


アプリにカスタム画像を追加すると、ユーザー エクスペリエンスが大幅に向上し、パーソナライズされ、ユーザー エンゲージメントを高めることができます。この記事では、Firebase AI Logic を使用した画像生成の 2 つの新機能について説明します。1 つは、現在プレビュー版の専用の Imagen 編集機能です。もう 1 つは、コンテキストに応じた画像生成や会話形式の画像生成向けに設計された Gemini 2.5 Flash Image(別名「Nano Banana」)の一般提供です。
Firebase AI Logic で生成された画像でユーザー エンゲージメントを向上させる
画像生成モデルを使用して、カスタム ユーザー プロフィール アバターを作成したり、パーソナライズされたビジュアル アセットを主要な画面フローに直接統合したりできます。
たとえば、Imagen には新しい編集機能(デベロッパー向けプレビュー版)があります。マスクを描画し、インペイントを使用してマスク領域内にピクセルを生成できるようになりました。また、アウトペイントを使用してマスクの外側にピクセルを生成することもできます。
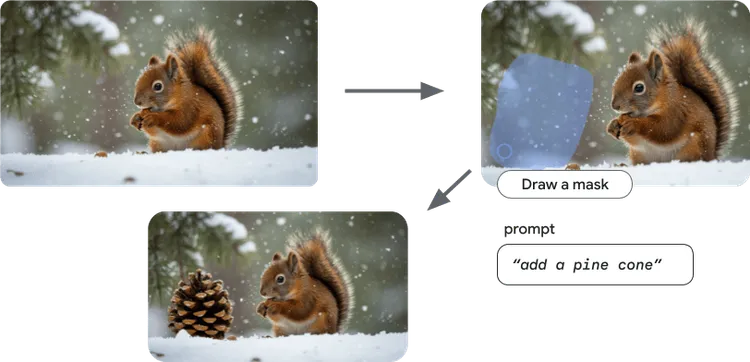
Imagen はインペイントをサポートしており、画像の一部のみを生成できます。
または、Gemini 2.5 Flash Image(別名 Nano Banana)は、Gemini モデルの拡張された世界知識と推論機能を使用して、コンテキストに関連する画像を生成できます。これは、ユーザーの現在のアプリ内エクスペリエンスに合わせた動的なイラストを作成する場合に最適です。
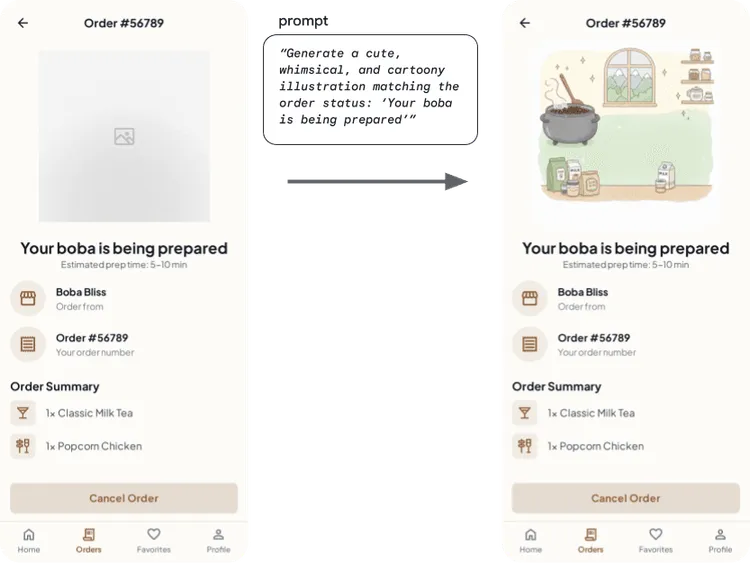
Gemini 2.5 Flash Image を使用して、アプリのコンテキストに関連する動的なイラストを作成します。
最後に、会話形式で反復的に画像を編集できるため、ユーザーは自然言語を使用して写真を編集できます。

Gemini 2.5 Flash Image を使用して、自然言語で写真を編集します。
AI をアプリケーションに統合する際は、AI の安全性について学ぶことが重要です。特に、アプリケーションのセキュリティ リスクを評価し、安全上のリスクを軽減するための調整を検討し、ユースケースに適した安全テストを実施し、ユーザー フィードバックを収集してコンテンツをモニタリングすることが重要です。
Imagen と Gemini: どちらを選ぶかはあなた次第
Gemini 2.5 Flash Image("Nano Banana")とImagenの違いは、主な焦点と高度な機能にあります。Gemini 2.5 Flash Image は、Gemini ファミリーの画像モデルとして、会話形式の画像編集に優れています。複数のイテレーションでコンテキストと被写体の整合性を維持し、「世界知識と推論」を活用してコンテキストに関連するビジュアルを作成したり、長いテキスト シーケンス内に正確なビジュアルを埋め込んだりできます。
