


Android 17에서 SDK 37 이상을 타겟팅하는 앱은 구현이 잠금 없는 MessageQueue의 새로운 구현을 수신합니다. 새 구현은 성능을 개선하고 누락된 프레임을 줄이지만 MessageQueue 비공개 필드와 메서드를 반영하는 클라이언트를 중단할 수 있습니다. 동작 변경사항과 영향을 완화하는 방법을 자세히 알아보려면 MessageQueue 동작 변경사항 문서를 참고하세요. 이 기술 블로그 게시물에서는 MessageQueue 재설계와 Perfetto를 사용하여 잠금 경합 문제를 분석하는 방법을 간략하게 설명합니다.
Looper는 모든 Android 애플리케이션의 UI 스레드를 실행합니다. MessageQueue에서 작업을 가져와 Handler에 디스패치하고 반복합니다. 20년 동안 MessageQueue는 synchronized 코드 블록과 같은 단일 모니터 잠금을 사용하여 상태를 보호했습니다.
Android 17에서는 이 구성요소에 DeliQueue라는 잠금 없는 구현이라는 중요한 업데이트가 도입되었습니다.
이 게시물에서는 잠금이 UI 성능에 미치는 영향, Perfetto로 이러한 문제를 분석하는 방법, Android 기본 스레드를 개선하는 데 사용되는 특정 알고리즘과 최적화를 설명합니다.
문제: 잠금 경합 및 우선순위 역전
기존 MessageQueue는 단일 잠금으로 보호되는 우선순위 대기열로 작동했습니다. 기본 스레드가 대기열 유지보수를 실행하는 동안 백그라운드 스레드가 메시지를 게시하면 백그라운드 스레드가 기본 스레드를 차단합니다.
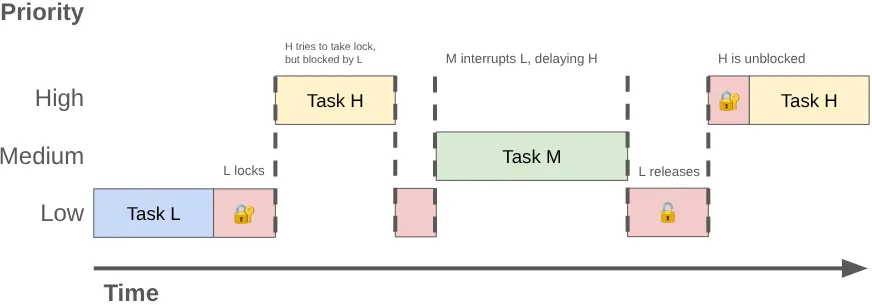
두 개 이상의 스레드가 동일한 잠금을 독점적으로 사용하기 위해 경쟁하는 것을 잠금 경합이라고 합니다. 이 경합으로 인해 우선순위 역전이 발생하여 UI 버벅거림 및 기타 성능 문제가 발생할 수 있습니다.
우선순위 역전은 우선순위가 높은 스레드 (예: UI 스레드)가 우선순위가 낮은 스레드를 기다리도록 할 때 발생할 수 있습니다. 다음 순서를 고려해 보세요.
- 우선순위가 낮은 백그라운드 스레드는
MessageQueue잠금을 획득하여 실행한 작업의 결과를 게시합니다. - 중간 우선순위 스레드가 실행 가능해지고 커널의 스케줄러가 CPU 시간을 할당하여 우선순위가 낮은 스레드를 선점합니다.
- 우선순위가 높은 UI 스레드가 현재 작업을 완료하고 대기열에서 읽기를 시도하지만 우선순위가 낮은 스레드가 잠금을 보유하고 있어 차단됩니다.
우선순위가 낮은 스레드가 UI 스레드를 차단하고 우선순위가 중간인 작업이 이를 더 지연시킵니다.
Perfetto를 사용하여 경합 분석
Perfetto를 사용하여 이러한 문제를 진단할 수 있습니다. 표준 트레이스에서 모니터 잠금으로 차단된 스레드는 절전 모드로 전환되고 Perfetto는 잠금 소유자를 나타내는 슬라이스를 표시합니다.
