעבד, תוך שהוא קוטע את התהליך עם העדיפות הנמוכה.
- ה-thread של ממשק המשתמש עם עדיפות גבוהה מסיים את המשימה הנוכחית ומנסה לקרוא מהתור, אבל הוא נחסם כי ה-thread עם העדיפות הנמוכה מחזיק את הנעילה.
ה-thread בעדיפות נמוכה חוסם את שרשור UI, והעבודה בעדיפות בינונית מעכבת אותו עוד יותר.
ניתוח של מחלוקות באמצעות Perfetto
אפשר לאבחן את הבעיות האלה באמצעות Perfetto. במעקב רגיל, שרשור שנחסם על ידי נעילת מוניטור עובר למצב שינה, ו-Perfetto מציג פרוסה שמציינת את הבעלים של הנעילה.
כשמבצעים שאילתה על נתוני מעקב, מחפשים פרוסות בשם monitor contention with … ואחריהן את שם השרשור שבבעלותו הנעילה ואת אתר הקוד שבו הנעילה נרכשה.
מקרה לדוגמה: בעיות בביצועים של מרכז האפליקציות
כדי להמחיש את העניין, ננתח trace שבו משתמש חווה jank בזמן הניווט במסך הבית בטלפון Pixel, מיד אחרי שצילם תמונה באפליקציית המצלמה. בהמשך מוצג צילום מסך של Perfetto שבו אפשר לראות את האירועים שהובילו לפריים החסר:
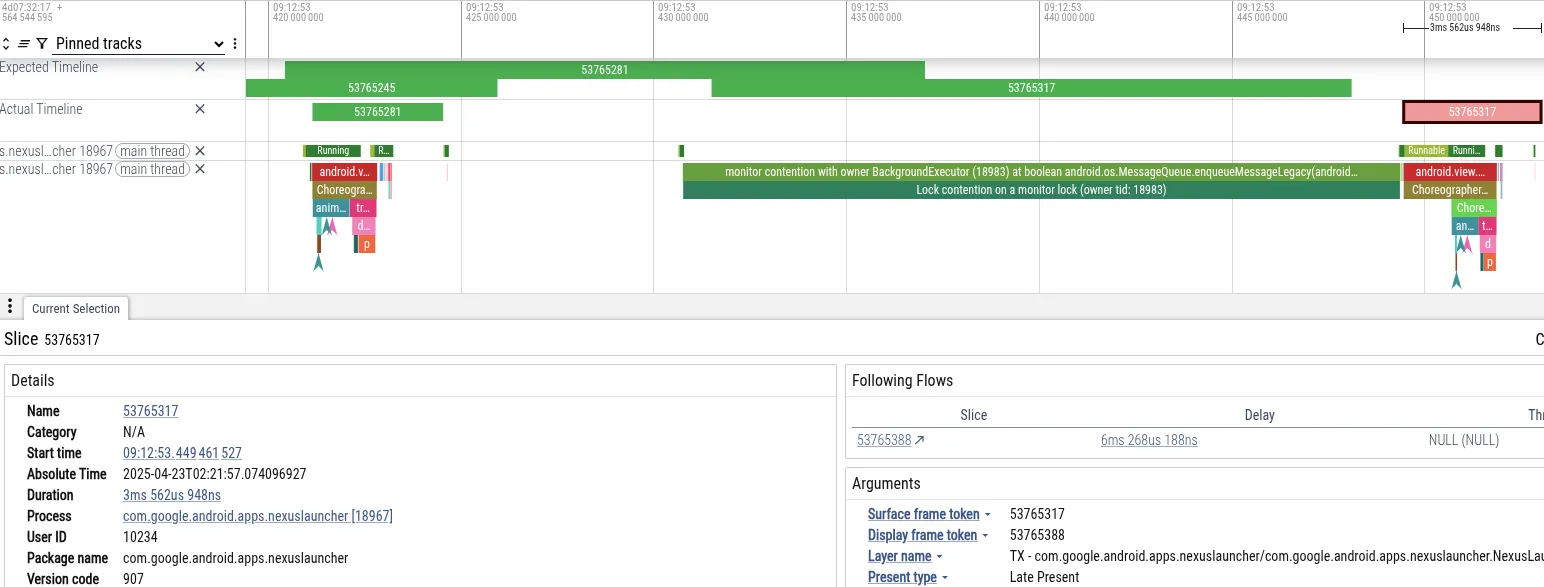
- תסמין: התהליכון הראשי של מרכז האפליקציות לא עמד בדדליין של המסגרת. הוא נחסם למשך 18 אלפיות השנייה, שזה יותר מהמועד האחרון של 16 אלפיות השנייה שנדרש לעיבוד של 60Hz.