Imagen は Google の特別な画像生成モデルで、クリエイティブなコントロールを強化するために設計されています。非常にフォトリアリスティックな出力、芸術的なディテール、特定のスタイルに特化しており、生成された画像のアスペクト比や形式を指定するための明示的なコントロールを提供します。
| Gemini 2.5 Flash Images (Nano Banana 🍌) | Imagen |
🌎 世界知識と推論により、コンテキストに関連性の高い画像を実現 💬 コンテキストを維持しながら会話形式で画像を編集 📖 長いテキスト シーケンス内に正確なビジュアルを埋め込む | 📐 生成された画像のアスペクト比または形式を指定
🖌️ インペイントとアウトペイントのマスクベースの編集をサポート。
🎚️ 生成された画像の詳細(品質、芸術的なディテール、特定のスタイル)をより細かく制御 |
アプリでの使用方法を見てみましょう。
Imagen を使用したインペイント
数か月前、Imagen の新しい編集機能をリリースしました。Imagen は画像生成のプロダクション レディになりましたが、編集機能はまだデベロッパー向けプレビュー版です。
Imagen の編集機能には、インペイントとアウトペイントのマスクベースの画像編集機能があります。この新機能により、ユーザーは画像全体を再生成することなく、画像の特定の領域を変更できます。つまり、画像の最適な部分を保持し、変更したい部分のみを変更できます。
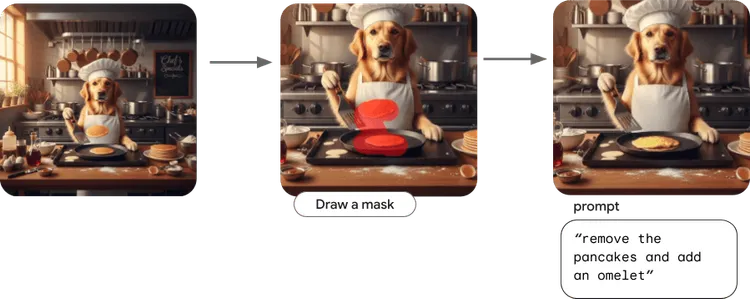
Imagen の編集機能を使用して、画像内の特定のターゲットを変更し、画像の残りの部分の整合性を保証します。
これらの変更は、元の画像のコア要素と全体的な整合性を維持しながら、マスク内の領域のみを変更して行われます。
Imagen でインペイントを実装するには、まず編集機能をサポートする特定の Imagen モデル imagen-3.0-capability-001 を初期化します。
// Copyright 2025 Google LLC.
// SPDX-License-Identifier: Apache-2.0
val editingModel =
Firebase.ai(backend = GenerativeBackend.vertexAI()).imagenModel(
"imagen-3.0-capability-001",
generationConfig = ImagenGenerationConfig(
numberOfImages = 1,
aspectRatio = ImagenAspectRatio.SQUARE_1x1,
imageFormat = ImagenImageFormat.jpeg(compressionQuality = 75),
),
)次に、インペイント関数を定義します。
// Copyright 2025 Google LLC.
