

在 Android 17 中,指定 SDK 37 以上版本的應用程式會收到 MessageQueue 的新實作項目,該實作項目不含鎖定。新實作方式可提升效能並減少遺漏的影格,但可能會導致反映 MessageQueue 私有欄位和方法的用戶端中斷。如要進一步瞭解這項行為變更,以及如何減少影響,請參閱「MessageQueue 行為變更說明文件」。這篇技術網誌文章將概略介紹 MessageQueue 重新架構,以及如何使用 Perfetto 分析鎖定爭用問題。
每個 Android 應用程式的 UI 執行緒都由 Looper 驅動。它會從 MessageQueue 中提取工作,然後將工作分派給 Handler,並重複執行這個程序。過去二十年來,MessageQueue 一直使用單一監控鎖定 (即 synchronized 程式碼區塊) 保護其狀態。
Android 17 對這個元件進行重大更新,推出名為 DeliQueue 的無鎖實作項目。
這篇文章說明鎖定對 UI 效能的影響、如何使用 Perfetto 分析這些問題,以及用於改善 Android 主執行緒的特定演算法和最佳化措施。
問題:鎖定爭用和優先權反轉
舊版 MessageQueue 函式是受單一鎖定保護的優先順序佇列。如果背景執行緒在主執行緒執行佇列維護作業時發布訊息,背景執行緒就會封鎖主執行緒。
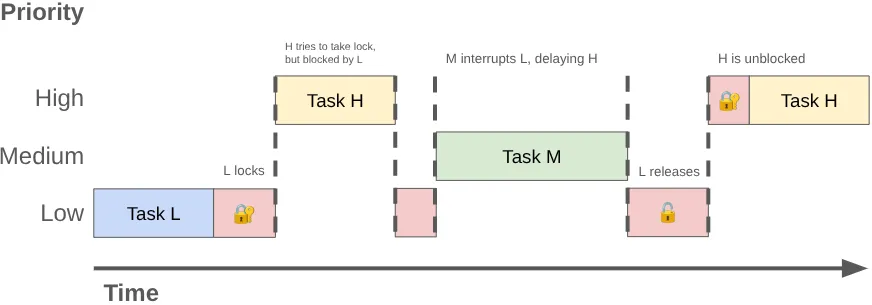
當兩個以上的執行緒爭奪同一項鎖的專屬使用權時,這稱為「鎖爭用」。這類爭用可能會導致「優先權反轉」,進而造成 UI 遭拒和其他效能問題。
當高優先順序的執行緒 (例如 UI 執行緒) 必須等待低優先順序的執行緒時,就會發生優先順序倒置。請參考以下順序:
- 低優先權背景執行緒會取得
MessageQueue鎖定,以發布其所完成工作結果。 - 中等優先順序的執行緒會變成可執行狀態,而 Kernel 的排程器會為其分配 CPU 時間,搶先處理低優先順序的執行緒。
- 高優先順序 UI 執行緒完成目前的工作,並嘗試從佇列讀取資料,但由於低優先順序執行緒持有鎖定,因此遭到封鎖。
低優先順序的執行緒會封鎖 UI 執行緒,而中優先順序的工作則會進一步延遲。
使用 Perfetto 分析爭用情形
您可以使用 Perfetto 診斷這些問題。在標準追蹤記錄中,遭監視器鎖定封鎖的執行緒會進入休眠狀態,而 Perfetto 會顯示指出鎖定擁有者的切片。
查詢追蹤資料時,請尋找名為「monitor contention with ...」的切片,後方會接續擁有鎖定的執行緒名稱,以及取得鎖定的程式碼位置。
個案研究:啟動器卡頓
舉例來說,假設使用者在 Pixel 手機上使用相機應用程式拍照後,立即瀏覽主畫面時發生卡頓,我們來分析這項追蹤記錄。下方的 Perfetto 螢幕截圖顯示導致影格遺失的事件:
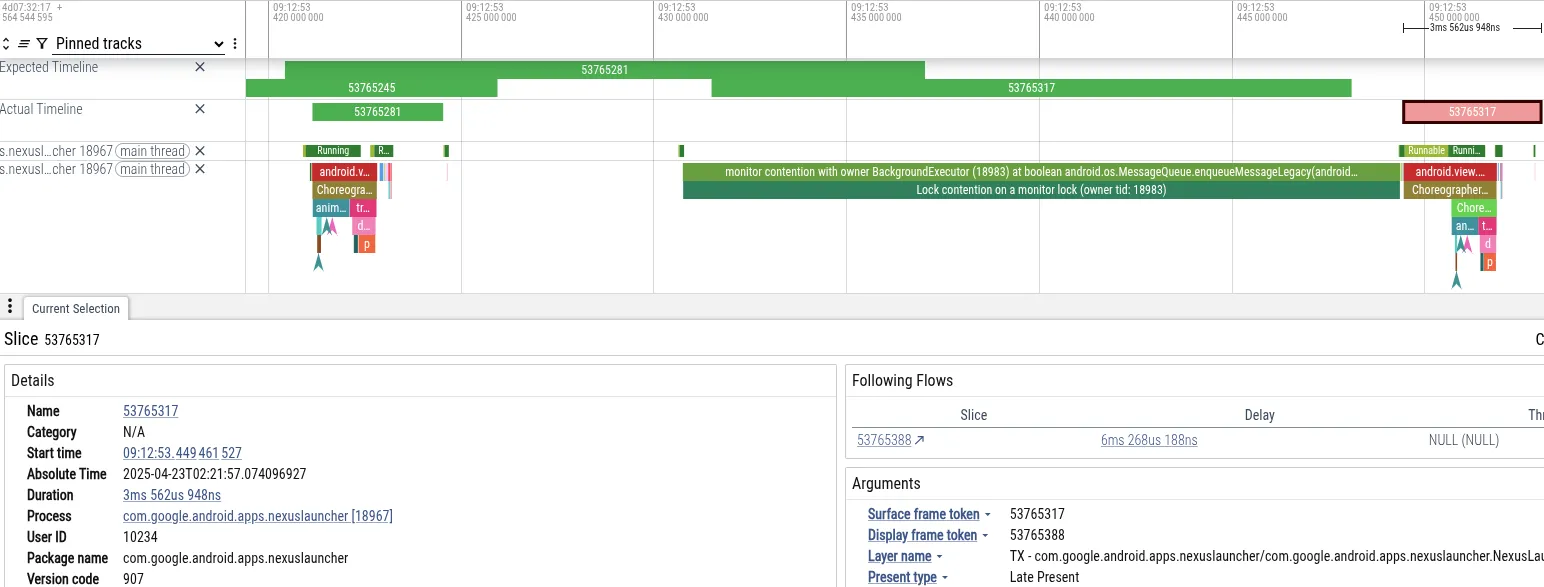