- אבחון: Perfetto הראה שהתהליכון הראשי נחסם בנעילה
MessageQueue. השרשור 'BackgroundExecutor' היה הבעלים של הנעילה. - הגורם הבסיסי: התהליך BackgroundExecutor פועל ב-Process.THREAD_PRIORITY_BACKGROUND (עדיפות נמוכה מאוד). הוא ביצע משימה לא דחופה (בדיקה של מגבלות השימוש באפליקציות). במקביל, השרשורים בעדיפות בינונית השתמשו בזמן המעבד כדי לעבד נתונים מהמצלמה. מתזמן מערכת ההפעלה קטע את השרשור BackgroundExecutor כדי להריץ את השרשורים של המצלמה.
הרצף הזה גרם לשרשור ממשק המשתמש של מרכז האפליקציות (עדיפות גבוהה) להיחסם באופן עקיף על ידי שרשור העובד של המצלמה (עדיפות בינונית), שמנע משרשור הרקע של מרכז האפליקציות (עדיפות נמוכה) לשחרר את הנעילה.
שאילתת עקבות באמצעות PerfettoSQL
אתם יכולים להשתמש ב-PerfettoSQL כדי להריץ שאילתות על נתוני מעקב ולחפש דפוסים ספציפיים. האפשרות הזו שימושית אם יש לכם מאגר גדול של נתוני מעקב ממכשירי משתמשים או מבדיקות, ואתם מחפשים נתוני מעקב ספציפיים שמדגימים בעיה.
לדוגמה, השאילתה הזו מוצאת MessageQueue התנגשות שחלה במקביל לפריימים שהושמטו (בעיות בממשק):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
בדוגמה המורכבת יותר הזו, נתוני עקבות שמתפרסים על פני כמה טבלאות משולבים כדי לזהות התנגשות של MessageQueue במהלך הפעלת האפליקציה:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
אתם יכולים להשתמש במודל שפה גדול (LLM) שאתם אוהבים כדי לכתוב שאילתות PerfettoSQL ולמצוא דפוסים אחרים.
ב-Google, אנחנו משתמשים ב-BigTrace כדי להריץ שאילתות PerfettoSQL על מיליוני עקבות. במהלך הבדיקה, אישרנו שמה שראינו באופן לא רשמי היה למעשה בעיה מערכתית. הנתונים הראו שמתרחשת MessageQueue תחרות על נעילה שמשפיעה על משתמשים בכל האקוסיסטם, ולכן נדרש שינוי ארכיטקטוני מהותי.
פתרון: מקביליות ללא נעילה
כדי לפתור את בעיית ההתנגשות, הטמענו מבנה נתונים ללא נעילה, שמשתמש בפעולות זיכרון אטומיות במקום בנעילות בלעדיות כדי לסנכרן את הגישה למצב משותף.MessageQueue מבנה נתונים או אלגוריתם הם חופשיים מנעילה אם לפחות לשרשור אחד תמיד יש התקדמות, ללא קשר להתנהגות התזמון של השרשורים האחרים. בדרך כלל קשה להשיג את המאפיין הזה, וברוב המקרים לא כדאי לנסות להשיג אותו עבור רוב הקוד.
הפרימיטיבים האטומיים
תוכנה ללא נעילה מסתמכת בדרך כלל על פרימיטיבים אטומיים של קריאה-שינוי-כתיבה שהחומרה מספקת.
במעבדי ARM64 מדור ישן, פעולות אטומיות השתמשו בלולאת Load-Link/Store-Conditional (LL/SC). ה-CPU טוען ערך ומסמן את הכתובת. אם תהליך אחר כותב לכתובת הזו, האחסון נכשל והלולאה מנסה שוב. מכיוון שה-threads יכולים להמשיך לנסות ולהצליח בלי להמתין ל-thread אחר, הפעולה הזו לא דורשת נעילה.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrארכיטקטורות ARM חדשות יותר (ARMv8.1) תומכות ב-Large System Extensions (LSE) שכוללות הוראות בצורה של Compare-And-Swap (CAS) או Load-And-Add (כפי שמוצג בהמשך). ב-Android 17 הוספנו תמיכה לקומפיילר של Android Runtime (ART) כדי לזהות מתי יש תמיכה ב-LSE ולפלוט הוראות אופטימליות:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.בבנצ'מרקים שלנו, קוד עם רמת תחרות גבוהה שמשתמש ב-CAS משיג מהירות גבוהה פי 3 בערך בהשוואה לגרסת LL/SC.
שפת התכנות Java מציעה פרימיטיבים אטומיים דרך java.util.concurrent.atomic שמסתמכים על ההוראות האלה ועל הוראות מיוחדות אחרות של המעבד.
