
Tin tức về sản phẩm
Nâng cao hiệu quả phát triển ứng dụng Android nhờ AI và cải thiện LLM bằng Android Bench
Đọc trong 2 phút


Chúng tôi muốn giúp bạn xây dựng các ứng dụng Android chất lượng cao một cách nhanh chóng và dễ dàng hơn. Một trong những cách chúng tôi giúp bạn tăng năng suất là cung cấp cho bạn AI. Chúng tôi biết bạn muốn AI thực sự hiểu rõ các sắc thái của nền tảng Android. Vì vậy, chúng tôi đã đo lường hiệu suất của các LLM khi thực hiện các tác vụ phát triển Android. Hôm nay, chúng tôi phát hành phiên bản đầu tiên của Android Bench, bảng xếp hạng chính thức của chúng tôi về các LLM để phát triển Android.
Mục tiêu của chúng tôi là cung cấp cho nhà sáng tạo mô hình một điểm chuẩn để đánh giá các chức năng của LLM cho hoạt động phát triển trên Android. Bằng cách thiết lập một cơ sở rõ ràng và đáng tin cậy cho hoạt động phát triển ứng dụng Android chất lượng cao, chúng tôi đang giúp các nhà sáng tạo mô hình xác định những điểm thiếu sót và đẩy nhanh quá trình cải thiện. Điều này giúp các nhà phát triển làm việc hiệu quả hơn với nhiều mô hình hữu ích hơn để lựa chọn cho sự hỗ trợ của AI. Cuối cùng, điều này sẽ dẫn đến các ứng dụng chất lượng cao hơn trong hệ sinh thái Android.
Được thiết kế dựa trên các tác vụ phát triển Android trong thực tế
Chúng tôi tạo điểm chuẩn bằng cách tuyển chọn một bộ tác vụ dựa trên nhiều lĩnh vực phát triển Android phổ biến. Nền tảng này bao gồm các thử thách thực tế với nhiều mức độ khó, được lấy từ các kho lưu trữ Android công khai trên GitHub. Các trường hợp bao gồm giải quyết các thay đổi gây lỗi trên các bản phát hành Android, các tác vụ dành riêng cho miền như kết nối mạng trên thiết bị đeo và di chuyển sang phiên bản mới nhất của Jetpack Compose, v.v.
Mỗi quy trình đánh giá đều cố gắng để LLM khắc phục vấn đề được báo cáo trong tác vụ, sau đó chúng tôi xác minh bằng cách sử dụng các kiểm thử đơn vị hoặc kiểm thử đo lường. Phương pháp độc lập với mô hình này cho phép chúng tôi đo lường khả năng điều hướng các cơ sở mã phức tạp, hiểu các phần phụ thuộc và giải quyết những vấn đề mà bạn gặp phải hằng ngày.
Chúng tôi đã xác thực phương pháp này với một số nhà sản xuất LLM, bao gồm cả JetBrains.
"Đo lường tác động của AI đối với Android là một thách thức lớn, vì vậy, thật tuyệt khi thấy một khung đo lường hợp lý và thực tế như thế này. Mặc dù chúng tôi đang tích cực tự đánh giá hiệu suất, nhưng Android Bench là một bổ sung độc đáo và đáng hoan nghênh. Phương pháp này chính xác là kiểu đánh giá nghiêm ngặt mà nhà phát triển Android cần ngay lúc này".
– Kirill Smelov, Trưởng nhóm Tích hợp AI tại JetBrains.
Kết quả kiểm thử hiệu suất Android đầu tiên
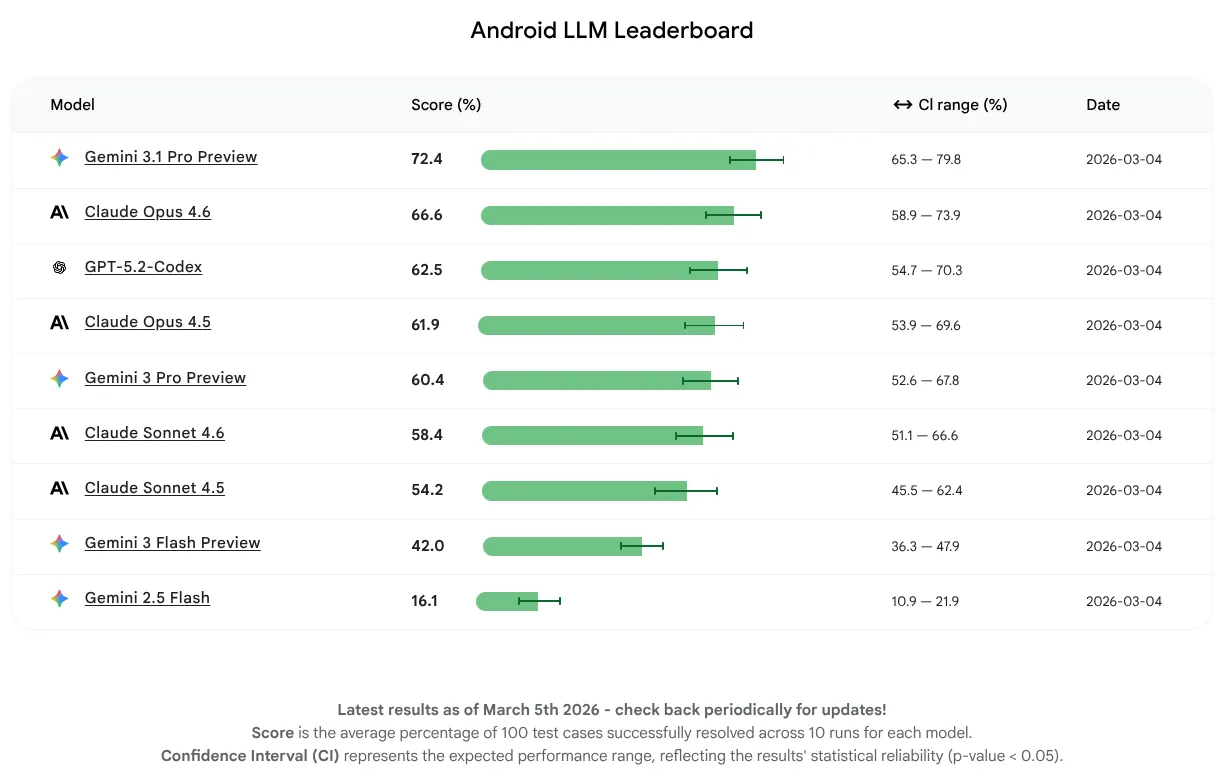
Trong bản phát hành ban đầu này, chúng tôi chỉ muốn đo lường hiệu suất của mô hình và không tập trung vào việc sử dụng tác nhân hoặc công cụ. Các mô hình này đã hoàn thành thành công từ 16 đến 72% số nhiệm vụ. Đây là một phạm vi rộng cho thấy một số LLM đã có kiến thức cơ bản vững chắc về Android, trong khi những LLM khác có nhiều dư địa để cải thiện. Bất kể các mô hình hiện đang ở giai đoạn nào, chúng tôi vẫn kỳ vọng sẽ tiếp tục cải thiện khi khuyến khích các nhà sản xuất LLM nâng cao mô hình của họ để phát triển trên Android.
LLM có điểm trung bình cao nhất trong bản phát hành đầu tiên này là Gemini 3.1 Pro, tiếp theo là Claude Opus 4.6. Bạn có thể dùng thử tất cả các mô hình mà chúng tôi đã đánh giá để hỗ trợ AI cho các dự án Android của mình bằng cách sử dụng khoá API trong phiên bản ổn định mới nhất của Android Studio.
Đảm bảo tính minh bạch cho nhà phát triển và nhà sản xuất mô hình ngôn ngữ lớn (LLM)
Chúng tôi coi trọng phương pháp minh bạch và cởi mở, vì vậy, chúng tôi đã công khai phương pháp, tập dữ liệu và bộ kiểm thử của mình trên GitHub.
Một thách thức đối với mọi điểm chuẩn công khai là nguy cơ ô nhiễm dữ liệu, trong đó các mô hình có thể đã thấy các nhiệm vụ đánh giá trong quá trình huấn luyện. Chúng tôi đã áp dụng các biện pháp để đảm bảo kết quả của chúng tôi phản ánh suy luận thực sự thay vì ghi nhớ hoặc đoán, bao gồm cả việc xem xét thủ công kỹ lưỡng các quỹ đạo của tác nhân hoặc tích hợp một chuỗi canary để ngăn chặn việc huấn luyện.
Trong tương lai, chúng tôi sẽ tiếp tục phát triển phương pháp của mình để duy trì tính toàn vẹn của tập dữ liệu, đồng thời cải thiện điểm chuẩn cho các bản phát hành sau này, chẳng hạn như tăng số lượng và độ phức tạp của các tác vụ.
Chúng tôi rất mong chờ những cải tiến mà Android Bench có thể mang lại cho tính năng hỗ trợ dựa trên AI về lâu dài. Tầm nhìn của chúng tôi là thu hẹp khoảng cách giữa ý tưởng và mã chất lượng. Chúng tôi đang xây dựng nền tảng cho một tương lai mà dù bạn có tưởng tượng ra điều gì, bạn cũng có thể xây dựng điều đó trên Android.
Tác giả:
Tiếp tục đọc
-