- 症狀:啟動器主執行緒錯過影格期限,封鎖時間為 18 毫秒,超過 60 Hz 算繪所需的 16 毫秒期限。
- 診斷:Perfetto 顯示主執行緒遭到
MessageQueue鎖定封鎖。鎖定由「BackgroundExecutor」執行緒擁有。 - 根本原因:BackgroundExecutor 會以 Process.THREAD_PRIORITY_BACKGROUND (極低優先順序) 執行。它執行的是非緊急工作 (檢查應用程式用量限制)。同時,中等優先順序的執行緒正在使用 CPU 時間處理來自相機的資料。OS 排程器搶占了 BackgroundExecutor 執行緒,以執行相機執行緒。
這個序列導致啟動器的 UI 執行緒 (高優先順序) 間接遭到攝影機工作執行緒 (中優先順序) 封鎖,而啟動器的背景執行緒 (低優先順序) 則無法釋放鎖定。
使用 PerfettoSQL 查詢追蹤記錄
您可以使用 PerfettoSQL 查詢追蹤記錄資料,找出特定模式。如果您有大量來自使用者裝置或測試的追蹤記錄,並要搜尋顯示問題的特定追蹤記錄,這項功能就非常實用。
舉例來說,這項查詢會找出與影格遺失 (卡頓) 同時發生的 MessageQueue 爭用情況:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
在這個較複雜的範例中,請彙整多個資料表的追蹤資料,找出應用程式啟動期間的 MessageQueue 爭用情形:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
您可以使用偏好的 LLM 撰寫 PerfettoSQL 查詢,找出其他模式。
在 Google,我們使用 BigTrace,在數百萬個追蹤記錄中執行 PerfettoSQL 查詢。我們也因此確認,我們在非正式場合聽到的情況,確實是系統性問題。資料顯示,MessageQueue鎖定爭用會影響整個生態系統的使用者,因此有必要進行基本的架構變更。
解決方法:無鎖並行
我們實作了無鎖資料結構,並使用單一記憶體作業而非互斥鎖,同步處理共用狀態的存取權,解決了 MessageQueue 爭用問題。如果至少有一個執行緒可以持續進展,無論其他執行緒的排程行為為何,資料結構或演算法就是無鎖定。這項屬性通常難以達成,而且對大多數程式碼而言,通常不值得追求。
不可分割的原始物件
無鎖定軟體通常仰賴硬體提供的不可分割讀取/修改/寫入基本類型。
在舊版 ARM64 CPU 上,原子作業會使用 Load-Link/Store-Conditional (LL/SC) 迴圈。CPU 會載入值並標記位址。如果另一個執行緒寫入該位址,儲存作業就會失敗,迴圈也會重試。由於執行緒可以持續嘗試並成功,不必等待其他執行緒,因此這項作業不會鎖定。