מבנה הנתונים: DeliQueue
כדי להסיר את התחרות על נעילה מ-MessageQueue, המהנדסים שלנו תכננו מבנה נתונים חדשני שנקרא DeliQueue. DeliQueue מפריד בין Message הוספה לבין Message עיבוד:
- הרשימה של
Messages(Treiber stack): מחסנית ללא נעילה. כל שרשור יכול לדחוף לכאןMessagesחדש בלי התנגשות. - תור העדיפויות (Min-heap): ערימה של
Messagesלטיפול, בבעלות בלעדית של השרשור Looper (לכן לא נדרש סנכרון או נעילות כדי לגשת).
הוספה לתור: שליחה לערימת Treiber
הרשימה של Messages נשמרת במחסנית Treiber [1], מחסנית ללא נעילה שמשתמשת בלולאת CAS כדי לעדכן את מצביע הראש.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}קוד מקור שמבוסס על Java Concurrency in Practice [2], זמין באינטרנט ופורסם בדומיין הציבורי
כל יצרן יכול להוסיף Message חדשים למערך בכל שלב. זה כמו לקבל מספר בתור בדלפק של מעדנייה – המספר שלכם נקבע לפי השעה שבה הגעתם, אבל לא בטוח שתקבלו את האוכל לפי הסדר. מכיוון שמדובר במחסנית מקושרת, כל Message הוא מחסנית משנה – אפשר לראות איך תור Message נראה בכל נקודת זמן על ידי מעקב אחרי הראש וחזרה על הפעולה קדימה – לא תראו Message חדשים שנדחפים למעלה, גם אם הם נוספים במהלך המעבר.
הוצאה מהתור: העברה בכמות גדולה ל-min-heap
כדי למצוא את Message הבא לטיפול, Looper מעבד Messages חדשים ממערך Treiber על ידי סריקת המערך מלמעלה למטה, עד שהוא מוצא את Message האחרון שהוא עיבד קודם. בזמן ש-Looper עובר דרך המחסנית, הוא מוסיף Messages ל-min-heap לפי סדר תאריכי היעד. מכיוון ש-Looper הוא הבעלים הבלעדי של ה-heap, הוא מסדר ומעבד את Messages ללא נעילות או פעולות אטומיות.

במעבר בין הרמות, Looper יוצר גם קישורים מMessages מוערמים בחזרה אל הקודמים שלהם, וכך נוצרת רשימה עם קישורים כפולים. יצירת הרשימה המקושרת היא בטוחה כי קישורים שמצביעים כלפי מטה במחסנית מתווספים באמצעות אלגוריתם המחסנית של Treiber עם CAS, וקישורים כלפי מעלה במחסנית נקראים ומשתנים רק על ידי השרשור Looper. לאחר מכן, משתמשים בקישורים החוזרים האלה כדי להסיר Messages מנקודות שרירותיות במחסנית בזמן O(1).
העיצוב הזה מספק הוספה של O(1) לבעלי התוכן (שרשורים שמפרסמים עבודות בתור) ועיבוד ממוצע של O(log N) לצרכן (ה- Looper).
שימוש ב-min-heap כדי להזמין Messages פותר גם פגם מהותי ב- MessageQueue מדור קודם, שבו Messages נשמרו ברשימה מקושרת יחידה (עם שורש בחלק העליון). ביישום הקודם, ההסרה מהראש הייתה O(1), אבל ההוספה הייתה במקרה הגרוע ביותר O(N) – מה שאומר שהתאמת הגודל לא הייתה טובה לתורים עמוסים מדי. לעומת זאת, הוספה ל-min-heap והסרה ממנו מתבצעות בקצב לוגריתמי, מה שמספק ביצועים ממוצעים תחרותיים, אבל מצטיין במיוחד בערכי השהיה (latency) של הזנב.
מדור קודם (נעול) MessageQueue | DeliQueue | |
| הוספה | O(N) | O(1) לשיחות בשרשור O(logN) עבור שרשור |
| הסרה מההתחלה | O(1) | O(logN) |
בהטמעה מדור קודם של תור, היצרנים והצרכן השתמשו בנעילה כדי לתאם גישה בלעדית לרשימה המקושרת הבסיסית. ב-DeliQueue, מחסנית Treiber מטפלת בגישה בו-זמנית, וצרכן יחיד מטפל בהזמנת תור העבודה שלו.
הסרה: עקביות באמצעות מצבות
DeliQueue הוא מבנה נתונים היברידי, שמשלב מחסנית Treiber ללא נעילה עם ערימת מינימום בשרשור יחיד. שמירה על סנכרון בין שתי המבנים האלה בלי נעילה גלובלית היא אתגר ייחודי: יכול להיות שהודעה תהיה נוכחת פיזית במחסנית, אבל תוסר מהתור באופן לוגי.
כדי לפתור את הבעיה הזו, DeliQueue משתמש בטכניקה שנקראת 'סימון כמבוטל'. כל Message עוקב אחרי המיקום שלו במחסנית באמצעות מצביעים קדימה ואחורה, האינדקס שלו במערך של הערימה ודגל בוליאני שמציין אם הוא הוסר. כש- Message מוכן להרצה, השרשור Looper יבצע CAS לסימון ההסרה שלו, ואז יסיר אותו מה-heap ומה-stack.
