
Di Android 17, aplikasi yang menargetkan SDK 37 atau yang lebih tinggi akan menerima implementasi MessageQueue baru yang implementasinya bebas dari penguncian. Implementasi baru ini meningkatkan performa dan mengurangi frame yang terlewat, tetapi dapat merusak klien yang mencerminkan kolom dan metode pribadi MessageQueue. Untuk mempelajari lebih lanjut perubahan perilaku dan cara mengurangi dampaknya, lihat dokumentasi perubahan perilaku MessageQueue. Postingan blog teknis ini memberikan ringkasan tentang arsitektur ulang MessageQueue dan cara menganalisis masalah persaingan kunci menggunakan Perfetto.
Looper menggerakkan thread UI setiap aplikasi Android. Looper menarik tugas dari MessageQueue, mengirimkannya ke Handler, dan mengulanginya. Selama dua dekade, MessageQueue menggunakan satu kunci monitor (yaitu blok kode synchronized) untuk melindungi statusnya.
Android 17 memperkenalkan update signifikan pada komponen ini: implementasi bebas kunci bernama DeliQueue.
Postingan ini menjelaskan pengaruh kunci terhadap performa UI, cara menganalisis masalah ini dengan Perfetto, serta algoritma dan pengoptimalan khusus yang digunakan untuk meningkatkan kualitas thread utama Android.
Masalah: Persaingan Kunci dan Inversi Prioritas
Fungsi MessageQueue lama berfungsi sebagai antrean prioritas yang dilindungi oleh satu kunci. Jika thread latar belakang memposting pesan saat thread utama melakukan pemeliharaan antrean, thread latar belakang akan memblokir thread utama.
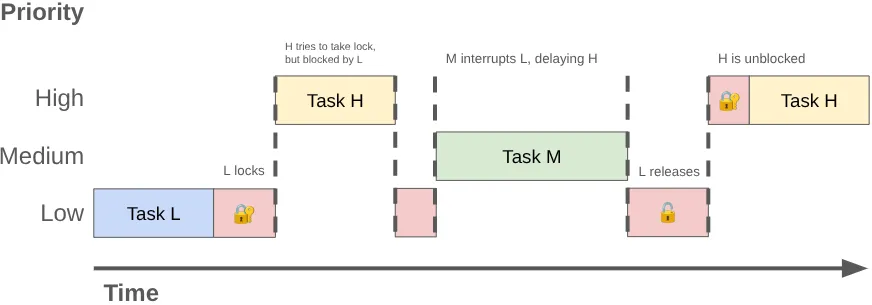
Jika dua atau beberapa thread bersaing untuk menggunakan kunci yang sama secara eksklusif, hal ini disebut Persaingan kunci. Persaingan ini dapat menyebabkan Inversi Prioritas, yang menyebabkan jank UI dan masalah performa lainnya.
Inversi prioritas dapat terjadi saat thread berprioritas tinggi (seperti thread UI) dibuat untuk menunggu thread berprioritas rendah. Pertimbangkan urutan ini:
- Thread latar belakang prioritas rendah mendapatkan kunci
MessageQueueuntuk memposting hasil pekerjaan yang telah dilakukannya. - Thread prioritas sedang menjadi dapat dijalankan dan penjadwal Kernel mengalokasikan waktu CPU untuknya, sehingga menghentikan thread prioritas rendah.
- Thread UI prioritas tinggi menyelesaikan tugasnya saat ini dan mencoba membaca dari antrean, tetapi diblokir karena thread prioritas rendah memegang kunci.
Thread prioritas rendah memblokir thread UI, dan pekerjaan prioritas sedang menundanya lebih lanjut.
Menganalisis pertentangan dengan Perfetto
Anda dapat mendiagnosis masalah ini menggunakan Perfetto. Dalam rekaman aktivitas standar, thread yang diblokir pada kunci monitor akan memasuki status tidur, dan Perfetto akan menampilkan slice yang menunjukkan pemilik kunci.
Saat Anda membuat kueri data rekaman aktivitas, cari slice bernama “monitor contention with …” diikuti dengan nama thread yang memiliki kunci dan situs kode tempat kunci diperoleh.