트레이스 데이터를 쿼리할 때는 'monitor contention with …'이라는 이름의 슬라이스를 찾고, 그 뒤에 잠금을 소유한 스레드의 이름과 잠금을 획득한 코드 사이트가 나옵니다.
우수사례: 런처 버벅거림
예를 들어 카메라 앱에서 사진을 찍은 직후 Pixel 휴대전화에서 홈으로 이동하는 동안 사용자가 끊김 현상을 경험한 트레이스를 분석해 보겠습니다. 아래는 프레임 누락으로 이어지는 이벤트를 보여주는 Perfetto 스크린샷입니다.
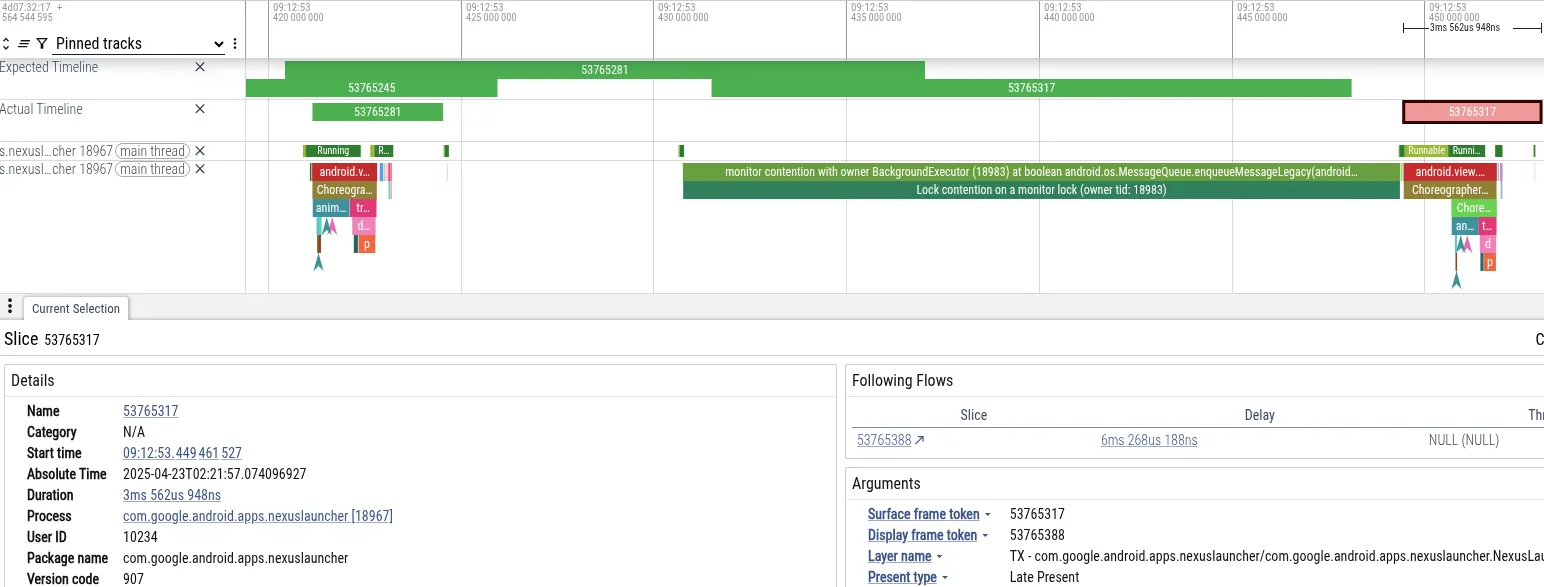
- 증상: 런처 기본 스레드가 프레임 기한을 놓쳤습니다. 18ms 동안 차단되었으며 이는 60Hz 렌더링에 필요한 16ms 기한을 초과합니다.
- 진단: Perfetto에
MessageQueue잠금에서 기본 스레드가 차단된 것으로 표시되었습니다. 'BackgroundExecutor' 스레드가 잠금을 소유했습니다. - 근본 원인: BackgroundExecutor가 Process.THREAD_PRIORITY_BACKGROUND (매우 낮은 우선순위)에서 실행됩니다. 긴급하지 않은 작업 (앱 사용량 제한 확인)을 실행했습니다. 동시에 보통 우선순위 스레드는 CPU 시간을 사용하여 카메라의 데이터를 처리했습니다. OS 스케줄러가 카메라 스레드를 실행하기 위해 BackgroundExecutor 스레드를 선점했습니다.
