

Trong Android 17, các ứng dụng nhắm đến SDK 37 trở lên sẽ nhận được một phương thức triển khai mới của MessageQueue, trong đó phương thức triển khai này không có khoá. Việc triển khai mới này giúp cải thiện hiệu suất và giảm số khung hình bị bỏ lỡ, nhưng có thể làm hỏng những ứng dụng phản ánh các trường và phương thức riêng tư của MessageQueue. Để tìm hiểu thêm về thay đổi về hành vi và cách giảm thiểu tác động, hãy xem tài liệu về thay đổi về hành vi của MessageQueue. Bài đăng này trên blog kỹ thuật cung cấp thông tin tổng quan về việc tái cấu trúc MessageQueue và cách bạn có thể phân tích các vấn đề về tranh chấp khoá bằng Perfetto.
Looper điều khiển luồng giao diện người dùng của mọi ứng dụng Android. Nó lấy công việc từ một MessageQueue, gửi công việc đó đến một Handler và lặp lại. Trong 2 thập kỷ, MessageQueue đã sử dụng một khoá màn hình duy nhất (tức là một khối mã synchronized) để bảo vệ trạng thái của khoá.
Android 17 giới thiệu một bản cập nhật quan trọng cho thành phần này: một quy trình triển khai không khoá có tên là DeliQueue.
Bài đăng này giải thích cách khoá ảnh hưởng đến hiệu suất giao diện người dùng, cách phân tích những vấn đề này bằng Perfetto, cũng như các thuật toán và hoạt động tối ưu hoá cụ thể được dùng để cải thiện luồng chính của Android.
Vấn đề: Tranh chấp khoá và đảo ngược mức độ ưu tiên
Hàm MessageQueue cũ hoạt động như một hàng đợi ưu tiên được bảo vệ bằng một khoá duy nhất. Nếu một luồng nền đăng một thông báo trong khi luồng chính thực hiện việc duy trì hàng đợi, thì luồng nền sẽ chặn luồng chính.
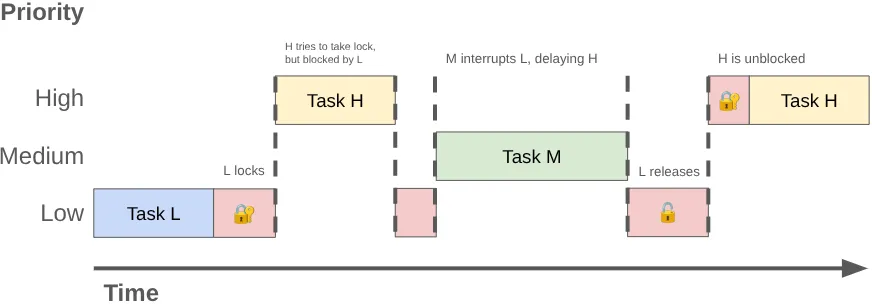
Khi hai hoặc nhiều luồng tranh giành quyền sử dụng độc quyền cùng một khoá, thì đây được gọi là Tranh chấp khoá. Sự tranh chấp này có thể gây ra hiện tượng Đảo ngược mức độ ưu tiên, dẫn đến tình trạng giao diện người dùng bị giật và các vấn đề khác về hiệu suất.
Tình trạng đảo ngược mức độ ưu tiên có thể xảy ra khi một luồng có mức độ ưu tiên cao (chẳng hạn như luồng giao diện người dùng) phải chờ một luồng có mức độ ưu tiên thấp. Hãy xem xét trình tự sau:
- Một luồng nền có mức độ ưu tiên thấp sẽ lấy khoá
MessageQueueđể đăng kết quả của công việc mà luồng đó đã thực hiện. - Một luồng có mức độ ưu tiên trung bình sẽ trở thành luồng có thể chạy và trình lập lịch của nhân hệ điều hành sẽ phân bổ thời gian của CPU cho luồng này, đồng thời giành quyền ưu tiên luồng này hơn luồng có mức độ ưu tiên thấp.
- Luồng giao diện người dùng có mức độ ưu tiên cao hoàn tất tác vụ hiện tại và cố gắng đọc từ hàng đợi, nhưng bị chặn vì luồng có mức độ ưu tiên thấp giữ khoá.
Luồng có mức độ ưu tiên thấp chặn luồng giao diện người dùng và công việc có mức độ ưu tiên trung bình làm chậm luồng này hơn nữa.
Phân tích tình trạng tranh chấp bằng Perfetto
Bạn có thể chẩn đoán những vấn đề này bằng cách sử dụng Perfetto. Trong một dấu vết tiêu chuẩn, một luồng bị chặn trên khoá màn hình sẽ chuyển sang trạng thái ngủ và Perfetto sẽ hiển thị một lát cắt cho biết chủ sở hữu khoá.
Khi bạn truy vấn dữ liệu theo dõi, hãy tìm các lát có tên "monitor contention with …" (giám sát tranh chấp với...) theo sau là tên của luồng sở hữu khoá và vị trí mã nơi khoá được lấy.