Studi kasus: Jank peluncur
Sebagai ilustrasi, mari kita analisis rekaman aktivitas saat pengguna mengalami jank saat membuka layar utama di ponsel Pixel segera setelah mengambil foto di aplikasi kamera. Di bawah, kita melihat screenshot Perfetto yang menampilkan peristiwa yang menyebabkan frame terlewat:
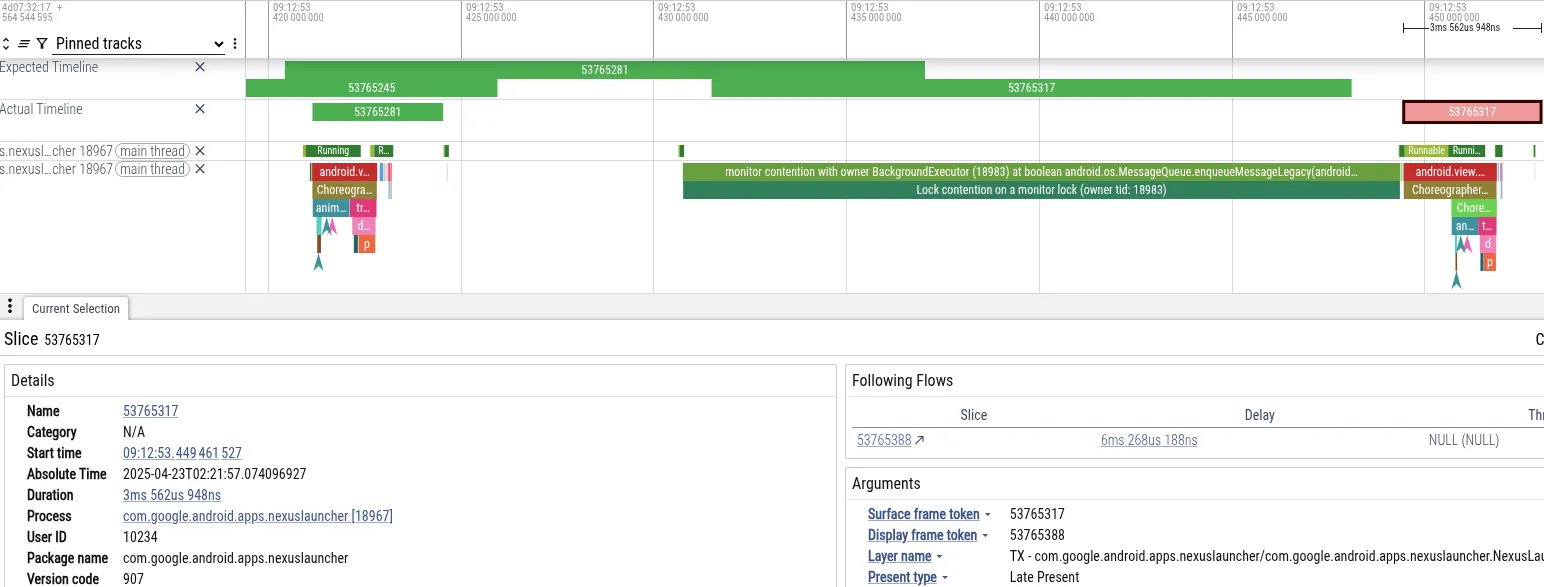
- Gejala: Thread utama Peluncur melewati batas waktu frame. Proses ini diblokir selama 18 md, yang melebihi batas waktu 16 md yang diperlukan untuk rendering 60 Hz.
- Diagnosis: Perfetto menunjukkan bahwa thread utama diblokir pada kunci
MessageQueue. Thread “BackgroundExecutor” memiliki kunci. - Penyebab Utama: BackgroundExecutor berjalan di Process.THREAD_PRIORITY_BACKGROUND (prioritas sangat rendah). Tugas yang dilakukan tidak mendesak (memeriksa batas penggunaan aplikasi). Secara bersamaan, thread prioritas sedang menggunakan waktu CPU untuk memproses data dari kamera. Penjadwal OS menghentikan sementara thread BackgroundExecutor untuk menjalankan thread kamera.
Urutan ini menyebabkan thread UI Peluncur (prioritas tinggi) diblokir secara tidak langsung oleh thread pekerja kamera (prioritas sedang), yang membuat thread latar belakang Peluncur (prioritas rendah) tidak dapat melepaskan kunci.
Membuat kueri rekaman aktivitas dengan PerfettoSQL
Anda dapat menggunakan PerfettoSQL untuk membuat kueri data rekaman aktivitas untuk pola tertentu. Tindakan ini berguna jika Anda memiliki banyak rekaman aktivitas dari perangkat atau pengujian pengguna, dan Anda mencari rekaman aktivitas tertentu yang menunjukkan masalah.
Misalnya, kueri ini menemukan persaingan MessageQueue yang bertepatan dengan frame yang terputus (jank):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
Dalam contoh yang lebih kompleks ini, gabungkan data rekaman aktivitas yang mencakup beberapa tabel untuk mengidentifikasi pertentangan MessageQueue selama startup aplikasi:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Anda dapat menggunakan LLM favorit Anda untuk menulis kueri PerfettoSQL guna menemukan pola lainnya.
Di Google, kami menggunakan BigTrace untuk menjalankan kueri PerfettoSQL di jutaan rekaman aktivitas. Dengan demikian, kami mengonfirmasi bahwa apa yang kami lihat secara anekdotal sebenarnya adalah masalah sistemik. Data tersebut mengungkapkan bahwa MessageQueue persaingan kunci memengaruhi pengguna di seluruh ekosistem, sehingga membuktikan perlunya perubahan arsitektur mendasar.