כשצריך להסיר Message משרשור אחר, הוא לא מחולץ מיד ממבנה הנתונים. במקום זאת, הוא מבצע את הפעולות הבאות:
- הסרה לוגית: השרשור משתמש ב-CAS כדי להגדיר באופן אטומי את דגל ההסרה של
Messageמ-false ל-true. ה-Messageנשאר במבנה הנתונים כהוכחה להסרה שלו שממתינה לביצוע, מה שנקרא 'מצבה'. אחרי שמסמניםMessageלהסרה, DeliQueue מתייחס אליו כאילו הוא כבר לא קיים בתור בכל פעם שהוא נמצא. - ניקוי מושהה: ההסרה בפועל ממבנה הנתונים היא באחריות השרשור
Looperומושהית עד למועד מאוחר יותר. במקום לשנות את המחסנית או את הערימה, השרשור של ההסרה מוסיף אתMessageלמחסנית אחרת של רשימה חופשית ללא נעילה. - הסרה מבנית: רק
Looperיכול ליצור אינטראקציה עם הערימה או להסיר רכיבים מהמחסנית. כשהוא מתעורר, הוא מוחק את רשימת הכתובות הזמינות ומעבד את ה-Messageשהיו בה. כלMessageמנותק מהמקבץ ומוסר מהערימה.
הגישה הזו מאפשרת לנהל את הערימה באמצעות thread יחיד. הוא מצמצם את מספר הפעולות המקבילות ואת מחסומי הזיכרון שנדרשים, וכך הופך את הנתיב הקריטי למהיר ופשוט יותר.
Traversal: benign Java memory model data races
רוב ממשקי ה-API של concurrency, כמו Future בספרייה הרגילה של Java, או Job ו-Deferred של Kotlin, כוללים מנגנון לביטול עבודה לפני שהיא מסתיימת. מופע של אחת מהמחלקות האלה תואם אחד לאחד ליחידת עבודה בסיסית, והפעלת cancel על אובייקט מבטלת את הפעולות הספציפיות שמשויכות אליו.
למכשירי Android של היום יש מעבדים מרובי ליבות ואיסוף אשפה בו-זמני ודורותי. אבל כשפיתחו את Android, היה יקר מדי להקצות אובייקט אחד לכל יחידת עבודה. לכן, Handler ב-Android תומך בביטול באמצעות עומסים רבים של removeMessages – במקום להסיר ספציפי Message, הוא מסיר את כל Messages שתואמים לקריטריונים שצוינו. בפועל, צריך לעבור על כל Messages שהוכנסו לפני removeMessages ולהסיר את אלה שתואמים.
כשמבצעים איטרציה קדימה, לשרשור נדרשת רק פעולה אטומית מסודרת אחת, כדי לקרוא את החלק העליון הנוכחי של המחסנית. אחרי כן, נעשה שימוש בקריאות רגילות של שדות כדי למצוא את Message הבא. אם השרשור Looper משנה את השדות next בזמן ההסרה של Message, הכתיבה של Looper והקריאה של שרשור אחר לא מסונכרנות – זהו מרוץ נתונים. בדרך כלל, מצב של race condition הוא באג חמור שיכול לגרום לבעיות גדולות באפליקציה – דליפות, לולאות אינסופיות, קריסות, קפיאות ועוד. עם זאת, בתנאים מסוימים ומצומצמים, מירוצי נתונים יכולים להיות לא מזיקים במודל הזיכרון של Java. נניח שמתחילים עם ערימה של:

אנחנו מבצעים קריאה אטומית של הראש ורואים A. המצביע הבא של A מצביע על B. במקביל לעיבוד של B, יכול להיות שהאובייקט להרצת לולאת הודעות בתוך תהליך (looper) יסיר את B ואת C, על ידי עדכון של A כך שיצביע על C ואז על D.
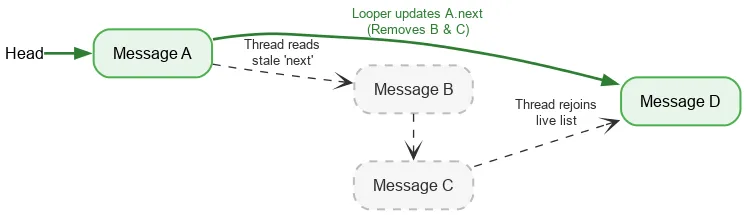
למרות שB ו-C מוסרים באופן לוגי, B שומר על המצביע הבא שלו ל-C, ו-C ל-D. שרשור הקריאה ממשיך לעבור בין הצמתים המנותקים שהוסרו, ובסופו של דבר חוזר למחסנית הפעילה ב- D.