Nghiên cứu điển hình: Trình chạy bị giật
Để minh hoạ, hãy phân tích một dấu vết mà người dùng gặp phải hiện tượng giật khi điều hướng về trang chủ trên điện thoại Pixel ngay sau khi chụp ảnh trong ứng dụng máy ảnh. Dưới đây là ảnh chụp màn hình Perfetto cho thấy các sự kiện dẫn đến khung hình bị bỏ lỡ:
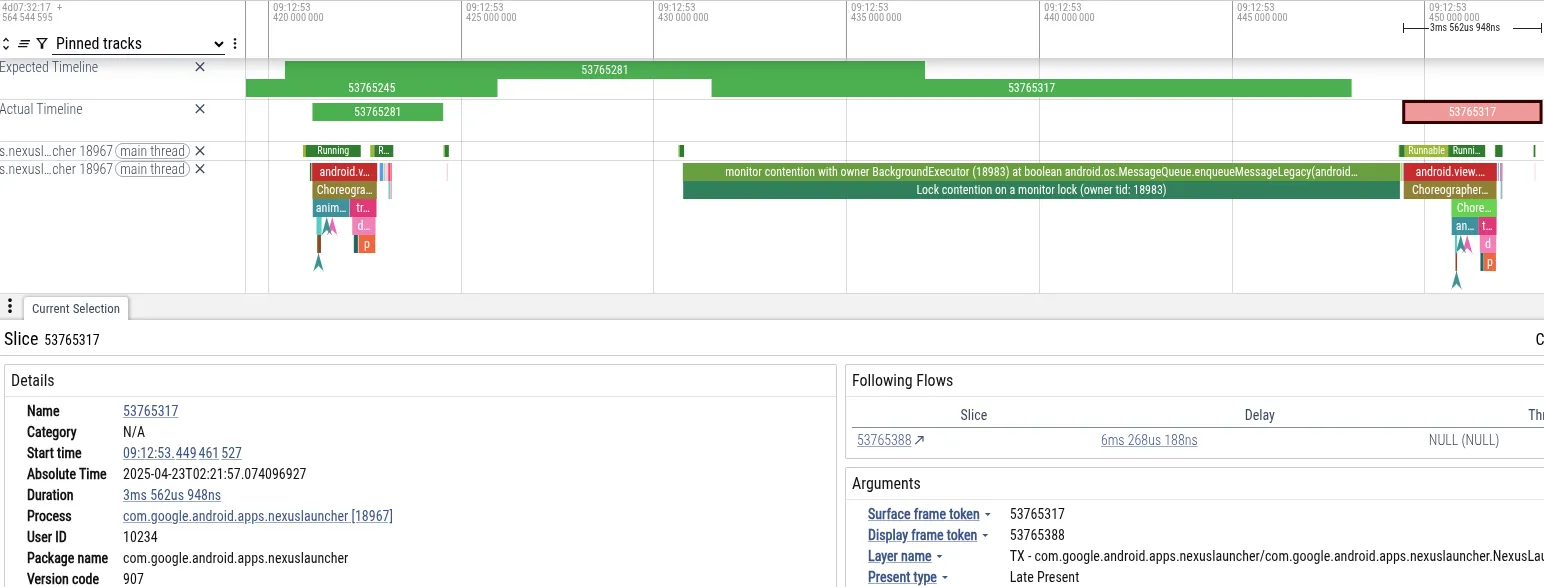
- Triệu chứng: Luồng chính của Trình chạy đã bỏ lỡ thời hạn của khung hình. Thời gian chặn là 18 mili giây, vượt quá thời hạn 16 mili giây cần thiết để kết xuất 60 Hz.
- Chẩn đoán: Perfetto cho thấy luồng chính bị chặn trên khoá
MessageQueue. Một luồng "BackgroundExecutor" sở hữu khoá. - Nguyên nhân gốc rễ: BackgroundExecutor chạy ở Process.THREAD_PRIORITY_BACKGROUND (mức độ ưu tiên rất thấp). Ứng dụng đã thực hiện một tác vụ không khẩn cấp (kiểm tra giới hạn sử dụng ứng dụng). Đồng thời, các luồng có mức độ ưu tiên trung bình đang sử dụng thời gian CPU để xử lý dữ liệu từ camera. Trình lập lịch hệ điều hành đã giành quyền luồng BackgroundExecutor để chạy các luồng camera.
Trình tự này khiến luồng giao diện người dùng của Trình chạy (mức độ ưu tiên cao) bị chặn gián tiếp bởi luồng worker của camera (mức độ ưu tiên trung bình). Luồng này ngăn luồng nền của Trình chạy (mức độ ưu tiên thấp) giải phóng khoá.
Truy vấn dấu vết bằng PerfettoSQL
Bạn có thể sử dụng PerfettoSQL để truy vấn dữ liệu dấu vết cho các mẫu cụ thể. Điều này sẽ hữu ích nếu bạn có một lượng lớn dấu vết từ các thiết bị hoặc kiểm thử của người dùng và bạn đang tìm kiếm những dấu vết cụ thể cho thấy một vấn đề.
Ví dụ: truy vấn này tìm thấy tình trạng xung đột MessageQueue trùng với khung hình bị rớt (giật):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
Trong ví dụ phức tạp hơn này, hãy kết hợp dữ liệu dấu vết trải rộng trên nhiều bảng để xác định tình trạng tranh chấp MessageQueue trong quá trình khởi động ứng dụng:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Bạn có thể dùng LLM mà mình yêu thích để viết các truy vấn PerfettoSQL nhằm tìm ra những mẫu khác.