Solusi: konkurensi bebas kunci
Kami mengatasi masalah MessageQueue persaingan dengan menerapkan struktur data bebas kunci, menggunakan operasi memori atomik, bukan kunci eksklusif untuk menyinkronkan akses ke status bersama. Struktur data atau algoritma bebas kunci jika setidaknya satu thread selalu dapat membuat progres terlepas dari perilaku penjadwalan thread lainnya. Properti ini umumnya sulit dicapai, dan biasanya tidak layak untuk dikejar bagi sebagian besar kode.
Primitif atomik
Software bebas kunci sering kali mengandalkan primitif Baca-Modifikasi-Tulis atomik yang disediakan hardware.
Pada CPU ARM64 generasi lama, atomik menggunakan loop Load-Link/Store-Conditional (LL/SC). CPU memuat nilai dan menandai alamat. Jika thread lain menulis ke alamat tersebut, penyimpanan akan gagal, dan loop akan mencoba lagi. Karena thread dapat terus mencoba dan berhasil tanpa menunggu thread lain, operasi ini bebas dari penguncian.
ARM64 LL/SC loop example retry: ldxr x0, [x1] // Load exclusive from address x1 to x0 add x0, x0, #1 // Increment value by 1 stxr w2, x0, [x1] // Store exclusive. // w2 gets 0 on success, 1 on failure cbnz w2, retry // If w2 is non-zero (failed), branch to retr
Arsitektur ARM yang lebih baru (ARMv8.1) mendukung Large System Extensions (LSE) yang mencakup instruksi dalam bentuk Compare-And-Swap (CAS) atau Load-And-Add (ditunjukkan di bawah). Di Android 17, kami menambahkan dukungan ke compiler Android Runtime (ART) untuk mendeteksi kapan LSE didukung dan mengeluarkan instruksi yang dioptimalkan:
/ ARMv8.1 LSE atomic example ldadd x0, x1, [x2] // Atomic load-add. // Faster, no loop required.
Dalam tolok ukur kami, kode dengan persaingan tinggi yang menggunakan CAS mencapai peningkatan kecepatan ~3x dibandingkan dengan varian LL/SC.
Bahasa pemrograman Java menawarkan primitive atomik melalui java.util.concurrent.atomic yang mengandalkan petunjuk CPU khusus ini dan lainnya.
Struktur Data: DeliQueue
Untuk menghilangkan persaingan kunci dari MessageQueue, engineer kami merancang struktur data baru yang disebut DeliQueue. DeliQueue memisahkan penyisipan Message dari pemrosesan Message:
- Daftar
Messages(tumpukan Treiber): Tumpukan bebas kunci. Thread apa pun dapat mengirimkanMessagesbaru di sini tanpa persaingan. - Antrean prioritas (Min-heap): Heap
Messagesyang akan ditangani, dimiliki secara eksklusif oleh thread Looper (sehingga tidak diperlukan sinkronisasi atau penguncian untuk mengakses).
Enqueue: mendorong ke stack Treiber
Daftar Messages disimpan dalam stack Treiber [1], yaitu stack bebas kunci yang menggunakan loop CAS untuk mengupdate pointer head.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Kode sumber berdasarkan Java Concurrency in Practice [2], tersedia secara online dan dirilis ke domain publik
Produser mana pun dapat mengirimkan Message baru ke stack kapan saja. Hal ini seperti mengambil nomor antrean di konter makanan - nomor Anda ditentukan oleh waktu Anda datang, tetapi urutan Anda mendapatkan makanan tidak harus sama. Karena merupakan stack tertaut, setiap Message adalah sub-stack - Anda dapat melihat seperti apa antrean Message pada setiap titik waktu dengan melacak head dan melakukan iterasi ke depan - Anda tidak akan melihat Message baru yang didorong ke atas, meskipun ditambahkan selama penelusuran.
Dequeue: transfer massal ke min-heap
Untuk menemukan Message berikutnya yang akan ditangani, Looper memproses Message baru dari stack Treiber dengan menelusuri stack mulai dari atas dan melakukan iterasi hingga menemukan Message terakhir yang sebelumnya diproses. Saat Looper melintasi stack, Looper akan memasukkan Message ke dalam min-heap yang diurutkan berdasarkan batas waktu. Karena Looper secara eksklusif memiliki heap, Looper mengurutkan dan memproses Message tanpa penguncian atau atomik.

Saat menelusuri stack, Looper juga membuat link dari Message yang ditumpuk kembali ke pendahulunya, sehingga membentuk daftar yang ditautkan ganda. Membuat daftar tertaut aman karena link yang mengarah ke bawah stack ditambahkan melalui algoritma stack Treiber dengan CAS, dan link ke atas stack hanya dibaca dan diubah oleh thread Looper. Link kembali ini kemudian digunakan untuk menghapus Message dari titik arbitrer dalam stack dalam waktu O(1).
Desain ini menyediakan penyisipan O(1) untuk produsen (thread yang memposting pekerjaan ke antrean) dan pemrosesan O(log N) yang diamortisasi untuk konsumen (Looper).
