

Android 17 では、SDK 37 以上をターゲットとするアプリは、実装がロックフリーである MessageQueue の新しい実装を受け取ります。新しい実装では、パフォーマンスが向上し、フレームの欠落が減少しますが、MessageQueue の非公開フィールドとメソッドを反映するクライアントが破損する可能性があります。動作の変更と影響を軽減する方法について詳しくは、MessageQueue の動作の変更に関するドキュメントをご覧ください。この技術ブログ投稿では、MessageQueue の再アーキテクチャの概要と、Perfetto を使用してロック競合の問題を分析する方法について説明します。
Looper は、すべての Android アプリケーションの UI スレッドを駆動します。MessageQueue から作業を取得し、Handler にディスパッチして、繰り返します。20 年間、MessageQueue は単一のモニターロック(synchronized コードブロック)を使用して状態を保護していました。
Android 17 では、このコンポーネントに大幅なアップデートが導入されています。DeliQueue という名前のロックフリー実装です。
この投稿では、ロックが UI パフォーマンスに与える影響、Perfetto を使用してこれらの問題を分析する方法、Android メインスレッドの改善に使用される特定のアルゴリズムと最適化について説明します。
問題: ロックの競合と優先度の逆転
以前の MessageQueue は、単一のロックで保護された優先キューとして機能していました。メインスレッドがキューのメンテナンスを実行している間にバックグラウンド スレッドがメッセージを投稿すると、バックグラウンド スレッドがメインスレッドをブロックします。
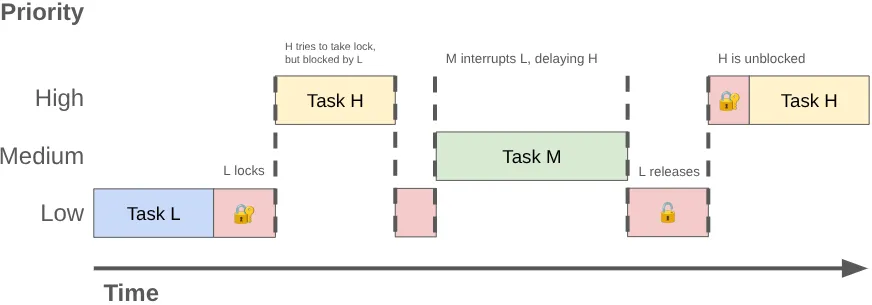
2 つ以上のスレッドが同じロックの排他使用を競合している状態を、ロック競合と呼びます。この競合により、優先順位の逆転が発生し、UI ジャンクなどのパフォーマンスの問題につながる可能性があります。
優先度逆転は、優先度の高いスレッド(UI スレッドなど)が優先度の低いスレッドを待つように設定されている場合に発生する可能性があります。次のシーケンスを考えてみましょう。
- 優先度の低いバックグラウンド スレッドが
MessageQueueロックを取得して、実行した作業の結果を投稿します。 - 中優先度のスレッドが実行可能になり、カーネルのスケジューラが CPU 時間を割り当て、低優先度のスレッドをプリエンプトします。
- 優先度の高い UI スレッドが現在のタスクを完了し、キューからの読み取りを試みますが、優先度の低いスレッドがロックを保持しているためブロックされます。
優先度の低いスレッドが UI スレッドをブロックし、優先度中程度の作業がさらに遅延させます。
Perfetto を使用して競合を分析する
これらの問題は Perfetto を使用して診断できます。標準トレースでは、モニターロックでブロックされたスレッドはスリープ状態になり、Perfetto にはロックの所有者を示すスライスが表示されます。
トレースデータをクエリするときは、「monitor contention with ...」という名前のスライスを探します。このスライスには、ロックを所有するスレッドの名前と、ロックが取得されたコードサイトが続きます。
ケーススタディ: ランチャーのジャンク