Tại Google, chúng tôi sử dụng BigTrace để chạy các truy vấn PerfettoSQL trên hàng triệu dấu vết. Khi làm như vậy, chúng tôi xác nhận rằng những gì chúng tôi thấy chỉ là một vấn đề mang tính giai thoại, trên thực tế, đó là một vấn đề mang tính hệ thống. Dữ liệu cho thấy tình trạng tranh chấp khoá ảnh hưởng đến người dùng trên toàn bộ hệ sinh thái, chứng minh sự cần thiết của một thay đổi cơ bản về cấu trúc.MessageQueue
Giải pháp: tính đồng thời không khoá
Chúng tôi đã giải quyết vấn đề MessageQueue tranh chấp bằng cách triển khai một cấu trúc dữ liệu không khoá, sử dụng các thao tác bộ nhớ nguyên tử thay vì khoá độc quyền để đồng bộ hoá quyền truy cập vào trạng thái dùng chung. Một cấu trúc dữ liệu hoặc thuật toán là không khoá nếu ít nhất một luồng luôn có thể tiến hành bất kể hành vi lập lịch của các luồng khác. Thuộc tính này thường khó đạt được và thường không đáng để theo đuổi đối với hầu hết mã.
Các nguyên hàm nguyên tử
Phần mềm không khoá thường dựa vào các nguyên tắc cơ bản Read-Modify-Write (Đọc-Sửa đổi-Ghi) mà phần cứng cung cấp.
Trên CPU ARM64 thế hệ cũ, các thao tác nguyên tử sử dụng vòng lặp Load-Link/Store-Conditional (LL/SC). CPU tải một giá trị và đánh dấu địa chỉ. Nếu một luồng khác ghi vào địa chỉ đó, thì kho lưu trữ sẽ không thành công và vòng lặp sẽ thử lại. Vì các luồng có thể tiếp tục thử và thành công mà không cần đợi một luồng khác, nên thao tác này không bị khoá.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrCác cấu trúc ARM mới hơn (ARMv8.1) hỗ trợ Tiện ích hệ thống lớn (LSE), bao gồm các chỉ dẫn dưới dạng So sánh và hoán đổi (CAS) hoặc Tải và thêm (minh hoạ bên dưới). Trong Android 17, chúng tôi đã thêm tính năng hỗ trợ cho trình biên dịch Android Runtime (ART) để phát hiện thời điểm LSE được hỗ trợ và phát ra các chỉ dẫn được tối ưu hoá:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Trong các điểm chuẩn của chúng tôi, mã có mức độ tranh chấp cao sử dụng CAS đạt được tốc độ nhanh hơn khoảng 3 lần so với biến thể LL/SC.
Ngôn ngữ lập trình Java cung cấp các nguyên hàm nguyên tử thông qua java.util.concurrent.atomic dựa trên các nguyên hàm này và các chỉ dẫn CPU chuyên biệt khác.
Cấu trúc dữ liệu: DeliQueue
Để loại bỏ tình trạng tranh chấp khoá khỏi MessageQueue, các kỹ sư của chúng tôi đã thiết kế một cấu trúc dữ liệu mới có tên là DeliQueue. DeliQueue tách biệt việc chèn Message với việc xử lý Message:
- Danh sách
Messages(Treiber stack): Một ngăn xếp không khoá. Mọi luồng đều có thể đẩyMessagesmới vào đây mà không cần tranh chấp. - Hàng đợi ưu tiên (Min-heap): Một heap của
Messagesđể xử lý, thuộc quyền sở hữu riêng của luồng Looper (do đó, không cần đồng bộ hoá hoặc khoá để truy cập).
Enqueue: đẩy vào ngăn xếp Treiber
Danh sách Messages được lưu giữ trong ngăn xếp Treiber [1], một ngăn xếp không khoá sử dụng vòng lặp CAS để cập nhật con trỏ đầu.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Mã nguồn dựa trên Java Concurrency in Practice [2], có sẵn trên mạng và được phát hành cho miền công cộng
Bất kỳ nhà sản xuất nào cũng có thể thêm Messagemới vào ngăn xếp bất cứ lúc nào. Điều này giống như việc lấy số thứ tự tại quầy bán đồ ăn sẵn – số của bạn được xác định theo thời điểm bạn xuất hiện, nhưng thứ tự bạn nhận được đồ ăn không nhất thiết phải khớp với số thứ tự. Vì đây là một ngăn xếp được liên kết, nên mọi Message đều là một ngăn xếp con – bạn có thể thấy hàng đợi Message như thế nào tại bất kỳ thời điểm nào bằng cách theo dõi phần đầu và lặp lại về phía trước – bạn sẽ không thấy bất kỳ Message mới nào được đẩy lên trên cùng, ngay cả khi chúng đang được thêm vào trong quá trình duyệt qua.
Dequeue: chuyển hàng loạt sang min-heap
Để tìm Message tiếp theo cần xử lý, Looper sẽ xử lý các Message mới từ ngăn xếp Treiber bằng cách duyệt qua ngăn xếp bắt đầu từ trên cùng và lặp lại cho đến khi tìm thấy Message cuối cùng mà nó đã xử lý trước đó. Khi Looper di chuyển xuống ngăn xếp, nó sẽ chèn Message vào min-heap được sắp xếp theo thời hạn. Vì Looper chỉ sở hữu vùng nhớ heap, nên nó sẽ sắp xếp và xử lý Message mà không cần khoá hoặc nguyên tử.

Khi đi xuống ngăn xếp, Looper cũng tạo các đường liên kết từ các Message được xếp chồng lên nhau trở lại các Message trước đó, do đó tạo thành một danh sách được liên kết kép. Việc tạo danh sách liên kết là an toàn vì các đường liên kết trỏ xuống ngăn xếp được thêm thông qua thuật toán ngăn xếp Treiber bằng CAS, còn các đường liên kết lên ngăn xếp chỉ được luồng Looper đọc và sửa đổi. Sau đó, các đường liên kết ngược này được dùng để xoá Message khỏi các điểm tuỳ ý trong ngăn xếp trong thời gian O(1).