Penggunaan min-heap untuk mengurutkan Messages juga mengatasi kekurangan mendasar dalam MessageQueue lama, tempat Messages disimpan dalam daftar tertaut tunggal (berakar di bagian atas). Dalam penerapan lama, penghapusan dari head adalah O(1), tetapi penyisipan memiliki kasus terburuk O(N) – penskalaan yang buruk untuk antrean yang kelebihan beban. Sebaliknya, penyisipan ke dan penghapusan dari min-heap diskalakan secara logaritmik, sehingga memberikan performa rata-rata yang kompetitif, tetapi benar-benar unggul dalam latensi ekor.
Lama (dikunci) MessageQueue | DeliQueue | |
| Sisipkan (Insert) | O(N) | O(1) untuk thread panggilan O(logN) untuk rangkaian pesan |
| Melepas dari kepala | O(1) | O(logN) |
Dalam penerapan antrean lama, produsen dan konsumen menggunakan kunci untuk mengoordinasikan akses eksklusif ke daftar tertaut tunggal yang mendasarinya. Di DeliQueue, stack Treiber menangani akses serentak, dan satu konsumen menangani pengurutan antrean tugasnya.
Penghapusan: konsistensi melalui catatan kematian
DeliQueue adalah struktur data hybrid, yang menggabungkan stack Treiber bebas kunci dengan min-heap berutas tunggal. Menjaga kedua struktur ini tetap tersinkronisasi tanpa kunci global menimbulkan tantangan unik: pesan mungkin ada secara fisik di stack, tetapi secara logis dihapus dari antrean.
Untuk mengatasi hal ini, DeliQueue menggunakan teknik yang disebut “tombstoning”. Setiap Message melacak posisinya dalam stack melalui pointer mundur dan maju, indeksnya dalam array heap, dan tanda boolean yang menunjukkan apakah telah dihapus. Saat Message siap dijalankan, thread Looper akan CAS flag yang dihapus, lalu menghapusnya dari heap dan stack.
Saat thread lain perlu menghapus Message, thread tersebut tidak langsung mengekstraknya dari struktur data. Sebagai gantinya, langkah-langkah berikut akan dilakukan:
- Penghapusan logis: thread menggunakan CAS untuk secara atomik menyetel flag penghapusan
Messagedari salah (false) ke benar (true).Messagetetap berada dalam struktur data sebagai bukti penghapusannya yang tertunda, yang disebut “tanda kuburan”. SetelahMessageditandai untuk dihapus, DeliQueue memperlakukannya seolah-olah tidak ada lagi dalam antrean setiap kali ditemukan. - Pembersihan yang ditangguhkan: Penghapusan sebenarnya dari struktur data adalah tanggung jawab thread
Looper, dan ditangguhkan hingga nanti. Daripada mengubah stack atau heap, thread penghapus menambahkanMessageke stack freelist bebas kunci lainnya. - Penghapusan struktural: Hanya
Looperyang dapat berinteraksi dengan heap atau menghapus elemen dari stack. Saat aktif, ia akan menghapus daftar bebas dan memprosesMessageyang ada di dalamnya. SetiapMessagekemudian dibatalkan tautannya dari tumpukan dan dihapus dari heap.
Pendekatan ini membuat semua pengelolaan heap menjadi satu thread. Hal ini meminimalkan jumlah operasi serentak dan penghalang memori yang diperlukan, sehingga jalur kritis menjadi lebih cepat dan sederhana.
Traversal: race kondisi model memori Java yang tidak berbahaya
Sebagian besar API konkurensi, seperti Future di library standar Java, atau Job dan Deferred Kotlin, menyertakan mekanisme untuk membatalkan tugas sebelum selesai. Instance salah satu class ini cocok 1:1 dengan unit pekerjaan yang mendasarinya, dan memanggil cancel pada objek akan membatalkan operasi tertentu yang terkait dengannya.
Perangkat Android saat ini memiliki CPU multi-core dan pengumpulan sampah memori serentak. Namun, saat Android pertama kali dikembangkan, alokasi satu objek untuk setiap unit kerja terlalu mahal. Oleh karena itu, Handler Android mendukung pembatalan melalui banyak kelebihan beban removeMessages - bukan menghapus Message tertentu, tetapi menghapus semua Message yang cocok dengan kriteria yang ditentukan. Dalam praktiknya, hal ini memerlukan iterasi melalui semua Message yang dimasukkan sebelum removeMessages dipanggil dan menghapus yang cocok.
Saat melakukan iterasi ke depan, thread hanya memerlukan satu operasi atomik yang diurutkan, untuk membaca head stack saat ini. Setelah itu, pembacaan kolom biasa digunakan untuk menemukan Message berikutnya. Jika thread Looper memodifikasi kolom next saat menghapus Message, penulisan Looper dan pembacaan thread lain tidak disinkronkan - ini adalah persaingan data. Biasanya, race data adalah bug serius yang dapat menyebabkan masalah besar di aplikasi Anda - kebocoran, loop tak terbatas, error, pembekuan, dan banyak lagi. Namun, dalam kondisi tertentu yang sempit, race data dapat tidak berbahaya dalam Java Memory Model. Misalkan kita mulai dengan tumpukan:

Kita melakukan pembacaan atomik head, dan melihat A. Penunjuk berikutnya A menunjuk ke B. Pada saat yang sama saat kami memproses B, looper dapat menghapus B dan C, dengan memperbarui A agar mengarah ke C, lalu D.