たとえば、Google Pixel でカメラアプリで写真を撮った直後にホーム画面に移動したときに、ジャンクが発生したトレースを分析してみましょう。下の画像は、Perfetto のスクリーンショットで、フレーム落ちにつながったイベントを示しています。
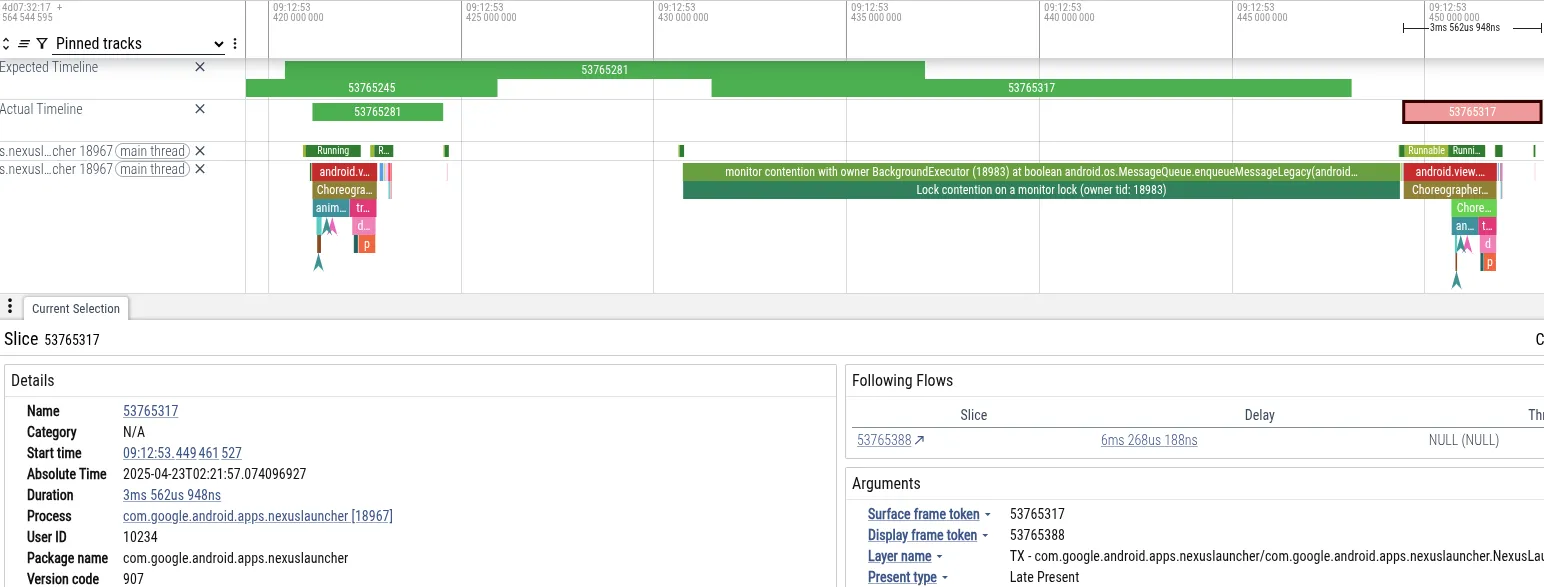
- 症状: ランチャーのメインスレッドがフレームの期限に間に合わなかった。18 ミリ秒ブロックされました。これは、60 Hz レンダリングに必要な 16 ミリ秒の期限を超えています。
- 診断: Perfetto は、
MessageQueueロックでブロックされたメインスレッドを示しました。「BackgroundExecutor」スレッドがロックを所有していました。 - 根本原因: BackgroundExecutor は Process.THREAD_PRIORITY_BACKGROUND(非常に低い優先度)で実行されます。緊急でないタスク(アプリの使用制限の確認)を実行しました。同時に、中優先度のスレッドが CPU 時間を使用してカメラからのデータを処理していました。OS スケジューラが BackgroundExecutor スレッドをプリエンプトして、カメラ スレッドを実行しました。
このシーケンスにより、ランチャーの UI スレッド(高優先度)がカメラ ワーカー スレッド(中優先度)によって間接的にブロックされ、ランチャーのバックグラウンド スレッド(低優先度)がロックを解除できなくなっていました。
PerfettoSQL を使用してトレースをクエリする
PerfettoSQL を使用して、特定のパターンについてトレースデータをクエリできます。これは、ユーザー デバイスやテストから大量のトレースがあり、問題を示す特定のトレースを検索する場合に便利です。
たとえば、次のクエリは、フレームのドロップ(ジャンク)と同時に発生した MessageQueue の競合を検出します。
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
このより複雑な例では、複数のテーブルにまたがるトレースデータを結合して、アプリの起動時の MessageQueue の競合を特定します。
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
お気に入りの LLM を使用して PerfettoSQL クエリを作成し、他のパターンを見つけることができます。
Google では、BigTrace を使用して、数百万のトレースに対して PerfettoSQL クエリを実行しています。その結果、これまで個別に確認されていた事象が、実際にはシステム全体の問題であることが確認されました。データから、MessageQueue ロック競合がエコシステム全体にわたってユーザーに影響を与えていることが明らかになり、アーキテクチャの根本的な変更の必要性が裏付けられました。
解決策: ロックフリーの同時実行
MessageQueue の競合の問題は、ロックフリーのデータ構造を実装し、排他ロックではなくアトミック メモリ オペレーションを使用して共有状態へのアクセスを同期することで解決しました。データ構造またはアルゴリズムは、他のスレッドのスケジューリング動作に関係なく、少なくとも 1 つのスレッドが常に進行できる場合、ロックフリーです。このプロパティは一般的に達成が難しく、ほとんどのコードでは追求する価値がありません。
アトミック プリミティブ
ロックフリー ソフトウェアは、ハードウェアが提供するアトミックな読み取り / 変更 / 書き込みプリミティブに依存することがよくあります。