이 시퀀스로 인해 런처의 UI 스레드 (우선순위 높음)가 카메라 작업자 스레드 (우선순위 중간)에 의해 간접적으로 차단되어 런처의 백그라운드 스레드 (우선순위 낮음)가 잠금을 해제하지 못했습니다.
PerfettoSQL로 트레이스 쿼리
PerfettoSQL을 사용하여 특정 패턴에 대한 트레이스 데이터를 쿼리할 수 있습니다. 이는 사용자 기기나 테스트에서 많은 트레이스가 있고 문제를 보여주는 특정 트레이스를 검색하는 경우에 유용합니다.
예를 들어 다음 쿼리는 프레임이 누락되는 (jank) 시점과 일치하는 MessageQueue 경합을 찾습니다.
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
다음은 더 복잡한 예로, 여러 테이블에 걸쳐 있는 트레이스 데이터를 조인하여 앱 시작 중에 MessageQueue 경합을 식별합니다.
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
좋아하는 LLM을 사용하여 PerfettoSQL 쿼리를 작성하여 다른 패턴을 찾을 수 있습니다.
Google에서는 BigTrace를 사용하여 수백만 개의 트레이스에서 PerfettoSQL 쿼리를 실행합니다. 이를 통해 일화적으로 확인된 문제가 실제로 시스템 문제임을 확인했습니다. 데이터에 따르면 MessageQueue 잠금 경합이 전체 생태계의 사용자에게 영향을 미치므로 근본적인 아키텍처 변경이 필요합니다.
해결 방법: 잠금 없는 동시 실행
공유 상태에 대한 액세스를 동기화하기 위해 독점 잠금 대신 원자 메모리 작업을 사용하여 잠금 없는 데이터 구조를 구현함으로써 MessageQueue 경합 문제를 해결했습니다. 하나 이상의 스레드가 다른 스레드의 일정 동작과 관계없이 항상 진행할 수 있는 경우 데이터 구조나 알고리즘은 잠금 해제됩니다. 이 속성은 일반적으로 달성하기 어려우며 대부분의 코드에서 추구할 가치가 없습니다.
원자적 프리미티브
잠금 없는 소프트웨어는 하드웨어에서 제공하는 원자적 읽기-수정-쓰기 기본 요소를 사용하는 경우가 많습니다.
이전 세대 ARM64 CPU에서 원자는 로드 링크/스토어 조건부 (LL/SC) 루프를 사용했습니다. CPU가 값을 로드하고 주소를 표시합니다. 다른 스레드가 해당 주소에 쓰면 저장에 실패하고 루프가 다시 시도합니다. 스레드는 다른 스레드를 기다리지 않고 계속 시도하여 성공할 수 있으므로 이 작업은 잠금 해제됩니다.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr최신 ARM 아키텍처 (ARMv8.1)는 비교 후 교환 (CAS) 또는 로드 후 추가 (아래에 설명) 형식의 명령어를 포함하는 대형 시스템 확장 (LSE)을 지원합니다. Android 17에서는 LSE가 지원되는 시점을 감지하고 최적화된 명령어를 내보내도록 Android 런타임 (ART) 컴파일러에 지원을 추가했습니다.
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.벤치마크에서 CAS를 사용하는 경합이 심한 코드는 LL/SC 변형보다 약 3배 빠른 속도를 달성합니다.
Java 프로그래밍 언어는 이러한 특수 CPU 명령어에 의존하는 java.util.concurrent.atomic를 통해 원자적 기본 요소를 제공합니다.
데이터 구조: DeliQueue
MessageQueue에서 잠금 경합을 제거하기 위해 Google 엔지니어는 DeliQueue라는 새로운 데이터 구조를 설계했습니다. DeliQueue는 Message 삽입을 Message 처리에서 분리합니다.