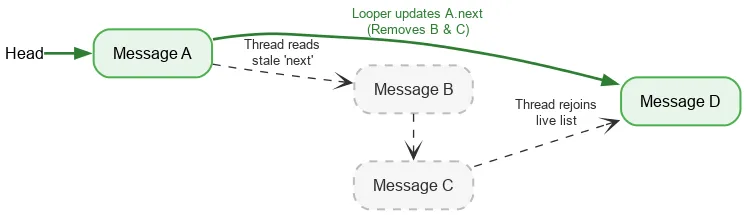
Meskipun B dan C dihapus secara logis, B mempertahankan pointer berikutnya ke C, dan C ke D. Thread pembacaan terus melintasi node yang dihapus dan dilepas, lalu bergabung kembali dengan stack aktif di D.
Dengan mendesain DeliQueue untuk menangani persaingan antara traversal dan penghapusan, kita memungkinkan iterasi yang aman dan bebas kunci.
Keluar: Native refcount
Looper didukung oleh alokasi native yang harus dibebaskan secara manual setelah Looper keluar. Jika thread lain menambahkan Message saat Looper keluar, thread tersebut dapat menggunakan alokasi native setelah dibebaskan, yang merupakan pelanggaran keamanan memori. Kami mencegah hal ini menggunakan refcount yang diberi tag, dengan satu bit operasi atomik digunakan untuk menunjukkan apakah Looper keluar.
Sebelum menggunakan alokasi native, thread membaca atom refcount. Jika bit keluar disetel, fungsi ini akan menampilkan bahwa Looper sedang keluar dan alokasi native tidak boleh digunakan. Jika tidak, CAS akan mencoba menambah jumlah thread aktif menggunakan alokasi native. Setelah melakukan apa yang perlu dilakukan, jumlah akan berkurang. Jika bit keluar ditetapkan setelah penambahan, tetapi sebelum pengurangan, dan jumlahnya sekarang nol, maka thread Looper akan diaktifkan.
Saat thread Looper siap keluar, thread tersebut menggunakan CAS untuk menyetel bit keluar dalam atom. Jika refcount adalah 0, maka dapat melanjutkan untuk membebaskan alokasi native-nya. Jika tidak, objek akan berhenti sendiri, mengetahui bahwa objek akan diaktifkan saat pengguna terakhir alokasi native mengurangi refcount. Pendekatan ini berarti thread Looper menunggu progres thread lain, tetapi hanya saat keluar. Hal itu hanya terjadi sekali dan tidak sensitif terhadap performa, serta membuat kode lain untuk menggunakan alokasi native sepenuhnya bebas dari penguncian.
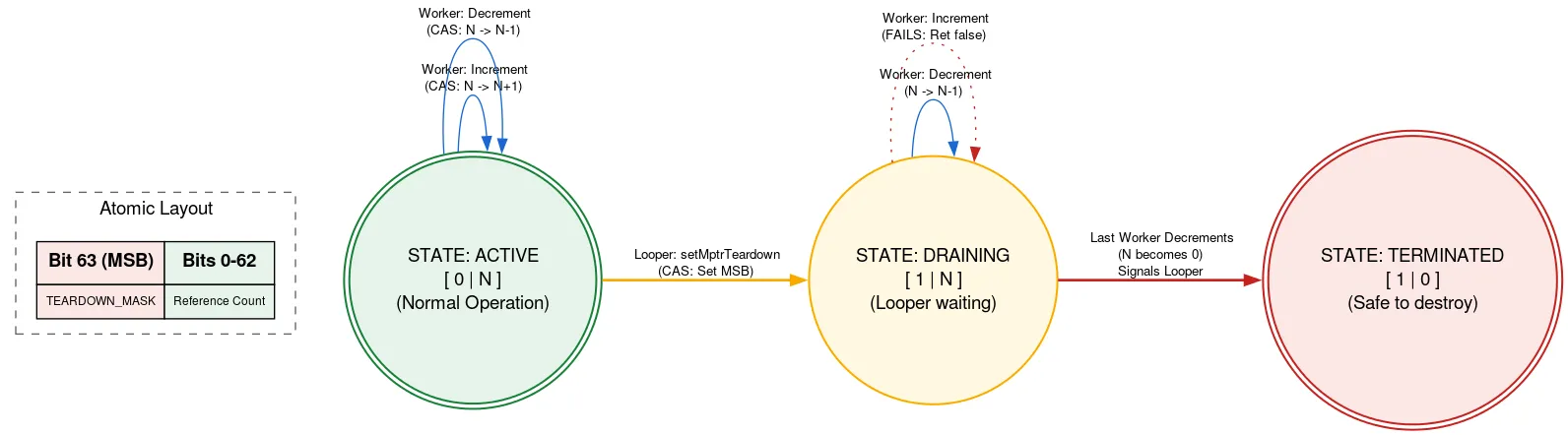
Ada banyak trik dan kompleksitas lain dalam penerapannya. Anda dapat mempelajari DeliQueue lebih lanjut dengan meninjau kode sumber.