以前の世代の ARM64 CPU では、アトミックは Load-Link/Store-Conditional(LL/SC)ループを使用していました。CPU は値を読み込み、アドレスをマークします。別のスレッドがそのアドレスに書き込むと、ストアは失敗し、ループが再試行されます。スレッドは別のスレッドを待たずに再試行して成功できるため、このオペレーションはロックフリーです。
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr新しい ARM アーキテクチャ(ARMv8.1)は、Compare-And-Swap(CAS)または Load-And-Add(以下を参照)の形式の命令を含む Large System Extensions(LSE)をサポートしています。Android 17 では、LSE がサポートされているかどうかを検出し、最適化された命令を発行する Android ランタイム(ART)コンパイラへのサポートを追加しました。
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Google のベンチマークでは、CAS を使用する高競合コードは LL/SC バリアントよりも約 3 倍高速化しています。
Java プログラミング言語は、これらの特殊な CPU 命令に依存するアトミック プリミティブを java.util.concurrent.atomic を介して提供します。
データ構造: DeliQueue
MessageQueue からロック競合を削除するために、Google のエンジニアは DeliQueue という新しいデータ構造を設計しました。DeliQueue は、Message の挿入と Message の処理を分離します。
Messages(Treiber スタック)のリスト: ロックフリー スタック。どのスレッドも、競合することなく新しいMessagesをここにプッシュできます。- 優先度キュー(最小ヒープ): 処理する
Messagesのヒープ。Looper スレッドが独占的に所有しているため、アクセスに同期やロックは必要ありません。
エンキュー: Treiber スタックへのプッシュ
Messages のリストは、CAS ループを使用してヘッド ポインタを更新するロックフリー スタックである Treiber スタック [1] に保持されます。
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Java Concurrency in Practice [2] に基づくソースコード。オンラインで入手可能で、パブリック ドメインとしてリリースされています。
プロデューサーはいつでも新しい Message をスタックにプッシュできます。これは、デリのカウンターでチケットを引くようなものです。番号は到着した時間によって決まりますが、料理を受け取る順番は必ずしも番号順ではありません。リンクされたスタックであるため、すべての Message はサブスタックです。ヘッドを追跡して前方に反復処理することで、任意の時点での Message キューを確認できます。トラバーサル中に新しい Message が追加されても、それらが上部にプッシュされることはありません。
Dequeue: 最小ヒープへの一括転送
処理する次の Message を見つけるために、Looper は Treiber スタックから新しい Message を処理します。スタックの先頭から開始して、以前に処理した最後の Message が見つかるまでスタックを歩行して反復処理します。Looper がスタックをトラバースすると、Message が期限順の最小ヒープに挿入されます。Looper はヒープを独占的に所有しているため、ロックやアトミックなしで Message を順序付けして処理します。