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr較新的 ARM 架構 (ARMv8.1) 支援大型系統擴充功能 (LSE),包括 Compare-And-Swap (CAS) 或 Load-And-Add 形式的指令 (如下所示)。在 Android 17 中,我們新增了對 Android 執行階段 (ART) 編譯器的支援,可偵測 LSE 是否受支援,並發出最佳化指令:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.在我們的基準測試中,使用 CAS 的高爭用程式碼比 LL/SC 變體快約 3 倍。
Java 程式設計語言透過 java.util.concurrent.atomic 提供原子基本型別,這些型別依賴這些和其他專屬 CPU 指令。
資料結構:DeliQueue
為移除 MessageQueue 的鎖定爭用情形,工程師設計了名為 DeliQueue 的新穎資料結構。DeliQueue 會將插入作業與處理作業分開:MessageMessage
Messages(Treiber 堆疊):無鎖定堆疊。任何執行緒都可以在這裡推送新的Messages,不會發生爭用情形。- 優先順序佇列 (最小堆積):要處理的
Messages堆積,由 Looper 執行緒專屬擁有 (因此不需要同步或鎖定即可存取)。
加入佇列:推送到 Treiber 堆疊
Messages 清單會保留在 Treiber 堆疊 [1] 中,這是使用 CAS 迴圈更新標頭指標的無鎖堆疊。
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}以 Java Concurrency in Practice [2] 為基礎的原始碼,可線上取得並發布至公有領域
任何製作人隨時都可以將新的 Message 推送到堆疊。這就像在熟食櫃檯抽號碼牌一樣,你的號碼取決於你何時出現,但取餐順序不一定與號碼相符。由於這是連結的堆疊,每個 Message 都是子堆疊,你可以追蹤標頭並向前迭代,查看任何時間點的 Message 佇列,即使在遍歷期間新增 Message,也不會看到任何推送到頂端的 Message。
Dequeue:大量轉移至最小堆積
如要尋找下一個要處理的 Message,Looper 會從 Treiber 堆疊處理新的 Message,方法是從堆疊頂端開始,反覆執行直到找到先前處理的最後一個 Message。Looper 遍歷堆疊時,會將 Message 插入以期限排序的最小堆積。由於 Looper 專屬擁有堆積,因此會排序及處理 Message,不需要鎖定或原子。

在堆疊中向下走動時,Looper也會從堆疊的 Message 建立連結返回前身,因此形成雙向連結清單。建立連結串列是安全的,因為指向堆疊下方的連結是透過 Treiber 堆疊演算法和 CAS 新增,而指向堆疊上方的連結只會由 Looper 執行緒讀取和修改。然後,這些反向連結會用於從堆疊中的任意點移除 Message,時間複雜度為 O(1)。