Messages(Treiber 스택) 목록: 잠금 없는 스택입니다. 모든 스레드는 경합 없이 여기에 새Messages을 푸시할 수 있습니다.- 우선순위 대기열 (최소 힙): 루퍼 스레드가 독점적으로 소유하는
Messages힙입니다 (따라서 액세스하는 데 동기화나 잠금이 필요하지 않음).
Enqueue: Treiber 스택으로 푸시
Messages 목록은 CAS 루프를 사용하여 헤드 포인터를 업데이트하는 잠금 없는 스택인 Treiber 스택[1]에 보관됩니다.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Java Concurrency in Practice[2]를 기반으로 하는 소스 코드(온라인에서 제공), 퍼블릭 도메인으로 출시됨
모든 생산자는 언제든지 새로운 Message를 스택에 푸시할 수 있습니다. 이는 델리 카운터에서 번호표를 뽑는 것과 같습니다. 번호는 도착한 시간에 따라 결정되지만 음식을 받는 순서는 일치하지 않아도 됩니다. 연결된 스택이므로 모든 Message는 하위 스택입니다. 헤드를 추적하고 앞으로 반복하여 특정 시점의 Message 대기열을 확인할 수 있습니다. 순회 중에 추가되더라도 상단에 푸시된 새로운 Message는 표시되지 않습니다.
Dequeue: 최소 힙으로 대량 전송
처리할 다음 Message를 찾기 위해 Looper는 상단에서 시작하여 스택을 순회하고 이전에 처리한 마지막 Message를 찾을 때까지 반복하여 Treiber 스택에서 새 Message를 처리합니다. Looper가 스택 아래로 이동하면 Message가 기한 순서의 최소 힙에 삽입됩니다. Looper는 힙을 독점적으로 소유하므로 잠금이나 원자 없이 Message를 정렬하고 처리합니다.

스택을 따라 내려가면서 Looper는 스택된 Message에서 이전 항목으로 다시 연결되는 링크도 생성하므로 이중 연결 목록이 형성됩니다. 연결된 목록을 만드는 것은 안전합니다. 스택 아래를 가리키는 링크는 CAS를 사용하여 Treiber 스택 알고리즘을 통해 추가되고 스택 위를 가리키는 링크는 Looper 스레드에서만 읽고 수정하기 때문입니다. 그런 다음 이러한 백 링크를 사용하여 스택의 임의 지점에서 Message를 O(1) 시간 내에 삭제합니다.
이 설계는 프로듀서(작업을 대기열에 게시하는 스레드)에 O (1) 삽입을 제공하고 소비자(Looper)에 상각된 O (log N) 처리를 제공합니다.
최소 힙을 사용하여 Message를 정렬하면 Message가 단일 연결 목록 (상단에 루트)에 유지된 기존 MessageQueue의 근본적인 결함도 해결됩니다. 기존 구현에서는 헤드에서의 삭제가 O(1)이었지만 삽입의 최악의 경우는 O(N)이었습니다. 과부하된 대기열에서 제대로 확장되지 않습니다. 반대로 최소 힙에 삽입하고 최소 힙에서 삭제하는 작업은 대수적으로 확장되므로 평균 성능은 경쟁력이 있지만 테일 지연 시간은 매우 뛰어납니다.
기존 (잠김) MessageQueue | DeliQueue | |
| 삽입 | O(N) | 호출 스레드의 경우 O(1)
|
| 머리에서 삭제 | O(1) | O(logN) |
기존 대기열 구현에서 생산자와 소비자는 잠금을 사용하여 기본 단일 연결 목록에 대한 독점 액세스를 조정했습니다. DeliQueue에서 Treiber 스택은 동시 액세스를 처리하고 단일 소비자는 작업 대기열의 순서를 처리합니다.
삭제: 묘비석을 통한 일관성
DeliQueue는 잠금 없는 Treiber 스택과 단일 스레드 최소 힙을 결합한 하이브리드 데이터 구조입니다. 전역 잠금 없이 이 두 구조를 동기화하는 것은 고유한 문제입니다. 메시지가 스택에 물리적으로 존재하지만 대기열에서 논리적으로 삭제될 수 있기 때문입니다.