התכנון של DeliQueue מאפשר טיפול במצבי מירוץ בין מעבר להסרה, ולכן מאפשר איטרציה בטוחה ללא נעילה.
יציאה: Native refcount
Looper מגובה בהקצאה מקומית שצריך לשחרר באופן ידני אחרי ש-Looper יוצא מהפעולה. אם תהליך אחר מוסיף Messages בזמן ש-Looper יוצא, הוא יכול להשתמש בהקצאה המקורית אחרי שהיא משוחררת, וזו הפרה של בטיחות הזיכרון. כדי למנוע את זה, אנחנו משתמשים במונה הפניות עם תג, שבו ביט אחד של הפעולה האטומית משמש לציון אם Looper יוצא.
לפני השימוש בהקצאה המקורית, השרשור קורא את המונה של ההפניות. אם הביט של היציאה מוגדר, הפונקציה מחזירה את הערך שהאפליקציה Looper יוצאת ושאסור להשתמש בהקצאה המקורית. אם לא, המערכת מנסה לבצע CAS כדי להגדיל את מספר השרשורים הפעילים באמצעות ההקצאה המקורית. אחרי שהיא מבצעת את מה שצריך, היא מקטינה את המספר. אם הביט של היציאה הוגדר אחרי ההגדלה אבל לפני ההקטנה, והספירה היא עכשיו אפס, השרשור Looper מופעל.
כשה-thread Looper מוכן לצאת, הוא משתמש ב-CAS כדי להגדיר את הביט של היציאה באטומיק. אם הערך של refcount הוא 0, אפשר להמשיך ולשחרר את ההקצאה המקורית. אחרת, הוא מושעה, כי הוא יודע שהוא יופעל כשהמשתמש האחרון בהקצאה המקורית יקטין את מונה ההפניות. המשמעות של הגישה הזו היא ש-thread Looper ממתין להתקדמות של threads אחרים, אבל רק כשהוא יוצא. הפעולה הזו מתבצעת רק פעם אחת והיא לא רגישה לביצועים. היא מאפשרת להשתמש בקוד השני להקצאה המקורית ללא נעילה.
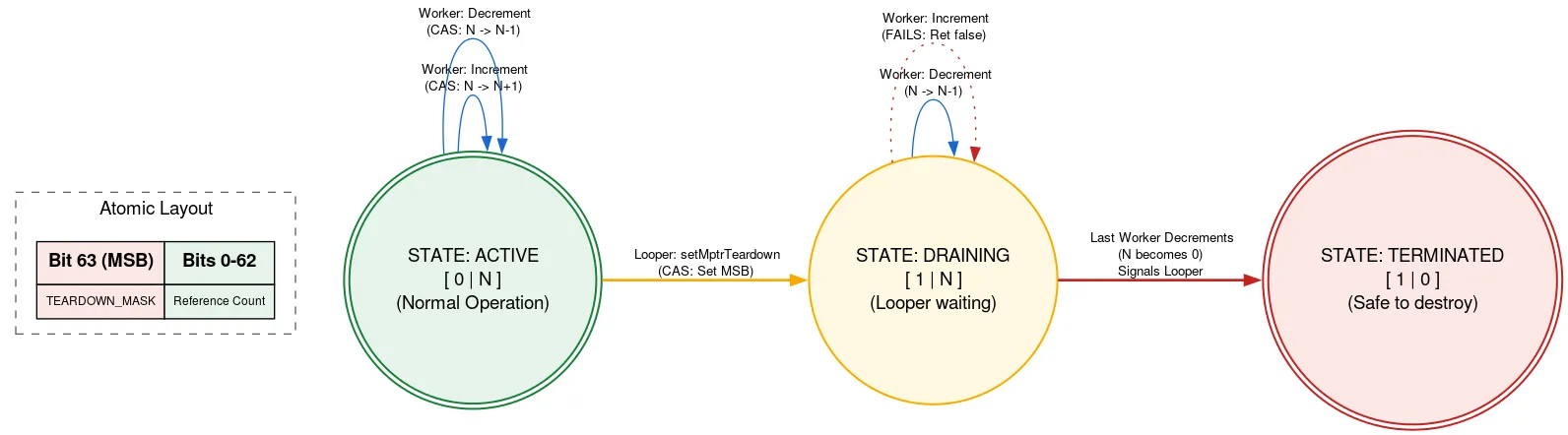
יש עוד הרבה טריקים ומורכבויות בהטמעה. אפשר לקבל מידע נוסף על DeliQueue על ידי עיון בקוד המקור.
אופטימיזציה: תכנות ללא הסתעפות
במהלך הפיתוח והבדיקה של DeliQueue, הצוות ערך הרבה בדיקות השוואה ופרופילים של הקוד החדש. בעיה אחת שזוהתה באמצעות הכלי simpleperf הייתה ניקוי של צינור עיבוד הנתונים שנגרם על ידי Message קוד ההשוואה.