這項設計為生產者(將工作發布至佇列的執行緒) 提供 O (1) 插入作業,並為消費者(Looper) 提供攤銷 O (log N) 處理作業。
使用最小堆積排序 Message 也解決了舊版 MessageQueue 的基本缺陷,舊版 MessageQueue 會將 保存在單一連結清單 (以頂端為根)。Message在舊版實作中,從開頭移除為 O(1),但插入作業的最差情況為 O(N),因此過度負載的佇列會發生不良的擴充情形!反之,插入和移除最小堆積的作業會以對數方式擴展,因此平均效能具有競爭力,但尾部延遲時間表現優異。
舊版 (已鎖定) MessageQueue | DeliQueue | |
| 插入 | O(N) | O(1) 用於呼叫執行緒 O(logN) (適用於 |
| 從頭部移除 | O(1) | O(logN) |
在舊版佇列實作中,生產者和消費者會使用鎖定機制,協調對基礎單一連結清單的專屬存取權。在 DeliQueue 中,Treiber 堆疊會處理並行存取,而單一消費者會處理工作佇列的排序。
移除:透過墓碑實現一致性
DeliQueue 是混合資料結構,結合了無鎖定的 Treiber 堆疊和單一執行緒的最小堆積。在沒有全域鎖定的情況下,要讓這兩個結構保持同步是一項獨特的挑戰:訊息可能實際存在於堆疊中,但已從佇列中邏輯移除。
為解決這個問題,DeliQueue 使用一種稱為「墓碑化」的技術。每個 Message 會透過前後指標、堆積陣列中的索引,以及指出是否已移除的布林值旗標,追蹤自己在堆疊中的位置。當 Message 準備好執行時,Looper 執行緒會 CAS 其移除的標記,然後從堆積和堆疊中移除。
當其他執行緒需要移除 Message 時,系統不會立即從資料結構中擷取該項目,而是會執行下列步驟:
- 邏輯移除:執行緒會使用 CAS,以原子方式將
Message的移除標記從 false 設為 true。Message會保留在資料結構中,做為待移除的證據,也就是所謂的「墓碑」。一旦Message標記為待移除,DeliQueue 找到該項目時,就會視為該項目已不在佇列中。 - 延後清除:從資料結構中實際移除的作業由
Looper執行緒負責,並會延後到稍後執行。移除執行緒不會修改堆疊或堆積,而是將Message新增至另一個無鎖定空閒清單堆疊。 - 結構性移除:只有
Looper可以與堆積互動,或從堆疊中移除元素。喚醒時,會清除空閒清單並處理其中包含的Message。然後,每個Message都會從堆疊取消連結,並從堆積中移除。
這種方法可讓所有堆積管理作業維持單一執行緒,並盡量減少所需的並行作業和記憶體屏障,使重要路徑更快更簡單。
遍歷:良性 Java 記憶體模型資料競爭
大多數並行 API (例如 Java 標準程式庫中的 Future,或是 Kotlin 的 Job 和 Deferred) 都包含在工作完成前取消工作的機制。其中一個類別的執行個體會與基礎工作單元 1:1 相符,且對物件呼叫 cancel 會取消與其相關聯的特定作業。