スタックをたどる際に、Looper はスタックされた Message からその先行処理へのリンクも作成し、二重リンク リストを形成します。リンクされたリストの作成は安全です。スタックの下を指すリンクは CAS を使用した Treiber スタック アルゴリズムで追加され、スタックの上を指すリンクは Looper スレッドによって読み取りと変更のみが行われるためです。これらのバックリンクは、スタック内の任意のポイントから Message を O(1) 時間で削除するために使用されます。
この設計では、プロデューサー(キューに作業を投稿するスレッド)に対して O(1) の挿入が提供され、コンシューマー(Looper)に対して O(log N) の処理が償却されます。
最小ヒープを使用して Message を順序付けすることで、従来の MessageQueue の根本的な欠陥(Message が単一リンクリスト(ルートは最上位)に保持されていた)も解消されます。以前の実装では、先頭からの削除は O(1) でしたが、挿入の最悪ケースは O(N) でした。過負荷のキューではスケーリングがうまくいきません。逆に、最小ヒープへの挿入と最小ヒープからの削除は対数的にスケーリングされるため、平均パフォーマンスは競合他社と同程度ですが、テール レイテンシでは優れています。
以前のバージョン(ロック済み)MessageQueue | DeliQueue | |
| 挿入 | O(N) | 呼び出しスレッドの O(1)
|
| 頭から削除 | O(1) | O(logN) |
以前のキュー実装では、プロデューサーとコンシューマーはロックを使用して、基盤となる単一リンクリストへの排他アクセスを調整していました。DeliQueue では、Treiber スタックが同時アクセスを処理し、単一のコンシューマーがワークキューの順序付けを処理します。
削除: トゥームストーンによる整合性
DeliQueue は、ロックフリーの Treiber スタックとシングル スレッドの最小ヒープを結合したハイブリッド データ構造です。グローバル ロックなしでこの 2 つの構造を同期させるには、メッセージがスタックには物理的に存在しているが、キューからは論理的に削除されているという固有の課題があります。
この問題を解決するために、DeliQueue は「tombstoning」という手法を使用します。各 Message は、後方ポインタと前方ポインタ、ヒープの配列内のインデックス、削除されたかどうかを示すブール値フラグを介して、スタック内の位置を追跡します。Message の実行準備が整うと、Looper スレッドは削除フラグを CAS してから、ヒープとスタックから削除します。
別のスレッドが Message を削除する必要がある場合、データ構造からすぐに抽出されません。代わりに、次の手順が実行されます。
- 論理削除: スレッドは CAS を使用して、
Messageの削除フラグを false から true にアトミックに設定します。Messageは、削除保留の証拠としてデータ構造に残ります(いわゆる「墓石」)。削除対象としてMessageにフラグが設定されると、DeliQueue はMessageが見つかるたびに、キューに存在しないものとして扱います。 - 遅延クリーンアップ: データ構造からの実際の削除は