במשווה רגיל נעשה שימוש בקפיצות מותנות, והתנאי להחלטה איזה Message מופיע קודם מפורט בצורה פשוטה בהמשך:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}הקוד הזה עובר קומפילציה לקפיצות מותנות (הוראות b.le ו-cbnz). כשה-CPU נתקל בהסתעפות מותנית, הוא לא יכול לדעת אם ההסתעפות תתבצע עד שהתנאי יחושב, ולכן הוא לא יודע איזו הוראה לקרוא בהמשך, והוא צריך לנחש באמצעות טכניקה שנקראת חיזוי הסתעפות. במקרה כמו חיפוש בינארי, כיוון ההסתעפות יהיה שונה באופן בלתי צפוי בכל שלב, ולכן סביר להניח שמחצית מהתחזיות יהיו שגויות. חיזוי הסתעפויות לרוב לא יעיל באלגוריתמים של חיפוש ומיון (כמו זה שמשמש ב-min-heap), כי העלות של ניחוש שגוי גדולה יותר מהשיפור שמתקבל מניחוש נכון. אם החיזוי של הענף שגוי, המעבד צריך לבטל את העבודה שנעשתה אחרי ההנחה של הערך שחזוי, ולהתחיל מחדש מהנתיב שנבחר בפועל – זה נקרא ניקוי של צינור העיבוד.
כדי למצוא את הבעיה הזו, יצרנו פרופיל של מדדי הביצועים שלנו באמצעות branch-misses מונה הביצועים, שמתעד עקבות מחסנית שבהן החיזוי של הסתעפות היה שגוי. לאחר מכן, יצרנו ויזואליזציה של התוצאות באמצעות Google pprof, כמו שמוצג בהמשך:
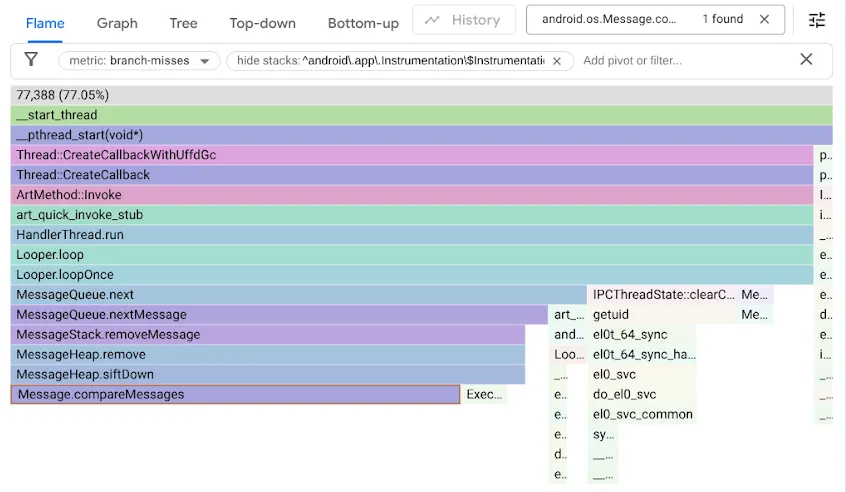
נזכיר שהקוד המקורי MessageQueue השתמש ברשימה מקושרת יחידה לתור המסודר. ההוספה תתבצע על ידי מעבר ברשימה לפי הסדר הממוין כחיפוש לינארי, עצירה ברכיב הראשון שמעבר לנקודת ההוספה וקישור הרכיב החדש Message לפניו. כדי להסיר את ה-Head, פשוט צריך לבטל את הקישור שלו. ב-DeliQueue נעשה שימוש ב-min-heap, שבו מוטציות מחייבות סידור מחדש של חלק מהרכיבים (העברה למעלה או למטה) עם מורכבות לוגריתמית במבנה נתונים מאוזן, שבו לכל השוואה יש סיכוי שווה להפנות את המעבר לצאצא שמאלי או לצאצא ימני. האלגוריתם החדש מהיר יותר באופן אסימפטוטי, אבל הוא חושף צוואר בקבוק חדש כי קוד החיפוש נתקע בחיפושים לא מוצלחים במחצית מהזמן.
הבנו שפספוסים של הסתעפויות מאטים את קוד הערימה שלנו, ולכן ביצענו אופטימיזציה של הקוד באמצעות תכנות ללא הסתעפויות:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}כדי להבין את האופטימיזציה, מפרקים את שתי הדוגמאות ב-Compiler Explorer ומשתמשים ב- LLVM-MCA, סימולטור מעבד שיכול ליצור ציר זמן משוער של מחזורי מעבד.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
שימו לב לענף המותנה היחיד, b.le, שמונע השוואה של השדות insertSeq אם התוצאה כבר ידועה מהשוואה של השדות when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
במקרה הזה, ההטמעה ללא הסתעפות דורשת פחות מחזורים והוראות אפילו מהנתיב הקצר ביותר בקוד עם הסתעפות – היא עדיפה בכל המקרים. היישום המהיר יותר, בנוסף לביטול של ענפים שחזו באופן שגוי, הביא לשיפור של פי 5 בחלק מהמדדים שלנו.