現今的 Android 裝置配備多核心 CPU,並採用並行世代垃圾回收機制。但 Android 剛開發時,為每個工作單元分配一個物件的成本太高。因此,Android 的 Handler 支援透過多種 removeMessages 的多載取消作業,而不是移除特定 Message,而是移除符合指定條件的所有 Message。實務上,這需要疊代插入 removeMessages 呼叫前的所有 Message,並移除相符的項目。
向前疊代時,執行緒只需要一個排序的不可分割作業,即可讀取堆疊的目前開頭。之後,系統會使用一般欄位讀取作業尋找下一個 Message。如果 Looper 執行緒在移除 Message 時修改 next 欄位,Looper 的寫入作業和另一個執行緒的讀取作業就會不同步,這就是資料競爭。通常,資料競爭是嚴重的錯誤,可能會在應用程式中造成巨大問題,例如洩漏、無限迴圈、異常終止、凍結等。不過,在某些狹隘的條件下,資料競爭在 Java 記憶體模型中可能是良性的。假設我們從以下堆疊開始:

我們對標頭執行不可分割的讀取作業,並看到 A。A 的下一個指標會指向 B。在處理 B 的同時,迴圈器可能會移除 B 和 C,方法是將 A 更新為指向 C,然後指向 D。
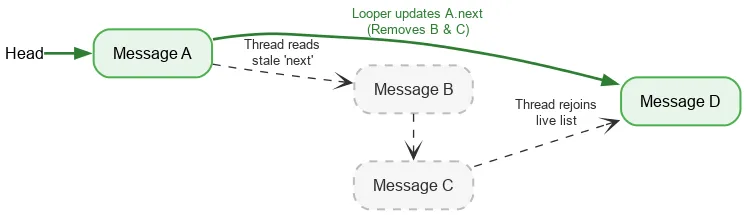
即使 B 和 C 在邏輯上已移除,B 仍會保留指向 C 的下一個指標,而 C 則會保留指向 D 的指標。讀取執行緒會繼續遍歷已卸離的移除節點,並最終在 D 重新加入即時堆疊。
我們設計 DeliQueue 來處理遍歷和移除之間的競爭,因此可安全地進行無鎖定疊代。
Quitting: Native refcount
Looper 是由原生分配項支援,必須在 Looper 終止後手動釋放。如果其他執行緒在 Looper 終止時新增 Message,可能會在釋放後使用原生分配項,造成記憶體安全違規。我們使用標記的參照計數來避免這種情況,其中原子的一位元用於指出 Looper 是否正在終止。
使用原生配置前,執行緒會讀取 refcount 原子。如果設定了終止位元,系統會傳回 Looper 正在終止,且不得使用原生配置。否則,系統會嘗試 CAS,以使用原生配置遞增作用中執行緒的數量。完成必要作業後,系統會遞減計數。如果遞增後遞減前設定了終止位元,且計數現在為零,系統就會喚醒 Looper 執行緒。
當 Looper 執行緒準備結束時,會使用 CAS 在原子中設定結束位元。如果 refcount 為 0,則可繼續釋放其原生配置。否則,它會自行停駐,因為當原生配置的最後一個使用者遞減 refcount 時,它會喚醒。這種做法表示 Looper 執行緒會等待其他執行緒的進度,但僅限於結束時。這只會發生一次,且對效能不敏感,並可讓其他程式碼完全無鎖定地使用原生配置。
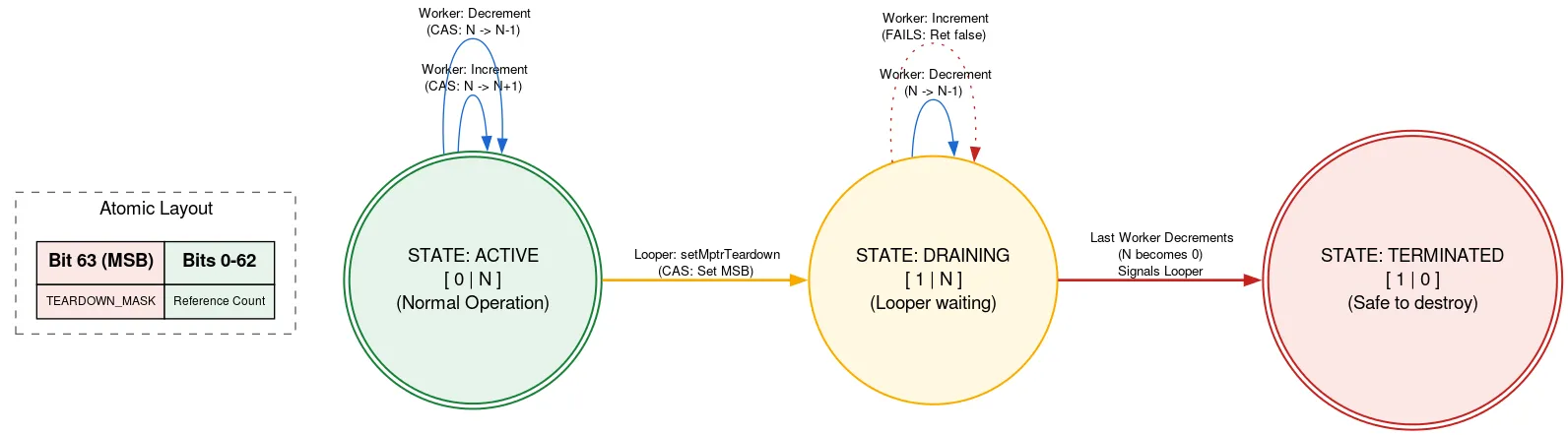