Thiết kế này cung cấp hoạt động chèn O(1) cho nhà sản xuất (các luồng đăng công việc vào hàng đợi) và hoạt động xử lý O(log N) được khấu hao cho người dùng (Looper).
Việc sử dụng min-heap để sắp xếp Message cũng giải quyết một lỗi cơ bản trong MessageQueue cũ, trong đó Message được giữ trong một danh sách liên kết đơn (bắt nguồn từ trên cùng). Trong quá trình triển khai cũ, việc xoá khỏi đầu là O(1), nhưng trường hợp chèn xấu nhất là O(N) – khả năng mở rộng kém đối với các hàng đợi bị quá tải! Ngược lại, việc chèn vào và xoá khỏi min-heap sẽ có quy mô theo hàm logarit, mang lại hiệu suất trung bình cạnh tranh nhưng thực sự vượt trội về độ trễ đuôi.
Cũ (đã khoá) MessageQueue | DeliQueue | |
| Insert | O(N) | O(1) để gọi luồng O(logN) cho |
| Xoá khỏi đầu | O(1) | O(logN) |
Trong quá trình triển khai hàng đợi cũ, nhà sản xuất và người tiêu dùng đã sử dụng một khoá để điều phối quyền truy cập độc quyền vào danh sách được liên kết đơn lẻ cơ bản. Trong DeliQueue, ngăn xếp Treiber xử lý quyền truy cập đồng thời và người dùng duy nhất xử lý việc sắp xếp hàng đợi công việc.
Xoá: tính nhất quán thông qua các dấu hiệu đánh dấu
DeliQueue là một cấu trúc dữ liệu kết hợp, kết hợp ngăn xếp Treiber không khoá với min-heap một luồng. Việc giữ cho hai cấu trúc này đồng bộ hoá mà không có khoá chung là một thách thức riêng: một thông báo có thể xuất hiện thực sự trong ngăn xếp nhưng lại bị xoá khỏi hàng đợi một cách hợp lý.
Để giải quyết vấn đề này, DeliQueue sử dụng một kỹ thuật gọi là "tombstoning". Mỗi Message theo dõi vị trí của nó trong ngăn xếp thông qua các con trỏ ngược và xuôi, chỉ mục của nó trong mảng của heap và một cờ boolean cho biết liệu nó đã bị xoá hay chưa. Khi Message đã sẵn sàng chạy, luồng Looper sẽ CAS cờ đã xoá, sau đó xoá cờ này khỏi heap và ngăn xếp.
Khi một luồng khác cần xoá một Message, luồng đó sẽ không trích xuất ngay Message đó khỏi cấu trúc dữ liệu. Thay vào đó, nó sẽ thực hiện các bước sau:
- Xoá theo logic: luồng sử dụng CAS để đặt cờ xoá của
Messagetừ false thành true một cách nguyên tử.Messagevẫn nằm trong cấu trúc dữ liệu dưới dạng bằng chứng về việc đang chờ xoá, còn gọi là "dấu hiệu xoá". Sau khiMessageđược gắn cờ để xoá, DeliQueue sẽ coiMessagenhư thể không còn tồn tại trong hàng đợi bất cứ khi nào tìm thấy. - Dọn dẹp bị hoãn lại: Việc xoá thực tế khỏi cấu trúc dữ liệu là trách nhiệm của luồng
Loopervà sẽ bị hoãn lại cho đến sau. Thay vì sửa đổi ngăn xếp hoặc vùng nhớ heap, luồng xoá sẽ thêmMessagevào một ngăn xếp danh sách trống không khoá khác. - Xoá cấu trúc: Chỉ
Loopermới có thể tương tác với vùng nhớ hoặc xoá các phần tử khỏi ngăn xếp. Khi thức dậy, nó sẽ xoá danh sách trống và xử lý cácMessagemà danh sách đó chứa. Sau đó, mỗiMessagesẽ bị huỷ liên kết khỏi ngăn xếp và bị xoá khỏi vùng nhớ heap.
Phương pháp này giúp duy trì tất cả hoạt động quản lý của vùng nhớ heap một luồng. Điều này giúp giảm thiểu số lượng thao tác đồng thời và rào cản bộ nhớ cần thiết, giúp đường dẫn quan trọng trở nên nhanh hơn và đơn giản hơn.
Traversal: benign Java memory model data races
Hầu hết các API đồng thời, chẳng hạn như Future trong thư viện chuẩn Java hoặc Job và Deferred của Kotlin, đều có một cơ chế để huỷ công việc trước khi hoàn tất. Một thực thể của một trong các lớp này khớp 1:1 với một đơn vị công việc cơ bản và việc gọi cancel trên một đối tượng sẽ huỷ các thao tác cụ thể được liên kết với đối tượng đó.
Các thiết bị Android hiện nay có CPU đa nhân và tính năng thu gom rác đồng thời theo thế hệ. Nhưng khi Android mới được phát triển, việc phân bổ một đối tượng cho mỗi đơn vị công việc là quá tốn kém. Do đó, Handler của Android hỗ trợ việc huỷ thông qua nhiều phương thức nạp chồng của removeMessages – thay vì xoá một cụ thể Message, phương thức này sẽ xoá tất cả các Message khớp với tiêu chí đã chỉ định. Trên thực tế, việc này đòi hỏi phải lặp lại tất cả Message được chèn trước khi removeMessages được gọi và xoá những Message phù hợp.