Tin tức về sản phẩm
Google I/O 2026 có 17 thông báo quan trọng dành cho nhà phát triển Android, tập trung vào năng suất do tác nhân dẫn dắt, Compose First làm tiêu chuẩn giao diện người dùng và nội dung nghe nhìn hiệu suất cao cũng như hoạt động phát triển thích ứng cho hệ sinh thái ngày càng mở rộng.
Matthew McCullough • Đọc trong 8 phút
-

Tin tức về sản phẩm
Hôm nay, trong sự kiện The Android Show, chúng tôi đã thông báo rằng Android đang chuyển đổi từ một hệ điều hành sang một hệ thống thông minh, tạo ra nhiều cơ hội hơn để tương tác với các ứng dụng của bạn.
Matthew McCullough • Đọc trong 4 phút
-

Tin tức về sản phẩm
Hôm nay, chúng tôi sẽ nâng cao hoạt động phát triển Android bằng Gemma 4, mô hình nguồn mở tiên tiến mới nhất của chúng tôi, được thiết kế với khả năng suy luận phức tạp và gọi công cụ tự động.
Matthew McCullough • Đọc trong 2 phút
Nhận thông tin cập nhật
Nhận thông tin chi tiết mới nhất về hoạt động phát triển trên Android trong hộp thư đến của bạn mỗi tuần.