Looperスレッドの責任であり、後まで延期されます。削除スレッドは、スタックやヒープを変更するのではなく、別のロックフリーのフリーリスト スタックにMessageを追加します。 - 構造の削除:
Looperのみがヒープを操作したり、スタックから要素を削除したりできます。スリープから復帰すると、フリーリストをクリアし、含まれていたMessageを処理します。各Messageはスタックからリンクが解除され、ヒープから削除されます。
このアプローチでは、ヒープのすべての管理がシングル スレッドで行われます。これにより、必要な同時オペレーションとメモリバリアの数が最小限に抑えられ、クリティカル パスが高速化され、簡素化されます。
トラバーサル: 無害な Java メモリモデルのデータ競合
Java 標準ライブラリの Future や Kotlin の Job や Deferred など、ほとんどの同時実行 API には、作業が完了する前にキャンセルするメカニズムが含まれています。これらのクラスのインスタンスは、基盤となる作業の単位と 1 対 1 で一致します。オブジェクトで cancel を呼び出すと、関連付けられた特定のオペレーションがキャンセルされます。
今日の Android デバイスには、マルチコア CPU と同時実行の世代別ガベージ コレクションが搭載されています。しかし、Android が最初に開発されたとき、作業単位ごとに 1 つのオブジェクトを割り当てるのはコストが高すぎました。そのため、Android の Handler は、特定の Message を削除するのではなく、removeMessages の多数のオーバーロードを介してキャンセルをサポートします。つまり、指定された条件に一致するすべての Message を削除します。実際には、removeMessages が呼び出される前に挿入されたすべての Message を反復処理し、一致するものを削除する必要があります。
順方向に反復処理する場合、スレッドはスタックの現在のヘッドを読み取るために、順序付けられたアトミック オペレーションを 1 つだけ必要とします。その後、通常のフィールド読み取りを使用して次の Message を見つけます。Looper スレッドが Message を削除しながら next フィールドを変更すると、Looper の書き込みと別のスレッドの読み取りが同期されなくなります。これはデータ競合です。通常、データ競合はアプリに大きな問題(リーク、無限ループ、クラッシュ、フリーズなど)を引き起こす可能性のある深刻なバグです。ただし、特定の狭い条件では、Java メモリモデル内でデータ競合が問題にならないことがあります。次のようなスタックから始めるとします。

ヘッドのアトミック読み取りを実行し、A を確認します。A の次のポインタは B を指します。B を処理するのと同時に、ルーパーは A を C、D の順にポイントするように更新することで、B と C を削除する可能性があります。
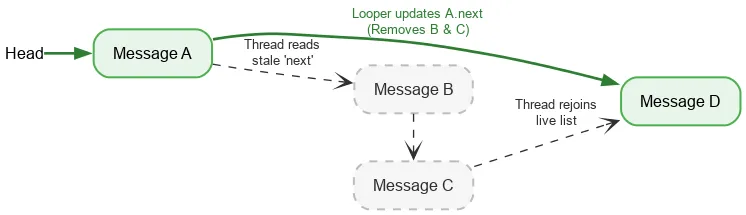
B と C は論理的に削除されますが、B は C への次のポインタを保持し、C は D への次のポインタを保持します。読み取りスレッドは、切り離された削除済みノードをトラバースし続け、最終的に D でライブ スタックに再結合します。
DeliQueue は、走査と削除の間の競合を処理するように設計されているため、安全なロックフリーの反復処理が可能です。
終了: ネイティブ参照カウント