이 문제를 해결하기 위해 DeliQueue는 'tombstoning'이라는 기법을 사용합니다. 각 Message는 뒤로 및 앞으로 포인터, 힙 배열의 색인, 삭제되었는지 여부를 나타내는 불리언 플래그를 통해 스택에서 자신의 위치를 추적합니다. Message이 실행될 준비가 되면 Looper 스레드가 삭제된 플래그를 CAS한 다음 힙과 스택에서 삭제합니다.
다른 스레드에서 Message를 삭제해야 하는 경우 데이터 구조에서 즉시 추출하지 않습니다. 대신 다음 단계를 실행합니다.
- 논리적 삭제: 스레드가 CAS를 사용하여
Message의 삭제 플래그를 false에서 true로 원자적으로 설정합니다.Message는 삭제 대기 중임을 나타내는 증거로 데이터 구조에 남아 있습니다. 이를 '묘비'라고 합니다.Message가 삭제 대상으로 지정되면 DeliQueue는Message가 발견될 때마다 대기열에 더 이상 존재하지 않는 것처럼 처리합니다. - 지연된 정리: 데이터 구조에서 실제로 삭제하는 것은
Looper스레드의 책임이며 나중까지 지연됩니다. 스택이나 힙을 수정하는 대신 리무버 스레드는Message를 다른 잠금 없는 자유 목록 스택에 추가합니다. - 구조적 삭제:
Looper만 힙과 상호작용하거나 스택에서 요소를 삭제할 수 있습니다. 절전 모드에서 해제되면 프리리스트를 지우고 포함된Message를 처리합니다. 그런 다음 각Message가 스택에서 연결 해제되고 힙에서 삭제됩니다.
이 접근 방식을 사용하면 힙의 모든 관리가 단일 스레드로 유지됩니다. 필요한 동시 작업 수와 메모리 장벽을 최소화하여 핵심 경로를 더 빠르고 간단하게 만듭니다.
순회: 양성 Java 메모리 모델 데이터 경합
Java 표준 라이브러리의 Future나 Kotlin의 Job 및 Deferred와 같은 대부분의 동시 실행 API에는 작업이 완료되기 전에 작업을 취소하는 메커니즘이 포함되어 있습니다. 이러한 클래스 중 하나의 인스턴스는 기본 작업 단위와 1:1로 일치하며 객체에서 cancel를 호출하면 연결된 특정 작업이 취소됩니다.
오늘날의 Android 기기에는 멀티코어 CPU와 동시 세대별 가비지 컬렉션이 있습니다. 하지만 Android가 처음 개발되었을 때는 각 작업 단위에 하나의 객체를 할당하는 것이 너무 비쌌습니다. 따라서 Android의 Handler는 removeMessages의 다양한 오버로드를 통해 취소를 지원합니다. 특정 Message를 삭제하는 대신 지정된 기준과 일치하는 모든 Message를 삭제합니다. 실제로 이렇게 하려면 removeMessages이 호출되기 전에 삽입된 모든 Message를 반복하고 일치하는 항목을 삭제해야 합니다.
앞으로 반복할 때 스택의 현재 헤드를 읽기 위해 스레드에는 하나의 순서가 지정된 원자 작업만 필요합니다. 그런 다음 일반 필드 읽기를 사용하여 다음 Message를 찾습니다. Message를 삭제하는 동안 Looper 스레드가 next 필드를 수정하면 Looper의 쓰기와 다른 스레드의 읽기가 동기화되지 않습니다. 이를 데이터 경합이라고 합니다. 일반적으로 데이터 경합은 앱에서 누수, 무한 루프, 비정상 종료, 정지 등 심각한 문제를 일으킬 수 있는 심각한 버그입니다. 하지만 좁은 특정 조건에서는 Java 메모리 모델 내에서 데이터 경합이 양호할 수 있습니다. 다음과 같은 스택으로 시작한다고 가정해 보겠습니다.

헤드의 원자적 읽기를 실행하고 A를 확인합니다. A의 다음 포인터는 B를 가리킵니다. B를 처리하는 동시에 루퍼는 A가 C를 가리키도록 업데이트한 다음 D를 가리키도록 업데이트하여 B와 C를 삭제할 수 있습니다.