עם זאת, הטכניקה הזו לא תמיד מתאימה. בגישות שבהן לא משתמשים בענפים, בדרך כלל צריך לבצע עבודה שתושלך לפח, ואם הענף צפוי ברוב המקרים, העבודה המבוזבזת הזו עלולה להאט את הקוד. בנוסף, הסרה של ענף יוצרת לעיתים קרובות תלות בנתונים. מעבדים מודרניים מבצעים כמה פעולות בכל מחזור, אבל הם לא יכולים לבצע הוראה עד שהקלט שלה מהוראה קודמת מוכן. לעומת זאת, מעבד יכול לשער לגבי נתונים בענפים, ולעבוד מראש אם החיזוי של הענף נכון.
בדיקות ואימות
קשה מאוד לאמת את הנכונות של אלגוריתמים ללא נעילה.
בנוסף לבדיקות יחידה רגילות לאימות רציף במהלך הפיתוח, כתבנו גם בדיקות מאמץ קפדניות כדי לאמת את אי-השתנות של התור ולנסות לגרום למרוצי נתונים אם הם קיימים. במעבדות הבדיקה שלנו יכולנו להריץ מיליוני מקרים של בדיקות במכשירים מדומיים ובחומרה אמיתית.
באמצעות Java ThreadSanitizer (JTSan) instrumentation, יכולנו להשתמש באותן בדיקות גם כדי לזהות כמה מצבי מירוץ בנתונים בקוד שלנו. JTSan לא מצא מירוצי נתונים בעייתיים ב-DeliQueue, אבל – באופן מפתיע – זיהה שתי באגים של פעולות מקבילות ב-framework של Robolectric, ותיקנו אותם מיד.
כדי לשפר את היכולות שלנו לנפות באגים, יצרנו כלי ניתוח חדשים. בדוגמה הבאה מוצגת בעיה בקוד של פלטפורמת Android, שבה שרשור אחד מעמיס יתר על המידה על שרשור אחר עם Messages, וגורם להצטברות גדולה של בקשות שלא טופלו. אפשר לראות את זה ב-Perfetto בזכות תכונת המדידה MessageQueue שהוספנו.
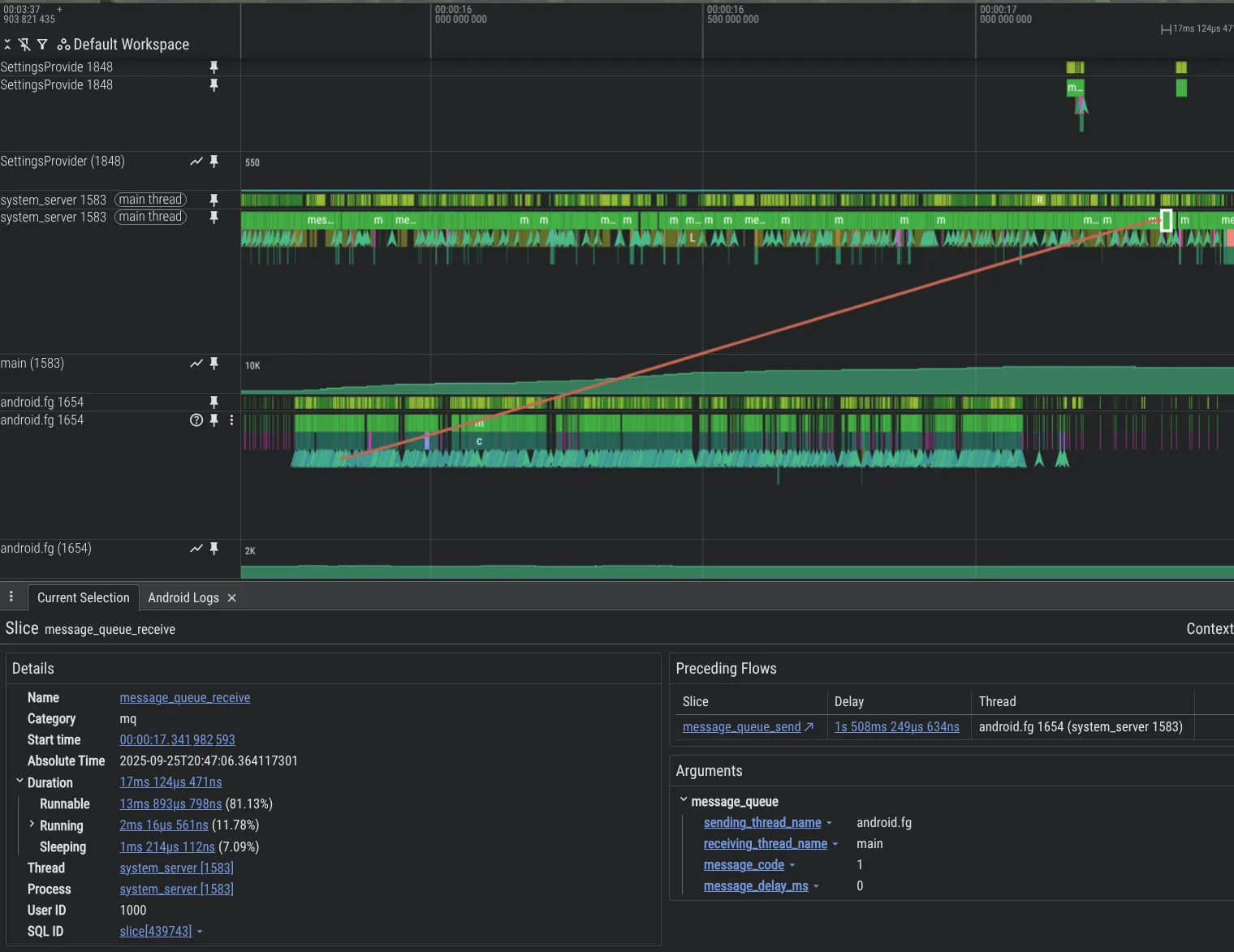
כדי להפעיל מעקב אחר MessageQueue בתהליך system_server, צריך לכלול את השורות הבאות בהגדרות של Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}השפעה
DeliQueue משפר את ביצועי האפליקציה והמערכת על ידי הסרת נעילות מ-MessageQueue.
- מדדים סינתטיים: הכנסות מרובות-הליכים לתורים עמוסים מהירות פי 5,000 בהשוואה ל-