Khi lặp lại về phía trước, một luồng chỉ yêu cầu một thao tác nguyên tử có thứ tự để đọc phần đầu hiện tại của ngăn xếp. Sau đó, các thao tác đọc trường thông thường sẽ được dùng để tìm Message tiếp theo. Nếu luồng Looper sửa đổi các trường next trong khi xoá Message, thì thao tác ghi của Looper và thao tác đọc của một luồng khác sẽ không được đồng bộ hoá – đây là một trạng thái xung đột dữ liệu. Thông thường, tình huống tương tranh là một lỗi nghiêm trọng có thể gây ra nhiều vấn đề trong ứng dụng của bạn – rò rỉ, vòng lặp vô hạn, sự cố, tình trạng treo máy, v.v. Tuy nhiên, trong một số điều kiện hạn chế, các cuộc tranh chấp dữ liệu có thể không gây hại trong Mô hình bộ nhớ Java. Giả sử chúng ta bắt đầu với một ngăn xếp gồm:

Chúng ta thực hiện một thao tác đọc nguyên tử của tiêu đề và thấy A. Con trỏ tiếp theo của A trỏ đến B. Đồng thời với quá trình xử lý B, trình lặp có thể xoá B và C bằng cách cập nhật A để trỏ đến C rồi đến D.
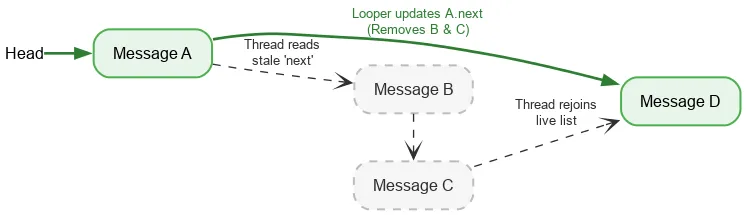
Mặc dù B và C được xoá theo logic, nhưng B vẫn giữ con trỏ tiếp theo đến C và C đến D. Luồng đọc tiếp tục đi qua các nút đã bị xoá và cuối cùng sẽ kết hợp lại với ngăn xếp trực tiếp tại D.
Bằng cách thiết kế DeliQueue để xử lý các cuộc đua giữa việc di chuyển và xoá, chúng tôi cho phép lặp lại an toàn mà không cần khoá.
Quitting: Native refcount
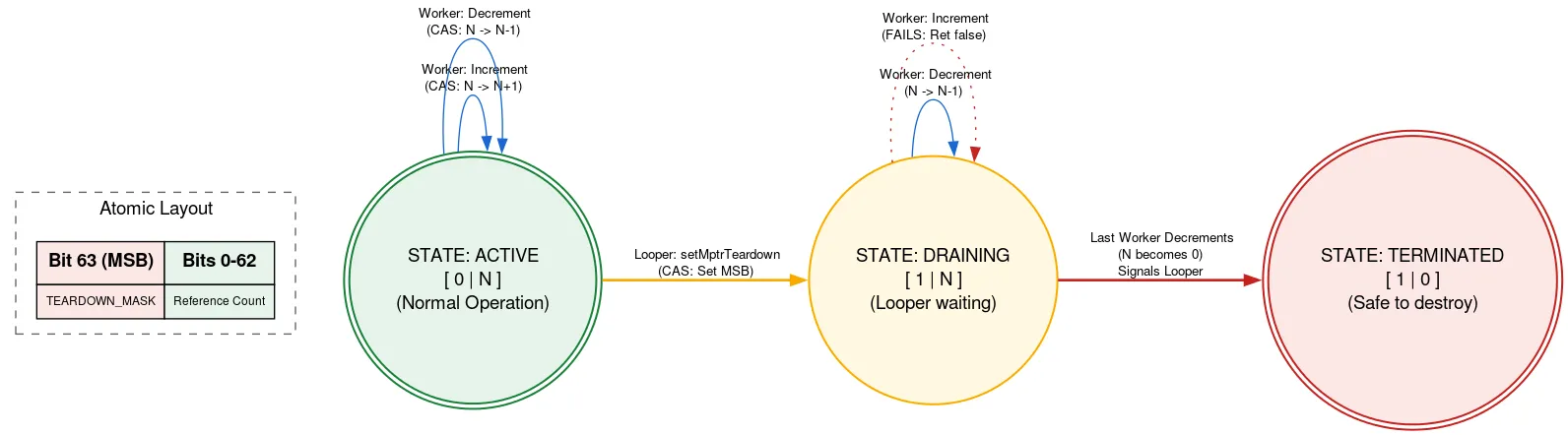
Looper được hỗ trợ bằng một hoạt động phân bổ gốc mà bạn phải giải phóng theo cách thủ công sau khi Looper thoát. Nếu một số luồng khác đang thêm Message trong khi Looper đang thoát, thì luồng đó có thể sử dụng việc phân bổ gốc sau khi được giải phóng, tức là vi phạm tính an toàn của bộ nhớ. Chúng tôi ngăn chặn điều này bằng cách sử dụng tagged refcount, trong đó một bit của atomic được dùng để cho biết liệu Looper có đang thoát hay không.
Trước khi sử dụng hoạt động phân bổ gốc, một luồng sẽ đọc refcount atomic. Nếu bạn đặt bit thoát, thì hệ thống sẽ trả về rằng Looper đang thoát và không được dùng chế độ phân bổ gốc. Nếu không, nó sẽ thử CAS để tăng số lượng luồng đang hoạt động bằng cách sử dụng việc phân bổ gốc. Sau khi thực hiện những gì cần thiết, nó sẽ giảm số lượng. Nếu bit thoát được đặt sau khi tăng nhưng trước khi giảm và số lượng hiện là 0, thì bit này sẽ đánh thức luồng Looper.