// SPDX-License-Identifier: Apache-2.0
val prompt = "remove the pancakes and make it an omelet instead"
suspend fun inpaintImageWithMask(sourceImage: Bitmap, maskImage: Bitmap, prompt: String, editSteps: Int = 50): Bitmap {
val imageResponse = editingModel.editImage(
referenceImages = listOf(
ImagenRawImage(sourceImage.toImagenInlineImage()),
ImagenRawMask(maskImage.toImagenInlineImage()),
),
prompt = prompt,
config = ImagenEditingConfig(
editMode = ImagenEditMode.INPAINT_INSERTION,
editSteps = editSteps,
),
)
return imageResponse.images.first().asBitmap()
}sourceImage、maskImage、編集用のプロンプト、実行する編集ステップ数を指定します。
Android AI サンプル カタログの Imagen 編集サンプルで動作を確認できます。
また、Imagen はアウトペイントもサポートしており、モデルがマスクの外側のピクセルを生成できます。 Imagen の画像カスタマイズ機能を使用して、写真のスタイルを変更したり、写真内の被写体を更新したりすることもできます。詳しくは、Android デベロッパー向けドキュメントをご覧ください。
Gemini 2.5 Flash Image を使用した会話形式の画像生成
Gemini 2.5 Flash Image で画像を編集する方法の 1 つは、モデルのマルチターンのチャット機能を使用することです。
まず、モデルを初期化します。
// Copyright 2025 Google LLC.
// SPDX-License-Identifier: Apache-2.0
val model = Firebase.ai(backend = GenerativeBackend.googleAI()).generativeModel(
modelName = "gemini-2.5-flash-image",
// Configure the model to respond with text and images (required)
generationConfig = generationConfig {
responseModalities = listOf(ResponseModality.TEXT,
ResponseModality.IMAGE)
}
)
上記のマスクベースの Imagen メソッドと同様の結果を得るには、chat API を使用して Gemini 2.5 Flash Image との会話を開始します。
// Copyright 2025 Google LLC.
// SPDX-License-Identifier: Apache-2.0
// Initialize the chat
val chat = model.startChat()
// Load a bitmap
val source = ImageDecoder.createSource(context.contentResolver, uri)
val bitmap = ImageDecoder.decodeBitmap(source)
// Create the initial prompt instructing the model to edit the image
val prompt = content {
image(bitmap)
text("remove the pancakes and add an omelet")
}
// To generate an initial response, send a user message with the image and text prompt
var response = chat.sendMessage(prompt)
// Inspect the returned image
var generatedImageAsBitmap = response
.candidates.first().content.parts.filterIsInstance<ImagePart>().firstOrNull()?.image
// Follow up requests do not need to specify the image again
response = chat.sendMessage("Now, center the omelet in the pan")
generatedImageAsBitmap = response
.candidates.first().content.parts.filterIsInstance<ImagePart>().firstOrNull()?.image
Android AI サンプル カタログの Gemini 画像チャット サンプルで動作を確認できます。詳しくは、Android ドキュメントをご覧ください。
まとめ
Imagen と Gemini 2.5 Flash Image はどちらも強力な機能を備えており、特定のユースケースに応じて、アプリをパーソナライズしてユーザー エンゲージメントを高めるための理想的な画像生成モデルを選択できます。
-

 プロダクト ニュース
プロダクト ニュース革新的な AI 機能をアプリに実装したい Android デベロッパー向けに、強力な新機能がリリースされました。
Thomas Ezan • 所要時間: 3 分 -
 プロダクト ニュース
プロダクト ニュースこのたび、Gemini 3 モデル ファミリーに Gemini 3 Flash が加わりました。Gemini 3 Flash は、スピードを重視して構築された最先端のインテリジェンスを低コストで提供します。
Thomas Ezan • 所要時間: 2 分 -

 プロダクト ニュース
プロダクト ニュース3 月に、実際の Android 開発タスク向けの LLM リーダーボードである Android Bench をリリースしました。リリース以来、オープンウェイト モデルの評価や、リーダーボードへの費用と効率のディメンションの追加など、皆様からのフィードバックに基づいてベンチマークを強化してきました。
Zoe Lopez-Latorre • 所要時間: 3 分
Android 開発に関する最新の分析情報を毎週メールでお届けします。