實作中還有許多其他技巧和複雜性。如要進一步瞭解 DeliQueue,請查看原始碼。
最佳化:無分支程式設計
開發及測試 DeliQueue 時,團隊執行了許多基準測試,並仔細分析新程式碼。使用 simpleperf 工具發現的問題之一,是因 Message 比較器程式碼而導致管道排空。
標準比較器會使用條件式跳轉,以下簡化了決定哪個 Message 先出現的條件:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}這段程式碼會編譯為條件式跳轉 (b.le 和 cbnz 指令)。CPU 遇到條件分支時,必須先計算條件,才能判斷是否要採用分支,因此 CPU 無法知道接下來要讀取哪個指令,只能使用「分支預測」技術進行猜測。以二元搜尋為例,每個步驟的分支方向都無法預測,因此預測結果很可能有一半是錯誤的。在搜尋和排序演算法 (例如用於最小堆積的演算法) 中,分支預測通常無效,因為猜錯的成本大於猜對的改善幅度。如果分支預測器猜錯,就必須捨棄假設預測值後所執行的工作,並從實際採取的路徑重新開始,這稱為「管線排清」。
為找出這個問題,我們使用 branch-misses 效能計數器分析基準,該計數器會記錄分支預測器猜錯的分支堆疊追蹤。接著,我們使用 Google pprof 將結果視覺化,如下所示:
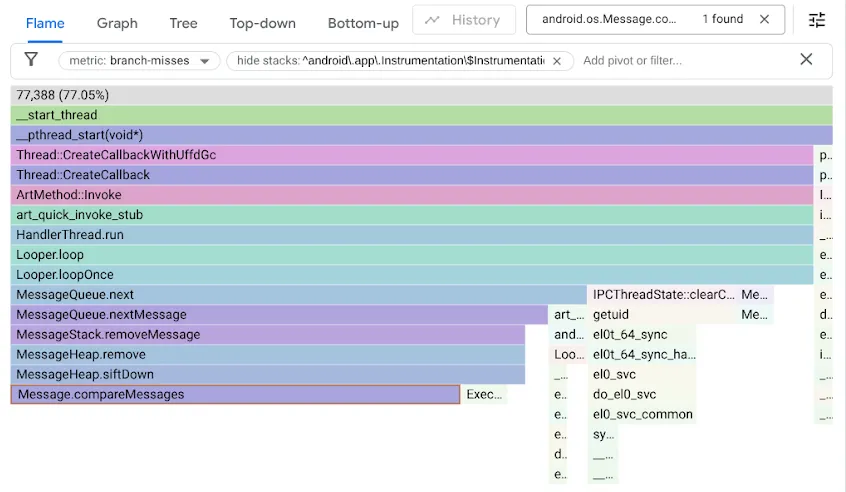
回想一下,原始的 MessageQueue 程式碼使用單一連結串列做為排序佇列。插入作業會以線性搜尋方式,依排序順序遍歷清單,在第一個超過插入點的元素停止,並將新的 Message 連結到該元素之前。從開頭移除元素只需要取消連結開頭即可。DeliQueue 則使用最小堆積,其中突變需要重新排序某些元素 (向上或向下篩選),在平衡資料結構中具有對數複雜度,任何比較都有機會將遍歷導向左子項或右子項。新演算法在漸近上更快,但會暴露新的瓶頸,因為搜尋程式碼會在分支遺漏時停滯一半的時間。
我們發現分支遺漏會拖慢堆積程式碼的速度,因此使用無分支程式設計最佳化程式碼:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}如要瞭解最佳化作業,請在 Compiler Explorer 中反組譯這兩個範例,並使用 LLVM-MCA (CPU 模擬器,可產生 CPU 週期預估時間軸)。
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
請注意條件分支 b.le,如果比較 when 欄位後已得知結果,則可避免比較 insertSeq 欄位。
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
在這裡,無分支實作所用的週期和指令,甚至比分支程式碼中最短的路徑還少,因此在所有情況下都比較好。實作速度加快,加上消除了預測錯誤的分支,我們在某些基準測試中獲得了 5 倍的改善!