Khi luồng Looper đã sẵn sàng thoát, luồng này sẽ dùng CAS để đặt bit thoát trong atomic. Nếu refcount là 0, thì nó có thể tiếp tục giải phóng việc phân bổ gốc. Nếu không, nó sẽ tự động dừng, biết rằng nó sẽ được đánh thức khi người dùng cuối cùng của việc phân bổ gốc giảm số lượng tham chiếu. Cách tiếp cận này có nghĩa là luồng Looper sẽ chờ tiến trình của các luồng khác, nhưng chỉ khi luồng này thoát. Điều đó chỉ xảy ra một lần và không nhạy cảm về hiệu suất, đồng thời giữ cho mã khác sử dụng chế độ phân bổ gốc hoàn toàn không bị khoá.
Có rất nhiều thủ thuật và độ phức tạp khác trong quá trình triển khai. Bạn có thể tìm hiểu thêm về DeliQueue bằng cách xem mã nguồn.
Tối ưu hoá: lập trình không có nhánh
Trong quá trình phát triển và kiểm thử DeliQueue, nhóm đã chạy nhiều phép đo điểm chuẩn và lập hồ sơ cẩn thận cho mã mới. Một vấn đề được xác định bằng công cụ simpleperf là các lệnh xoá quy trình do mã so sánh Message gây ra.
Bộ so sánh tiêu chuẩn sử dụng các bước nhảy có điều kiện, với điều kiện để quyết định Message nào xuất hiện trước được đơn giản hoá như sau:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Mã này biên dịch thành các lệnh nhảy có điều kiện (lệnh b.le và cbnz). Khi gặp một nhánh có điều kiện, CPU không thể biết liệu nhánh đó có được thực hiện hay không cho đến khi điều kiện được tính toán. Do đó, CPU không biết nên đọc chỉ thị nào tiếp theo và phải đoán bằng cách sử dụng một kỹ thuật gọi là dự đoán nhánh. Trong trường hợp tìm kiếm nhị phân, hướng rẽ nhánh sẽ khác nhau một cách khó đoán ở mỗi bước, vì vậy, có thể một nửa số dự đoán sẽ sai. Dự đoán nhánh thường không hiệu quả trong các thuật toán tìm kiếm và sắp xếp (chẳng hạn như thuật toán được dùng trong một min-heap), vì chi phí đoán sai lớn hơn mức cải thiện khi đoán đúng. Khi đoán sai, bộ dự đoán nhánh phải loại bỏ những việc đã làm sau khi giả định giá trị được dự đoán và bắt đầu lại từ đường dẫn thực sự được thực hiện – đây được gọi là xoá ống dẫn.
Để tìm ra vấn đề này, chúng tôi đã phân tích hiệu suất của các phép đo điểm chuẩn bằng cách sử dụng bộ đếm hiệu suất branch-misses. Bộ đếm này ghi lại các dấu vết ngăn xếp khi bộ dự đoán nhánh đoán sai. Sau đó, chúng tôi trực quan hoá kết quả bằng Google pprof, như minh hoạ dưới đây:
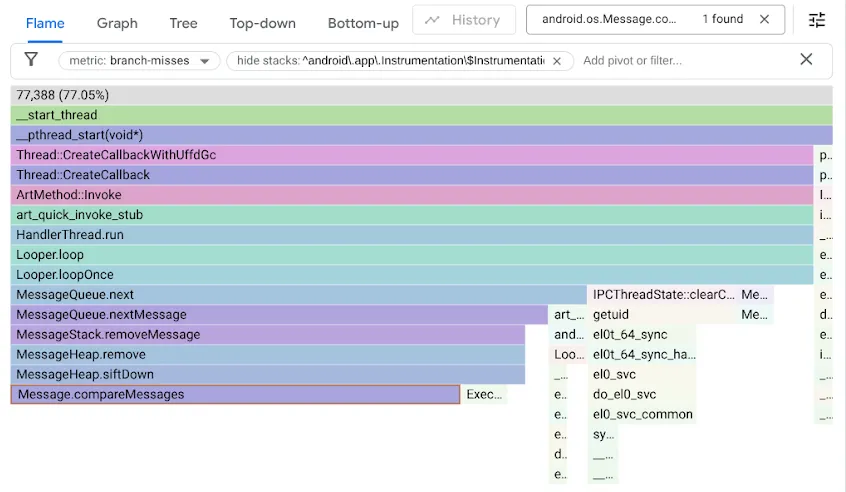
Hãy nhớ rằng mã MessageQueue ban đầu đã dùng danh sách liên kết đơn cho hàng đợi có thứ tự. Thao tác chèn sẽ duyệt qua danh sách theo thứ tự đã sắp xếp dưới dạng tìm kiếm tuyến tính, dừng ở phần tử đầu tiên vượt quá điểm chèn và liên kết Message mới trước phần tử đó. Để tháo đầu, bạn chỉ cần huỷ liên kết đầu. Trong khi DeliQueue sử dụng min-heap, nơi các đột biến yêu cầu sắp xếp lại một số phần tử (sàng lên hoặc xuống) với độ phức tạp theo hàm logarit trong một cấu trúc dữ liệu cân bằng, nơi mọi phép so sánh đều có cơ hội ngang nhau để hướng việc duyệt qua đến một phần tử con bên trái hoặc đến một phần tử con bên phải. Thuật toán mới nhanh hơn tiệm cận, nhưng lại bộc lộ một điểm tắc nghẽn mới khi mã tìm kiếm bị dừng ở các nhánh bị bỏ lỡ một nửa thời gian.