Pengoptimalan: pemrograman tanpa cabang
Saat mengembangkan dan menguji DeliQueue, tim menjalankan banyak benchmark dan memprofilkan kode baru dengan cermat. Salah satu masalah yang diidentifikasi menggunakan alat simpleperf adalah penghapusan pipeline yang disebabkan oleh kode pembanding Message.
Komparator standar menggunakan lompatan bersyarat, dengan kondisi untuk memutuskan Message mana yang lebih dulu disederhanakan di bawah:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) { if (m1 == m2) { return 0; } // Primary queue order is by when. // Messages with an earlier when should come first in the queue. final long whenDiff = m1.when - m2.when; if (whenDiff > 0) return 1; if (whenDiff < 0) return -1; // Secondary queue order is by insert sequence. // If two messages were inserted with the same `when`, the one inserted // first should come first in the queue. final long insertSeqDiff = m1.insertSeq - m2.insertSeq; if (insertSeqDiff > 0) return 1; if (insertSeqDiff < 0) return -1; return 0; }
Kode ini dikompilasi ke lompatan bersyarat (instruksi b.le dan cbnz). Saat CPU menemukan cabang bersyarat, CPU tidak dapat mengetahui apakah cabang tersebut diambil hingga kondisi dihitung, sehingga CPU tidak tahu instruksi mana yang harus dibaca berikutnya, dan harus menebak, menggunakan teknik yang disebut prediksi cabang. Dalam kasus seperti penelusuran biner, arah percabangan akan berbeda secara tidak terduga di setiap langkah, sehingga kemungkinan setengah dari prediksi akan salah. Prediksi percabangan sering kali tidak efektif dalam algoritma penelusuran dan pengurutan (seperti yang digunakan dalam min-heap), karena biaya menebak salah lebih besar daripada peningkatan dari menebak dengan benar. Jika prediksi cabang salah, prediksi harus membuang pekerjaan yang dilakukan setelah mengasumsikan nilai yang diprediksi, dan memulai lagi dari jalur yang sebenarnya diambil - hal ini disebut pengosongan pipeline.
Untuk menemukan masalah ini, kami membuat profil tolok ukur menggunakan penghitung performa branch-misses, yang mencatat rekaman jejak stack saat prediktor cabang salah menebak. Kemudian, kami memvisualisasikan hasilnya dengan Google pprof, seperti yang ditunjukkan di bawah:
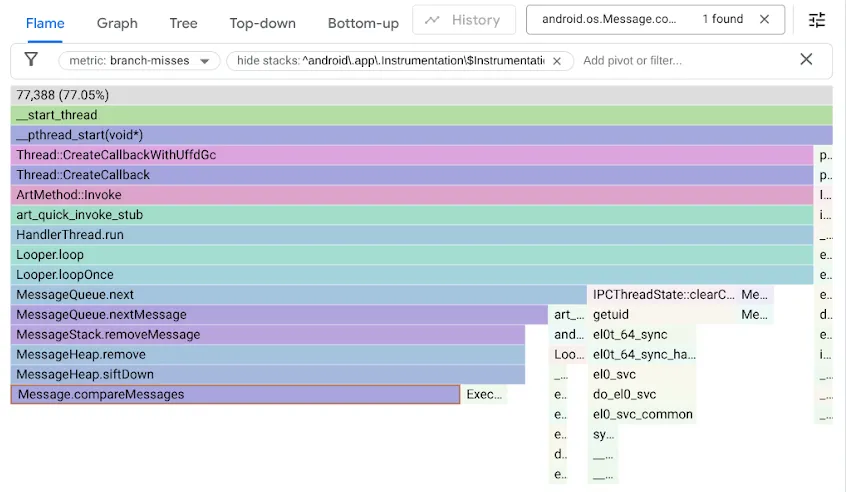
Ingatlah bahwa kode MessageQueue asli menggunakan daftar tertaut tunggal untuk antrean yang diurutkan. Penyisipan akan melintasi daftar dalam urutan yang diurutkan sebagai penelusuran linear, berhenti di elemen pertama yang melewati titik penyisipan dan menautkan Message baru di depannya. Untuk melepasnya dari kepala, cukup batalkan tautan kepala. Sementara itu, DeliQueue menggunakan min-heap, tempat mutasi memerlukan pengurutan ulang beberapa elemen (penyaringan ke atas atau ke bawah) dengan kompleksitas logaritmik dalam struktur data yang seimbang, tempat setiap perbandingan memiliki peluang yang sama untuk mengarahkan penelusuran ke turunan kiri atau ke turunan kanan. Algoritma baru ini secara asimtotik lebih cepat, tetapi memunculkan hambatan baru karena kode penelusuran terhenti pada kegagalan cabang setengah dari waktu.