不過,這項技術不一定適用於所有情況。一般來說,無分支方法需要執行會遭到捨棄的工作,如果分支大部分時間都是可預測的,這些浪費的工作可能會拖慢程式碼速度。此外,移除分支通常會產生資料依附元件。現代 CPU 每個週期會執行多項作業,但必須等到前一個指令的輸入內容準備就緒,才能執行指令。相較之下,CPU 可以推測分支中的資料,並在正確預測分支時提前作業。
測試與驗證
驗證無鎖演算法的正確性非常困難!
除了在開發期間進行持續驗證的標準單元測試外,我們也編寫了嚴格的壓力測試,以驗證佇列不變量,並嘗試誘發資料競爭 (如果存在)。在測試實驗室中,我們可以在模擬裝置和實際硬體上執行數百萬個測試執行個體。
透過 Java ThreadSanitizer (JTSan) 檢測,我們可以使用相同的測試,偵測程式碼中的部分資料競爭。JTSan 未在 DeliQueue 中發現任何有問題的資料競爭,但令人驚訝的是,它實際偵測到 Robolectric 架構中的兩個並行錯誤,我們隨即修正了這些錯誤。
為提升偵錯能力,我們建構了新的分析工具。以下範例顯示 Android 平台程式碼中的問題,其中一個執行緒會以 Message 讓另一個執行緒過載,導致大量積壓工作。由於我們新增了 MessageQueue 檢測功能,因此 Perfetto 會顯示這個問題。
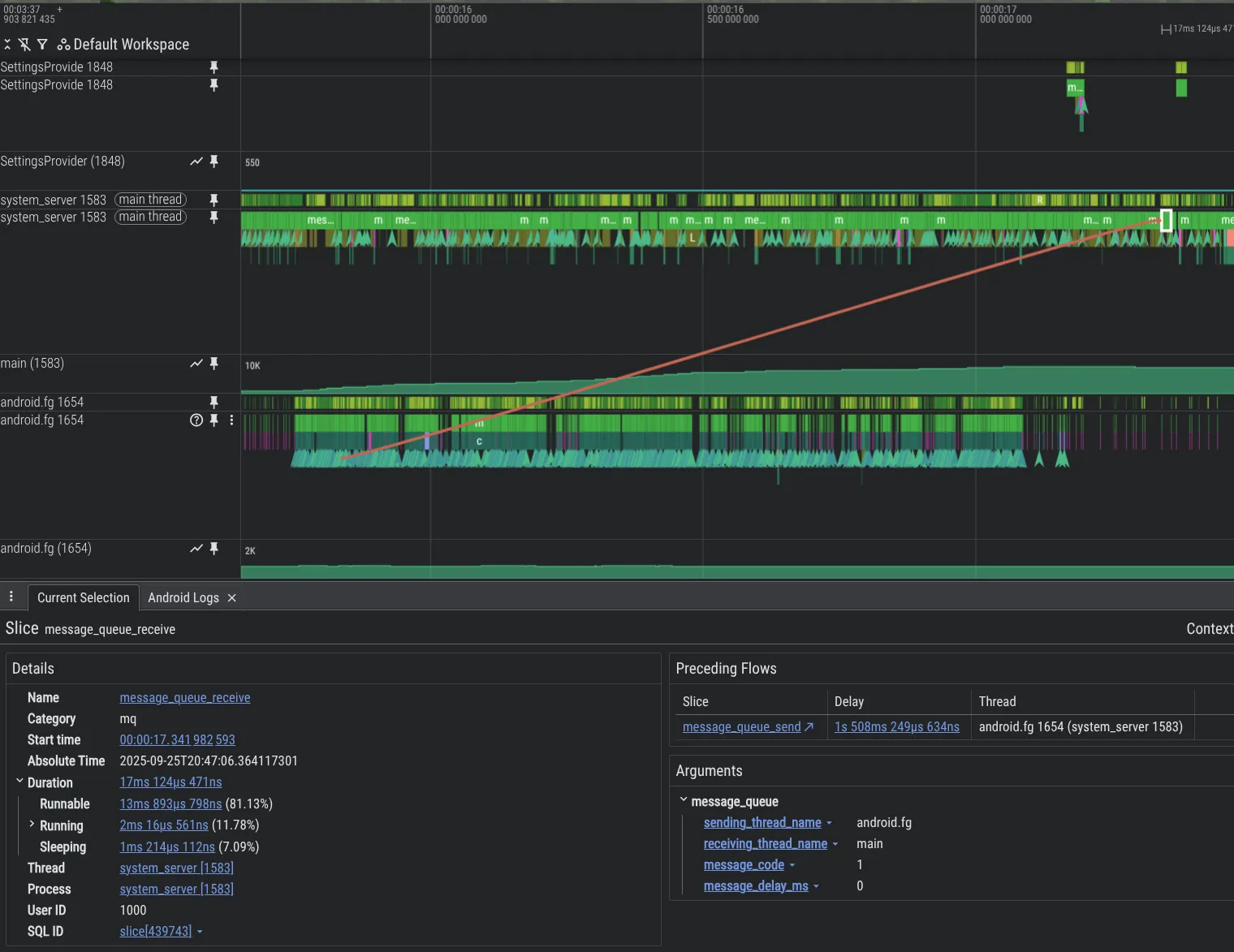
如要在 system_server 程序中啟用 MessageQueue 追蹤,請在 Perfetto 設定中加入下列內容:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}影響
DeliQueue 會移除 MessageQueue 中的鎖定,藉此提升系統和應用程式效能。
- 綜合基準:由於並行處理能力 (Treiber 堆疊) 提升,且插入速度 (最小堆積) 更快,因此與舊版
MessageQueue相比,多執行緒插入忙碌佇列的速度最多可提升 5,000 倍。 - 在從內部 Beta 版測試人員取得的 Perfetto 追蹤記錄中,我們發現應用程式主執行緒在鎖定爭用中花費的時間減少了 15%。