Nhận thấy các lệnh rẽ nhánh bị bỏ lỡ đang làm chậm mã đống của chúng tôi, chúng tôi đã tối ưu hoá mã bằng cách sử dụng lập trình không rẽ nhánh:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Để hiểu rõ quá trình tối ưu hoá, hãy phân tích hai ví dụ trong Compiler Explorer và sử dụng LLVM-MCA, một trình mô phỏng CPU có thể tạo ra dòng thời gian ước tính của các chu kỳ CPU.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Lưu ý một nhánh có điều kiện, b.le, giúp tránh so sánh các trường insertSeq nếu kết quả đã được biết từ việc so sánh các trường when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Ở đây, việc triển khai không có nhánh sẽ mất ít chu kỳ và chỉ dẫn hơn so với cả đường dẫn ngắn nhất thông qua mã có nhánh – điều này tốt hơn trong mọi trường hợp. Việc triển khai nhanh hơn cùng với việc loại bỏ các nhánh dự đoán sai đã giúp cải thiện hiệu suất gấp 5 lần trong một số điểm chuẩn của chúng tôi!
Tuy nhiên, kỹ thuật này không phải lúc nào cũng áp dụng được. Các phương pháp không có nhánh thường yêu cầu thực hiện công việc sẽ bị loại bỏ và nếu nhánh có thể dự đoán được hầu hết thời gian, thì công việc lãng phí đó có thể làm chậm mã của bạn. Ngoài ra, việc xoá một nhánh thường sẽ tạo ra một phụ thuộc dữ liệu. CPU hiện đại thực hiện nhiều thao tác trong mỗi chu kỳ, nhưng chúng không thể thực hiện một chỉ thị cho đến khi dữ liệu đầu vào của chỉ thị đó từ một chỉ thị trước đó đã sẵn sàng. Ngược lại, CPU có thể dự đoán về dữ liệu trong các nhánh và hoạt động trước nếu một nhánh được dự đoán chính xác.
Kiểm thử và xác thực
Việc xác thực tính chính xác của các thuật toán không khoá là một việc rất khó khăn!
Ngoài các kiểm thử đơn vị tiêu chuẩn để xác thực liên tục trong quá trình phát triển, chúng tôi cũng viết các kiểm thử tải nghiêm ngặt để xác minh các bất biến của hàng đợi và cố gắng gây ra tình trạng xung đột dữ liệu nếu có. Trong phòng thử nghiệm, chúng tôi có thể chạy hàng triệu phiên bản kiểm thử trên các thiết bị mô phỏng và trên phần cứng thực.
Với hoạt động đo lường Java ThreadSanitizer (JTSan), chúng ta có thể sử dụng cùng một quy trình kiểm thử để phát hiện một số tình trạng xung đột dữ liệu trong mã của mình. JTSan không tìm thấy bất kỳ xung đột dữ liệu nào có vấn đề trong DeliQueue, nhưng – thật đáng ngạc nhiên – lại phát hiện ra 2 lỗi đồng thời trong khung Robolectric mà chúng tôi đã nhanh chóng khắc phục.
Để cải thiện khả năng gỡ lỗi, chúng tôi đã tạo ra các công cụ phân tích mới. Dưới đây là một ví dụ minh hoạ vấn đề trong mã nền tảng Android, trong đó một luồng đang làm quá tải một luồng khác bằng Message, gây ra tình trạng tồn đọng lớn, có thể thấy trong Perfetto nhờ tính năng đo lường MessageQueue mà chúng tôi đã thêm.
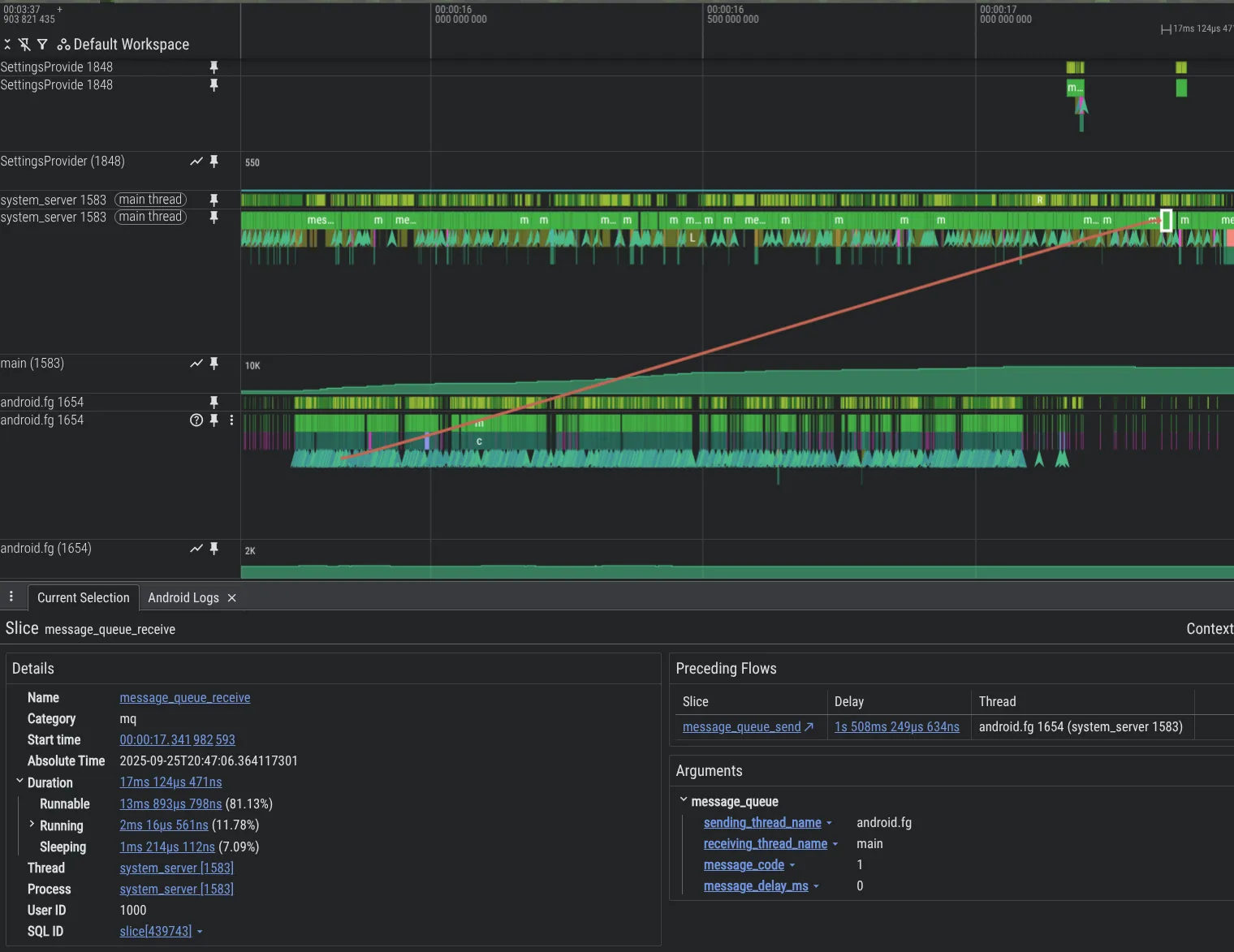