Menyadari bahwa kegagalan percabangan memperlambat kode heap kami, kami mengoptimalkan kode menggunakan pemrograman bebas percabangan:
// Branchless Logic static int compareMessages(@NonNull Message m1, @NonNull Message m2) { final long when1 = m1.when; final long when2 = m2.when; final long insertSeq1 = m1.insertSeq; final long insertSeq2 = m2.insertSeq; // signum returns the sign (-1, 0, 1) of the argument, // and is implemented as pure arithmetic: // ((num >> 63) | (-num >>> 63)) final int whenSign = Long.signum(when1 - when2); final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2); // whenSign takes precedence over insertSeqSign, // so the formula below is such that insertSeqSign only matters // as a tie-breaker if whenSign is 0. return whenSign * 2 + insertSeqSign; }
Untuk memahami pengoptimalan, bongkar dua contoh di Compiler Explorer dan gunakan LLVM-MCA, simulator CPU yang dapat menghasilkan estimasi linimasa siklus CPU.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Perhatikan satu cabang kondisional, b.le, yang menghindari perbandingan kolom insertSeq jika hasilnya sudah diketahui dari perbandingan kolom when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Di sini, penerapan tanpa cabang memerlukan lebih sedikit siklus dan petunjuk daripada jalur terpendek melalui kode bercabang - lebih baik dalam semua kasus. Implementasi yang lebih cepat ditambah penghapusan cabang yang salah diprediksi menghasilkan peningkatan 5x dalam beberapa tolok ukur kami.
Namun, teknik ini tidak selalu dapat diterapkan. Pendekatan tanpa cabang umumnya memerlukan pekerjaan yang akan dibuang, dan jika cabang dapat diprediksi sebagian besar waktu, pekerjaan yang terbuang tersebut dapat memperlambat kode Anda. Selain itu, menghapus cabang sering kali menimbulkan dependensi data. CPU modern mengeksekusi beberapa operasi per siklus, tetapi tidak dapat mengeksekusi petunjuk hingga inputnya dari petunjuk sebelumnya siap. Sebaliknya, CPU dapat berspekulasi tentang data di cabang, dan bekerja lebih awal jika cabang diprediksi dengan benar.
Pengujian dan Validasi
Memvalidasi kebenaran algoritma bebas kunci sangatlah sulit.
Selain pengujian unit standar untuk validasi berkelanjutan selama pengembangan, kami juga menulis pengujian stres yang ketat untuk memverifikasi invarian antrean dan mencoba memicu kondisi persaingan data jika ada. Di lab pengujian kami, kami dapat menjalankan jutaan instance pengujian pada perangkat yang diemulasi dan pada hardware yang sebenarnya.
Dengan instrumentasi Java ThreadSanitizer (JTSan), kita dapat menggunakan pengujian yang sama untuk mendeteksi beberapa kondisi persaingan data dalam kode kita. JTSan tidak menemukan kebocoran data yang bermasalah di DeliQueue, tetapi - secara mengejutkan - justru mendeteksi dua bug konkurensi di framework Robolectric, yang segera kami perbaiki.