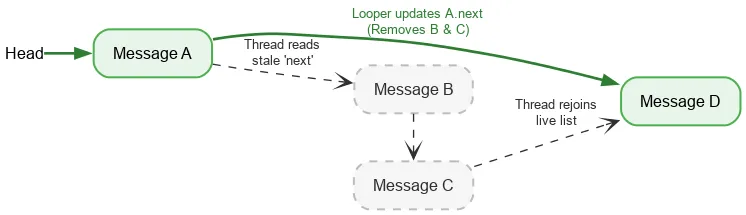
B와 C이 논리적으로 삭제되더라도 B은 C에 대한 다음 포인터를 유지하고 C은 D에 대한 다음 포인터를 유지합니다. 읽기 스레드는 분리된 삭제된 노드를 계속 순회하고 결국 D에서 라이브 스택에 다시 참여합니다.
순회와 삭제 간의 경합을 처리하도록 DeliQueue를 설계하여 안전한 잠금 없는 반복을 허용합니다.
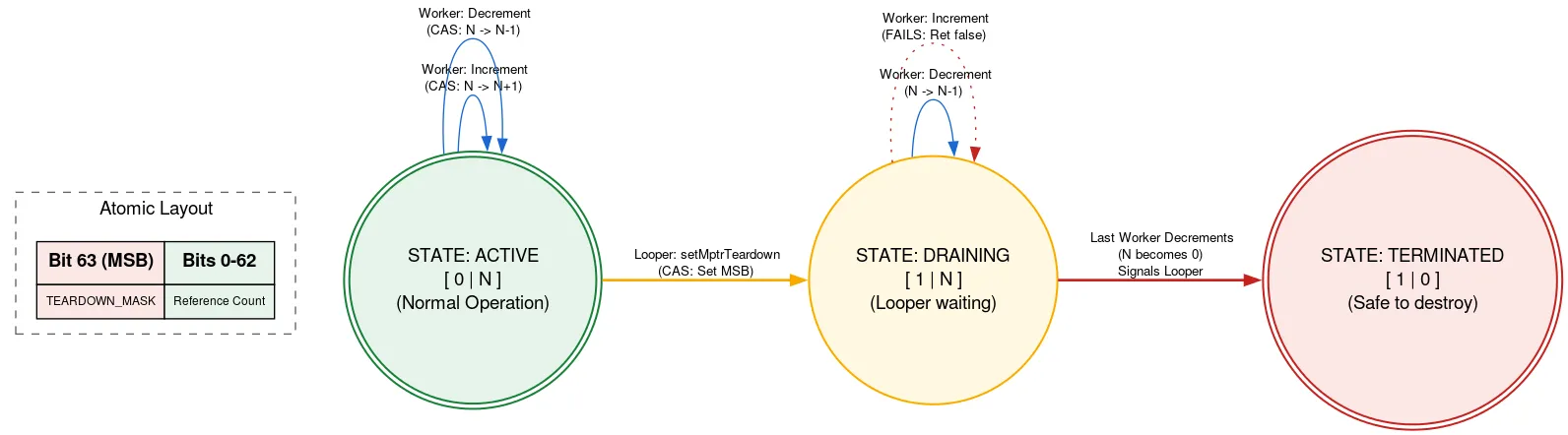
종료: 네이티브 참조 수
Looper는 Looper가 종료된 후 수동으로 해제해야 하는 네이티브 할당으로 지원됩니다. Looper가 종료되는 동안 다른 스레드가 Message를 추가하면 해제된 후 네이티브 할당을 사용할 수 있어 메모리 안전 위반이 발생할 수 있습니다. 원자의 한 비트가 Looper이 종료되는지 여부를 나타내는 데 사용되는 태그가 지정된 참조 카운트를 사용하여 이를 방지합니다.