Để bật tính năng theo dõi MessageQueue trong quy trình system_server, hãy thêm nội dung sau vào cấu hình Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Tác động
DeliQueue cải thiện hiệu suất của hệ thống và ứng dụng bằng cách loại bỏ các khoá khỏi MessageQueue.
- Điểm chuẩn tổng hợp: việc chèn đa luồng vào các hàng đợi bận rộn nhanh hơn tới 5.000 lần so với
MessageQueuecũ, nhờ khả năng đồng thời được cải thiện (ngăn xếp Treiber) và tốc độ chèn nhanh hơn (min-heap). - Trong dấu vết Perfetto thu được từ những người thử nghiệm beta nội bộ, chúng tôi nhận thấy thời gian luồng chính của ứng dụng dành cho tranh chấp khoá giảm 15%.
- Trên cùng một thiết bị thử nghiệm, việc giảm tranh chấp khoá sẽ giúp cải thiện đáng kể trải nghiệm người dùng, chẳng hạn như:
- Giảm 4% số khung hình bị bỏ lỡ trong các ứng dụng.
- -7,7% số khung bị bỏ lỡ trong các hoạt động tương tác với Giao diện người dùng hệ thống và Trình chạy.
- Giảm 9,1% thời gian từ khi khởi động ứng dụng đến khi khung hình đầu tiên được vẽ, ở phân vị thứ 95.
Các bước tiếp theo
DeliQueue sẽ được triển khai cho các ứng dụng trong Android 17. Nhà phát triển ứng dụng nên xem bài viết chuẩn bị ứng dụng cho MessageQueue không khoá mới trên blog dành cho nhà phát triển Android để tìm hiểu cách kiểm thử ứng dụng.
Tài liệu tham khảo
[1] Treiber, R.K., 1986. Lập trình hệ thống: Xử lý tính song song. International Business Machines Incorporated, Thomas J. Trung tâm nghiên cứu Watson.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., và Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Tác giả:
Tiếp tục đọc
-


Tin tức về sản phẩm
Tại Google I/O 2026, chúng tôi đã giới thiệu sự thay đổi của Android từ một hệ điều hành thành một hệ thống thông minh. Chúng tôi cũng minh hoạ cách bạn có thể tạo trải nghiệm thông minh một cách tự nhiên bằng hệ thống và mang sức mạnh của AI của Google vào các ứng dụng của mình.
Jingyu Shi • Đọc trong 2 phút
-



Tin tức về sản phẩm
Chúng tôi rất vui mừng thông báo rằng Android XR đã chính thức hỗ trợ Unreal Engine và Godot. Chúng tôi cũng ra mắt các công cụ mới được thiết kế để tăng năng suất và cho phép các chức năng XR mới: Android XR Engine Hub và Android XR Interaction Framework.
Luke Hopkins, Ryan Bartley • Đọc trong 4 phút
-


Tin tức về sản phẩm
Với việc phát hành Android 17, chúng tôi đang chuyển sang tiêu chuẩn phát triển thích ứng. Người dùng không còn chỉ dựa vào một kiểu dáng thiết bị duy nhất nữa; họ chuyển đổi giữa điện thoại, thiết bị có thể gập lại, máy tính bảng, máy tính xách tay, màn hình ô tô và môi trường XR sống động trong suốt cả ngày.
Fahd Imtiaz • Đọc trong 4 phút
Nhận thông tin cập nhật
Nhận thông tin chi tiết mới nhất về hoạt động phát triển trên Android trong hộp thư đến của bạn mỗi tuần.