Looper はネイティブ割り当てによってバックアップされます。Looper が終了したら、手動で解放する必要があります。Looper が終了している間に他のスレッドが Message を追加している場合、解放後にネイティブ割り当てを使用する可能性があり、メモリ安全性の違反となります。これを防ぐため、タグ付き参照カウントを使用します。この参照カウントでは、アトミックの 1 ビットを使用して Looper が終了しているかどうかを示します。
ネイティブ割り当てを使用する前に、スレッドが refcount アトミックを読み取ります。終了ビットが設定されている場合、Looper が終了しており、ネイティブ割り当てを使用できないことを返します。そうでない場合は、ネイティブ割り当てを使用してアクティブなスレッドの数を増やす CAS を試みます。必要な処理を行った後、カウントを減らします。終了ビットがインクリメント後、デクリメント前に設定され、カウントがゼロになった場合、Looper スレッドをウェイクアップします。
Looper スレッドが終了する準備ができたら、CAS を使用してアトミックの終了ビットを設定します。refcount が 0 の場合、ネイティブ割り当ての解放に進むことができます。それ以外の場合は、ネイティブ割り当ての最後のユーザーが refcount を減分したときにウェイクアップされることを認識して、自身をパークします。このアプローチでは、Looper スレッドは他のスレッドの進行状況を待機しますが、終了時に限られます。これは 1 回のみ発生し、パフォーマンスに影響しません。また、ネイティブ割り当てを使用する他のコードは完全にロックフリーのままになります。
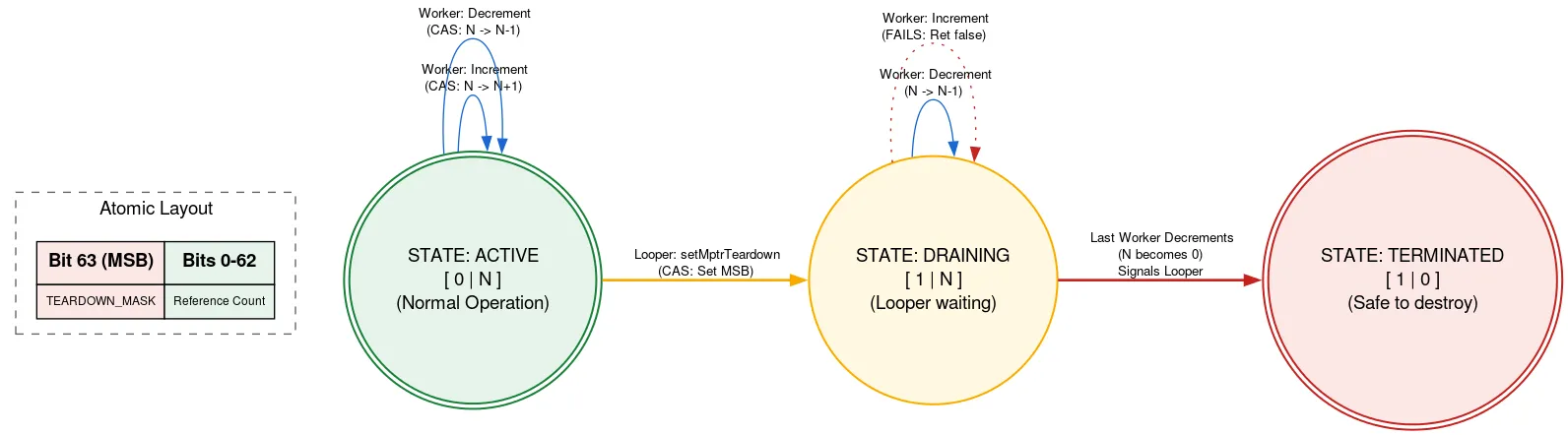
実装には他にも多くのトリックと複雑さがあります。DeliQueue の詳細については、ソースコードをご覧ください。
最適化: 分岐のないプログラミング
DeliQueue の開発とテストの過程で、チームは多くのベンチマークを実行し、新しいコードを慎重にプロファイリングしました。simpleperf ツールを使用して特定された問題の 1 つは、Message コンパレータ コードによって発生するパイプライン フラッシュでした。
標準のコンパレータは条件付きジャンプを使用します。どちらの Message が先かを決定する条件は、以下のように簡略化されます。
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}このコードは、条件付きジャンプ(b.le 命令と cbnz 命令)にコンパイルされます。CPU が条件付き分岐に遭遇すると、条件が計算されるまで分岐が実行されるかどうかを認識できないため、次に読み取る命令を認識できず、分岐予測と呼ばれる手法を使用して推測する必要があります。バイナリ検索のような場合、各ステップで分岐方向が予測不能に異なるため、予測の半分が間違っている可能性があります。分岐予測は、検索アルゴリズムや並べ替えアルゴリズム(最小ヒープで使用されるものなど)では効果がないことがよくあります。これは、予測が外れた場合のコストが、予測が当たった場合の改善よりも大きいためです。分岐予測が間違っていた場合、予測値の仮定後に実行した作業を破棄し、実際に実行されたパスから再び開始する必要があります。これはパイプライン フラッシュと呼ばれます。
この問題を特定するため、branch-misses パフォーマンス カウンタを使用してベンチマークをプロファイリングしました。このカウンタは、分岐予測が間違ったスタック トレースを記録します。次に、以下に示すように、Google pprof を使用して結果を可視化しました。