Untuk meningkatkan kemampuan pen-debug-an kami, kami membuat alat analisis baru. Di bawah ini adalah contoh yang menunjukkan masalah dalam kode platform Android di mana satu thread membebani thread lain dengan Message, sehingga menyebabkan backlog besar, yang terlihat di Perfetto berkat fitur instrumentasi MessageQueue yang kami tambahkan.
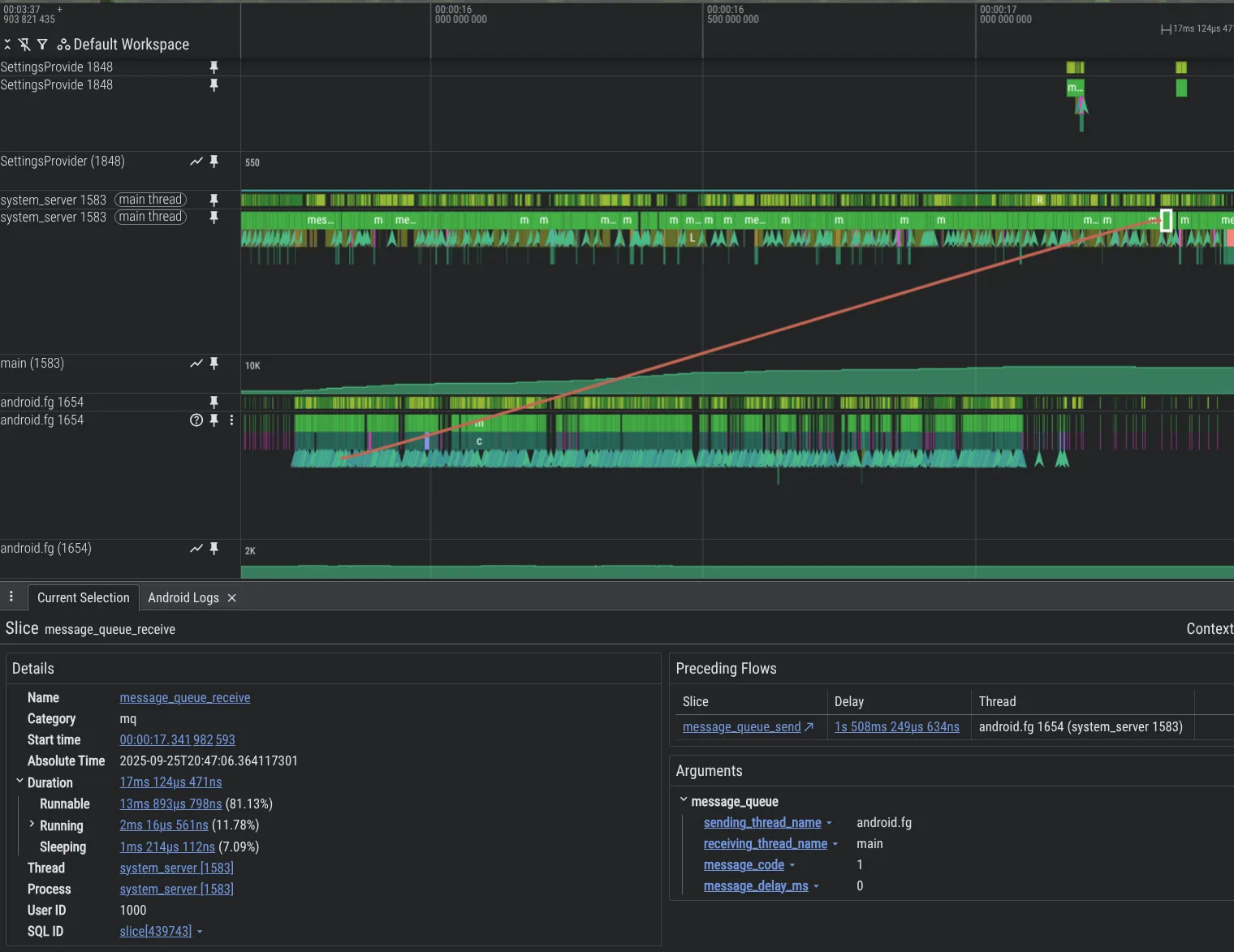
Untuk mengaktifkan pelacakan MessageQueue dalam proses system_server, sertakan yang berikut dalam konfigurasi Perfetto Anda:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Dampak
DeliQueue meningkatkan performa sistem dan aplikasi dengan menghilangkan kunci dari MessageQueue.
- Benchmark sintetis: penyisipan multi-thread ke dalam antrean yang sibuk hingga 5.000x lebih cepat daripada
MessageQueuelama, berkat peningkatan serentak (stack Treiber) dan penyisipan yang lebih cepat (min-heap). - Dalam rekaman aktivitas Perfetto yang diperoleh dari penguji beta internal, kami melihat penurunan sebesar 15% pada waktu thread utama aplikasi yang dihabiskan dalam persaingan kunci.
- Pada perangkat pengujian yang sama, pengurangan persaingan kunci menyebabkan peningkatan signifikan pada pengalaman pengguna, seperti:
- -4% frame yang terlewat di aplikasi.
- -7,7% frame terlewat dalam interaksi UI Sistem dan Peluncur.
- -9,1% dalam waktu dari mulai aplikasi hingga frame pertama digambar, pada persentil ke-95.
Langkah berikutnya
DeliQueue diluncurkan ke aplikasi di Android 17. Developer aplikasi harus meninjau artikel Menyiapkan aplikasi untuk MessageQueue bebas kunci baru di blog Android Developers untuk mempelajari cara menguji aplikasi mereka.
Referensi
[1] Treiber, R.K., 1986. Pemrograman sistem: Mengatasi paralelisme. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Ditulis oleh:
Lanjutkan membaca
-


Berita Produk
Setiap developer memiliki alur kerja dan kebutuhan AI yang unik, dan penting untuk dapat memilih cara AI membantu pengembangan Anda. Pada bulan Januari, kami memperkenalkan kemampuan untuk memilih model AI lokal atau jarak jauh guna mendukung fungsi AI di Android Studio
Matthew Warner • Waktu baca: 2 menit
-


Berita Produk
Android Studio Panda 3 kini stabil dan siap digunakan dalam produksi. Rilis ini memberi Anda lebih banyak kontrol dan penyesuaian atas alur kerja yang didukung AI, sehingga mempermudah pembuatan aplikasi Android berkualitas tinggi.
Matt Dyor • Waktu baca 3 menit
-

Berita Produk
Di Google, kami berkomitmen untuk menghadirkan model AI tercanggih langsung ke perangkat Android di saku Anda. Hari ini, dengan senang hati kami mengumumkan rilis model terbuka canggih terbaru kami: Gemma 4.
Caren Chang, David Chou • Waktu baca 3 menit
Terus dapatkan informasi
Dapatkan insight pengembangan Android terbaru yang dikirim ke kotak masuk Anda setiap minggu.