네이티브 할당을 사용하기 전에 스레드가 refcount 원자를 읽습니다. 종료 비트가 설정된 경우 Looper이 종료되고 기본 할당을 사용하면 안 된다고 반환합니다. 그렇지 않으면 네이티브 할당을 사용하여 활성 스레드 수를 늘리기 위해 CAS를 시도합니다. 필요한 작업을 수행한 후에는 카운트를 감소시킵니다. 종료 비트가 증가 후 감소 전에 설정되고 개수가 이제 0이면 Looper 스레드가 절전 모드에서 해제됩니다.
Looper 스레드가 종료될 준비가 되면 CAS를 사용하여 원자적 종료 비트를 설정합니다. 참조 수가 0이면 네이티브 할당을 해제할 수 있습니다. 그렇지 않으면 네이티브 할당의 마지막 사용자가 참조 수를 감소시킬 때 절전 모드가 해제된다는 것을 알고 자체적으로 절전 모드로 전환됩니다. 이 접근 방식은 Looper 스레드가 다른 스레드의 진행 상황을 기다리지만 종료할 때만 기다린다는 의미입니다. 이는 한 번만 발생하며 성능에 민감하지 않으므로 네이티브 할당을 사용하는 다른 코드는 완전히 잠금 해제 상태로 유지됩니다.
구현에는 다른 많은 트릭과 복잡성이 있습니다. 소스 코드를 검토하여 DeliQueue에 대해 자세히 알아볼 수 있습니다.
최적화: 분기 없는 프로그래밍
DeliQueue를 개발하고 테스트하는 동안 팀은 많은 벤치마크를 실행하고 새 코드를 신중하게 프로파일링했습니다. simpleperf 도구를 사용하여 확인된 한 가지 문제는 Message 비교기 코드로 인해 파이프라인이 플러시되는 것입니다.
표준 비교기는 조건부 점프를 사용하며, 어떤 Message가 먼저 나오는지 결정하는 조건은 아래와 같이 간소화됩니다.
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}이 코드는 조건부 점프 (b.le 및 cbnz 명령어)로 컴파일됩니다. CPU가 조건부 분기를 만나면 조건이 계산될 때까지 분기가 취해지는지 알 수 없으므로 다음에 읽을 명령어를 알 수 없고 분기 예측이라는 기술을 사용하여 추측해야 합니다. 이진 검색과 같은 경우 각 단계에서 분기 방향이 예측할 수 없을 정도로 다르므로 예측의 절반이 틀릴 가능성이 높습니다. 분기 예측은 검색 및 정렬 알고리즘 (예: 최소 힙에 사용되는 알고리즘)에서 효과적이지 않은 경우가 많습니다. 잘못 추측하는 데 드는 비용이 올바르게 추측하여 얻는 개선보다 크기 때문입니다. 분기 예측기가 잘못 추측하면 예측된 값을 가정한 후 실행한 작업을 폐기하고 실제로 취해진 경로에서 다시 시작해야 합니다. 이를 파이프라인 플러시라고 합니다.
이 문제를 찾기 위해 분기 예측기가 잘못 추측하는 스택 트레이스를 기록하는 branch-misses 성능 카운터를 사용하여 벤치마크를 프로파일링했습니다. 그런 다음 아래와 같이 Google pprof를 사용하여 결과를 시각화했습니다.