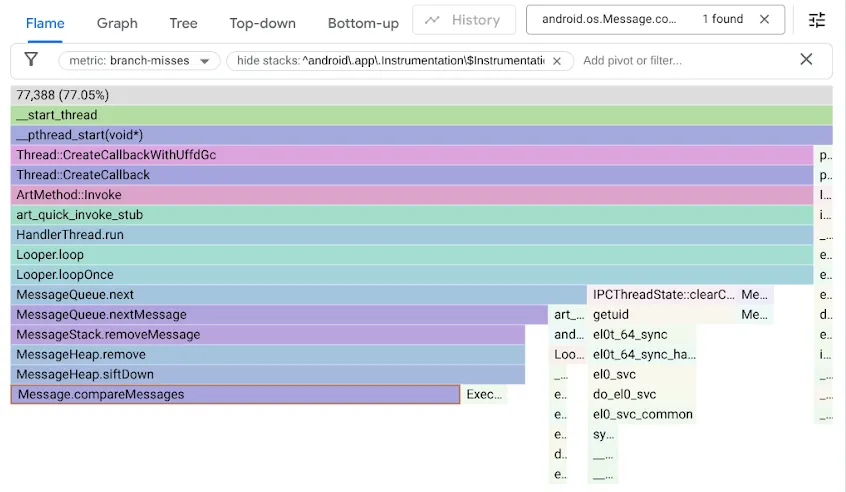
元の MessageQueue コードでは、順序付きキューに単方向連結リストが使用されていました。挿入では、リストを線形検索として並べ替え順にトラバースし、挿入ポイントを過ぎた最初の要素で停止して、その前に新しい Message をリンクします。ヘッドを取り外すには、ヘッドのリンクを解除するだけです。一方、DeliQueue は最小ヒープを使用します。この場合、ミューテーションでは、バランスの取れたデータ構造で対数複雑性を持つ要素の並べ替え(上または下へのふるい分け)が必要になります。このデータ構造では、任意の比較で、トラバーサルが左の子または右の子に均等に振り分けられます。新しいアルゴリズムは漸近的に高速ですが、検索コードがブランチ ミスで半分の時間停止するため、新しいボトルネックが発生します。
ブランチ ミスによってヒープコードの速度が低下していることに気づいたため、ブランチなしプログラミングを使用してコードを最適化しました。
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}最適化を理解するには、Compiler Explorer で 2 つの例を分解し、LLVM-MCA(CPU サイクルのおおよそのタイムラインを生成できる CPU シミュレータ)を使用します。
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
1 つの条件分岐 b.le に注目してください。これは、when フィールドの比較から結果がすでにわかっている場合に、insertSeq フィールドの比較を回避します。
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
この場合、分岐なしの実装は、分岐コードの最短パスよりもサイクル数と命令数が少なく、あらゆるケースで優れています。実装の高速化と予測ミスした分岐の排除により、一部のベンチマークで 5 倍の改善が実現しました。
ただし、この手法は常に適用できるとは限りません。一般的に、分岐なしのアプローチでは破棄される処理が必要になります。分岐がほとんど予測可能な場合、無駄な処理によってコードの速度が低下する可能性があります。また、ブランチを削除すると、データ依存関係が生じることがよくあります。最新の CPU はサイクルごとに複数のオペレーションを実行しますが、前の命令からの入力が準備できるまで命令を実行できません。一方、CPU はブランチ内のデータを推測し、ブランチが正しく予測された場合は先行して処理できます。
テストと検証
ロックフリー アルゴリズムの正しさを検証することは非常に困難です。
開発中の継続的な検証のための標準の単体テストに加えて、キューの不変性を検証し、データ競合が存在する場合はそれを誘発しようとする厳密なストレステストも作成しました。テストラボでは、エミュレートされたデバイスと実際のハードウェアで数百万のテスト インスタンスを実行できました。
Java ThreadSanitizer(JTSan)インストルメンテーションを使用すると、同じテストを使用してコード内のデータ競合も検出できます。JTSan は DeliQueue で問題のあるデータ競合を検出しませんでしたが、驚くべきことに、Robolectric フレームワークで 2 つの同時実行バグを検出し、直ちに修正しました。
デバッグ機能を改善するため、新しい分析ツールを構築しました。以下は、Android プラットフォーム コードで、1 つのスレッドが別のスレッドに Message を過剰に送信し、大きなバックログが発生している問題の例です。このバックログは、追加した MessageQueue 計測機能のおかげで Perfetto で確認できます。