MessageQueueמדור קודם, הודות לשיפורים במקביליות (מחסנית Treiber) ולהכנסות מהירות יותר (min-heap). - בעקבות של Perfetto שהתקבלו מבודקי בטא פנימיים, אנחנו רואים ירידה של 15% בזמן שבו השרשור הראשי של האפליקציה מושקע במאבק על נעילה.
- באותם מכשירי בדיקה, צמצום התחרות על נעילת המשאבים מוביל לשיפורים משמעותיים בחוויית המשתמש, כמו:
- -4% פריימים שהוחמצו באפליקציות.
- -7.7% מסגרות שהוחמצו בממשק המשתמש של המערכת ובאינטראקציות עם מרכז האפליקציות.
- ירידה של 9.1% בזמן שחלף מהפעלת האפליקציה ועד לציור הפריימים הראשונים, באחוזון ה-95.
השלבים הבאים
התכונה DeliQueue מושקת באפליקציות ב-Android 17. מפתחי אפליקציות צריכים לעיין במאמר בנושא הכנת האפליקציה ל-MessageQueue חדש ב-Android Developers Blog כדי ללמוד איך לבדוק את האפליקציות שלהם.
חומרי עזר
[1] Treiber, R.K., 1986. תכנות מערכות: התמודדות עם מקביליות. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 חדשות על מוצרים
חדשות על מוצריםאחד מהנושאים העומדים בראש סדרי העדיפויות שלנו ב-Google Play הוא לספק חוויה בטוחה באינטרנט ולהגן על המשתמשים מפני נזק.
Paul Feng • משך הקריאה: 2 דקות -
 חדשות על מוצרים
חדשות על מוצריםהיום אנחנו מציינים באופן רשמי חמש שנים מאז ההשקה של Jetpack Compose 1.0. מאז גרסה 1.0, שהשקתה הוכרזה ב-28 ביולי 2021, ועד לגרסה 1.11 האחרונה, ראינו את ממשקי ה-API מתפתחים באופן משמעותי במהלך השנים, ואנחנו רוצים לעצור לרגע ולחגוג.
Rebecca Franks, Nick Butcher, Loryn Hairston • 5 min read -

 חדשות על מוצרים
חדשות על מוצריםגרסה Android Studio Quail 2 יציבה ומוכנה לשימוש בסביבת ייצור. היא מביאה שינוי לסביבת הפיתוח המשולבת (IDE) עם תהליכי עבודה מקבילים של סוכנים, פרופילים של דליפות זיכרון שמשולבים באופן מקורי ותיקון קריסות בהתאם להקשר.
Amman Asfaw • משך הקריאה: 3 דקות
רוצים לקבל טיפים עדכניים לפיתוח Android ישירות לאימייל כל שבוע?