- 在相同的測試裝置上,減少鎖定爭用可大幅提升使用者體驗,例如:
- 應用程式中錯失的影格減少 4%。
- 系統 UI 和啟動器互動中,錯過的影格減少 7.7%。
- 應用程式啟動到繪製第一個影格的時間,在第 95 個百分位數減少 9.1%。
後續步驟
DeliQueue 將在 Android 17 中推出。應用程式開發人員應參閱 Android 開發人員網誌中「準備應用程式以支援新的無鎖定 MessageQueue」一文,瞭解如何測試應用程式。
參考資料
[1] Treiber, R.K.,1986 年。系統程式設計:處理平行處理。International Business Machines Incorporated、Thomas J. 華生研究中心。
[2] Goetz, B.、Peierls, T.、Bloch, J. Bowbeer, J.、Holmes, D.、及 Lea, D. (2006)。Java Concurrency in Practice。Addison-Wesley Professional。
撰寫者:
繼續閱讀
-



產品新訊
從擴增疊加層到完全沉浸式環境,Android XR 生態系統正在迅速擴展,Samsung Galaxy XR 也已於今天上市。
Stevan Silva, Vinny DaSilva • 3 分鐘可讀完
-


產品新訊
每年 Google I/O 大會都會發布生態系統和產品的最新消息與資源,包括 Android 開發。隨著開發工作轉向 AI 和代理程式輔助工具,我們也擴大產品陣容,無論您決定如何建構 Android 應用程式,都能獲得更完善的支援。
Simona Milanovic • 閱讀時間:2 分鐘
-

產品新訊
在 2026 年 Google I/O 大會上,我們展示了 Android 生態系統的最新進展,說明如何協助您提升應用程式品質,同時盡可能提高開發效率。
Ataul Munim • 3 分鐘可讀完
隨時掌握最新消息
每週透過電子郵件接收最新的 Android 開發洞察資訊。