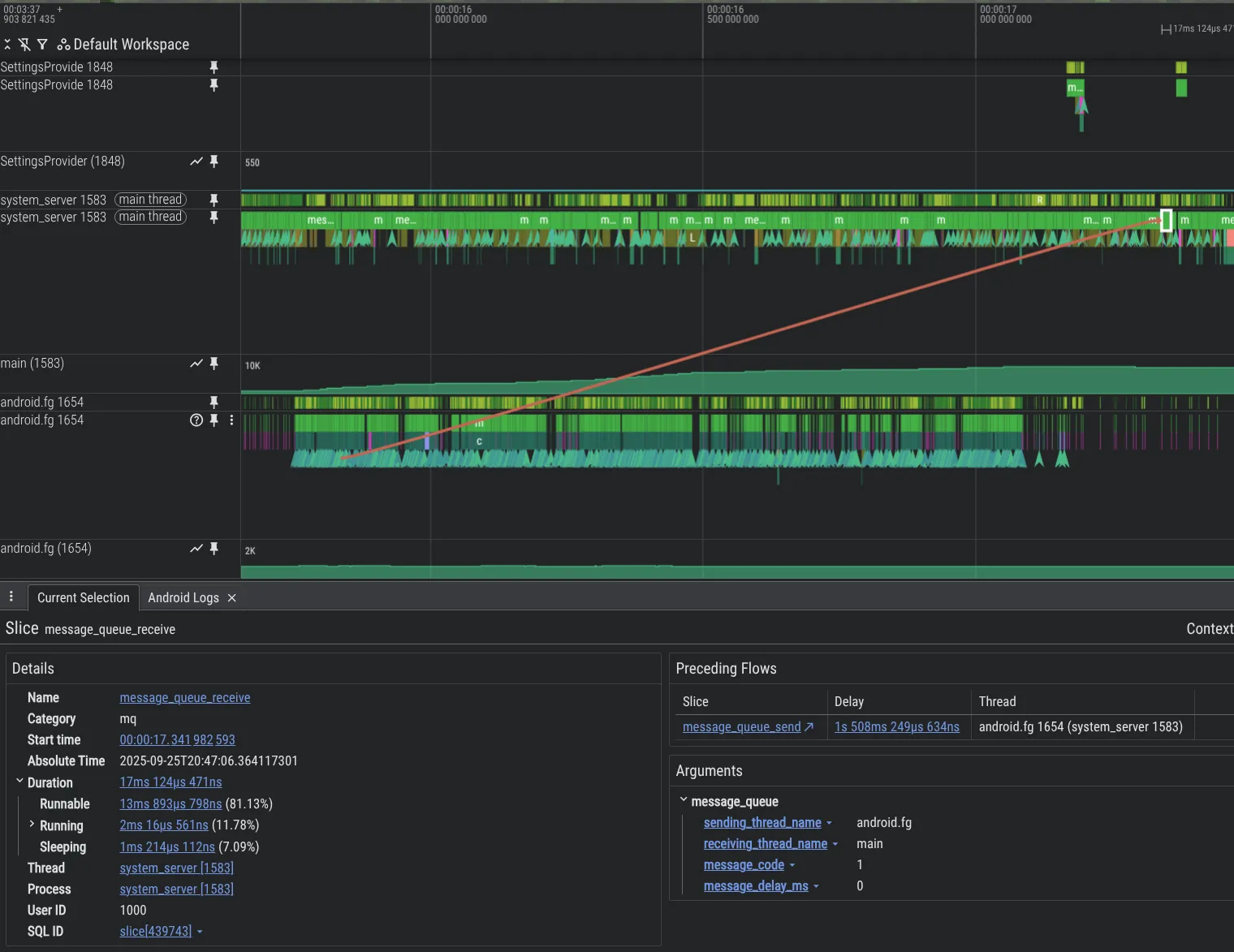
system_server プロセスで MessageQueue トレースを有効にするには、Perfetto 構成に以下を含めます。
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}影響
DeliQueue は、MessageQueue からロックを排除することで、システムとアプリのパフォーマンスを向上させます。
- 合成ベンチマーク: 改善された同時実行性(Treiber スタック)と高速挿入(最小ヒープ)により、ビジー状態のキューへのマルチスレッド挿入が従来の
MessageQueueよりも最大 5,000 倍高速になります。 - 内部ベータ版テスターから取得した Perfetto トレースでは、ロック競合で費やされたアプリのメインスレッドの時間が 15% 減少しています。
- 同じテストデバイスで、ロック競合の削減により、次のようなユーザー エクスペリエンスが大幅に改善されます。
- アプリのフレーム落ちが 4% 減少。
- システム UI とランチャーのインタラクションで、フレーム落ちが 7.7% 減少しました。
- アプリの起動から最初のフレームが描画されるまでの時間が 95 パーセンタイルで 9.1% 減少。
次のステップ
DeliQueue は Android 17 のアプリにロールアウトされます。アプリ デベロッパーは、Android デベロッパー ブログの「新しいロックフリー MessageQueue 向けにアプリを準備する」で、アプリのテスト方法を確認してください。
参照
[1] Treiber, R.K., 1986 年。システム プログラミング: 並列処理への対応。International Business Machines Incorporated, Thomas J. ワトソン研究所。
[2] Goetz, B.、Peierls, T.、Bloch, J.、Bowbeer, J.、Holmes, D.、& Lea, D. (2006 年)。Java Concurrency in Practice。Addison-Wesley Professional
-

 プロダクト ニュース
プロダクト ニュース3 月に、Google は実際の Android 開発タスク向けの LLM リーダーボードである Android Bench を発表しました。その後、オープンウェイト モデルの評価や、リーダーボードへの費用と効率のディメンションの追加など、フィードバックに基づいてベンチマークを強化してきました。
Zoe Lopez-Latorre • 所要時間: 3 分 -

 プロダクト ニュース
プロダクト ニュースGoogle Play は、ユーザーに最善のエクスペリエンスを提供するとともに、デベロッパーの皆様が成功するために必要なツールと柔軟性を提供できるよう尽力しています。
Paul Feng • 所要時間: 3 分 -

 プロダクト ニュース
プロダクト ニュース昨年、Google はエコシステムのセキュリティを強化し、悪意のある行為者が匿名性を隠れ蓑にして有害なアプリをリリースすることを防ぐため、Android デベロッパーの確認を導入しました。
Matthew Forsythe • 所要時間: 2 分
Android 開発に関する最新の分析情報を毎週メールでお届けします。