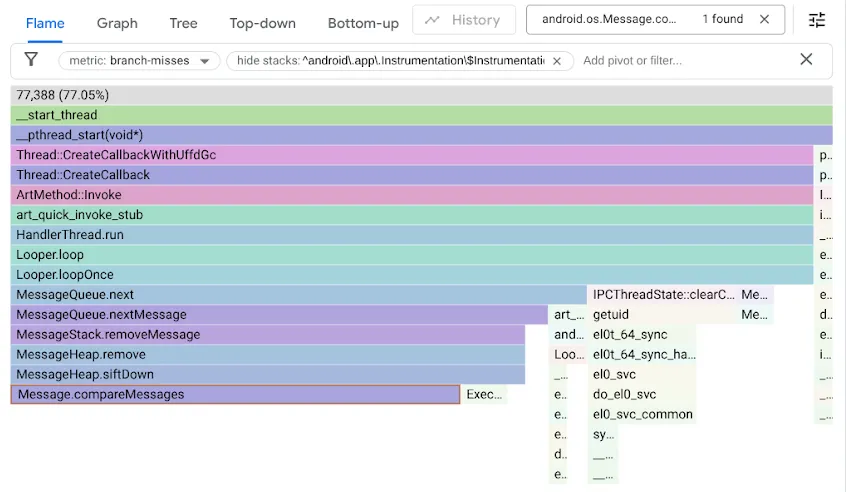
원래 MessageQueue 코드에서는 순서가 지정된 대기열에 단일 연결 목록을 사용했습니다. 삽입은 정렬된 순서로 목록을 선형 검색하여 삽입 지점을 지나가는 첫 번째 요소에서 중지하고 새 Message를 앞에 연결합니다. 헤드에서 삭제하려면 헤드의 연결을 해제하면 됩니다. DeliQueue는 균형 잡힌 데이터 구조에서 비교를 통해 왼쪽 하위 요소 또는 오른쪽 하위 요소로 순회를 안내할 가능성이 동일한 로그 복잡성을 사용하여 일부 요소를 재정렬 (위 또는 아래로 체질)해야 하는 최소 힙을 사용합니다. 새 알고리즘은 점근적으로 더 빠르지만 검색 코드가 절반의 시간 동안 분기 누락으로 인해 멈추면서 새로운 병목 현상이 발생합니다.
분기 누락으로 인해 힙 코드가 느려진다는 것을 깨닫고 분기 없는 프로그래밍을 사용하여 코드를 최적화했습니다.
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}최적화를 이해하려면 컴파일러 탐색기에서 두 예시를 디스어셈블하고 예상 CPU 사이클 타임라인을 생성할 수 있는 CPU 시뮬레이터인 LLVM-MCA를 사용하세요.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
when 필드를 비교하여 결과를 이미 알고 있는 경우 insertSeq 필드를 비교하지 않는 b.le라는 조건부 분기가 있습니다.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
여기서 분기 없는 구현은 분기 코드의 최단 경로보다도 사이클과 명령어가 적게 필요하므로 모든 경우에 더 좋습니다. 더 빠른 구현과 잘못 예측된 분기 삭제로 인해 일부 벤치마크에서 5배의 개선이 이루어졌습니다.
하지만 이 기법이 항상 적용되는 것은 아닙니다. 분기 없는 접근 방식은 일반적으로 폐기될 작업을 실행해야 하며, 분기를 대부분 예측할 수 있는 경우 낭비된 작업으로 인해 코드가 느려질 수 있습니다. 또한 브랜치를 삭제하면 데이터 종속성이 도입되는 경우가 많습니다. 최신 CPU는 사이클당 여러 작업을 실행하지만 이전 명령의 입력이 준비될 때까지 명령을 실행할 수 없습니다. 반면 CPU는 분기의 데이터를 추측하고 분기가 올바르게 예측되면 미리 작업할 수 있습니다.
테스트 및 검증
잠금 없는 알고리즘의 정확성을 검증하는 것은 매우 어렵습니다.
개발 중 지속적인 검증을 위한 표준 단위 테스트 외에도 대기열 불변성을 검증하고 데이터 경합이 있는 경우 이를 유도하기 위해 엄격한 스트레스 테스트를 작성했습니다. Google의 테스트 연구소에서는 에뮬레이트된 기기와 실제 하드웨어에서 수백만 개의 테스트 인스턴스를 실행할 수 있었습니다.
Java ThreadSanitizer (JTSan) 계측을 사용하면 동일한 테스트를 사용하여 코드에서 일부 데이터 경합을 감지할 수도 있습니다. JTSan은 DeliQueue에서 문제가 있는 데이터 레이스를 찾지 못했지만, 놀랍게도 Robolectric 프레임워크에서 동시성 버그 2개를 감지했으며, Google에서는 이를 즉시 수정했습니다.
디버깅 기능을 개선하기 위해 새로운 분석 도구를 구축했습니다. 아래는 한 스레드가 다른 스레드에 Message를 과부하하여 MessageQueue 계측 기능 덕분에 Perfetto에서 확인할 수 있는 대규모 백로그가 발생하는 Android 플랫폼 코드의 문제를 보여주는 예입니다.
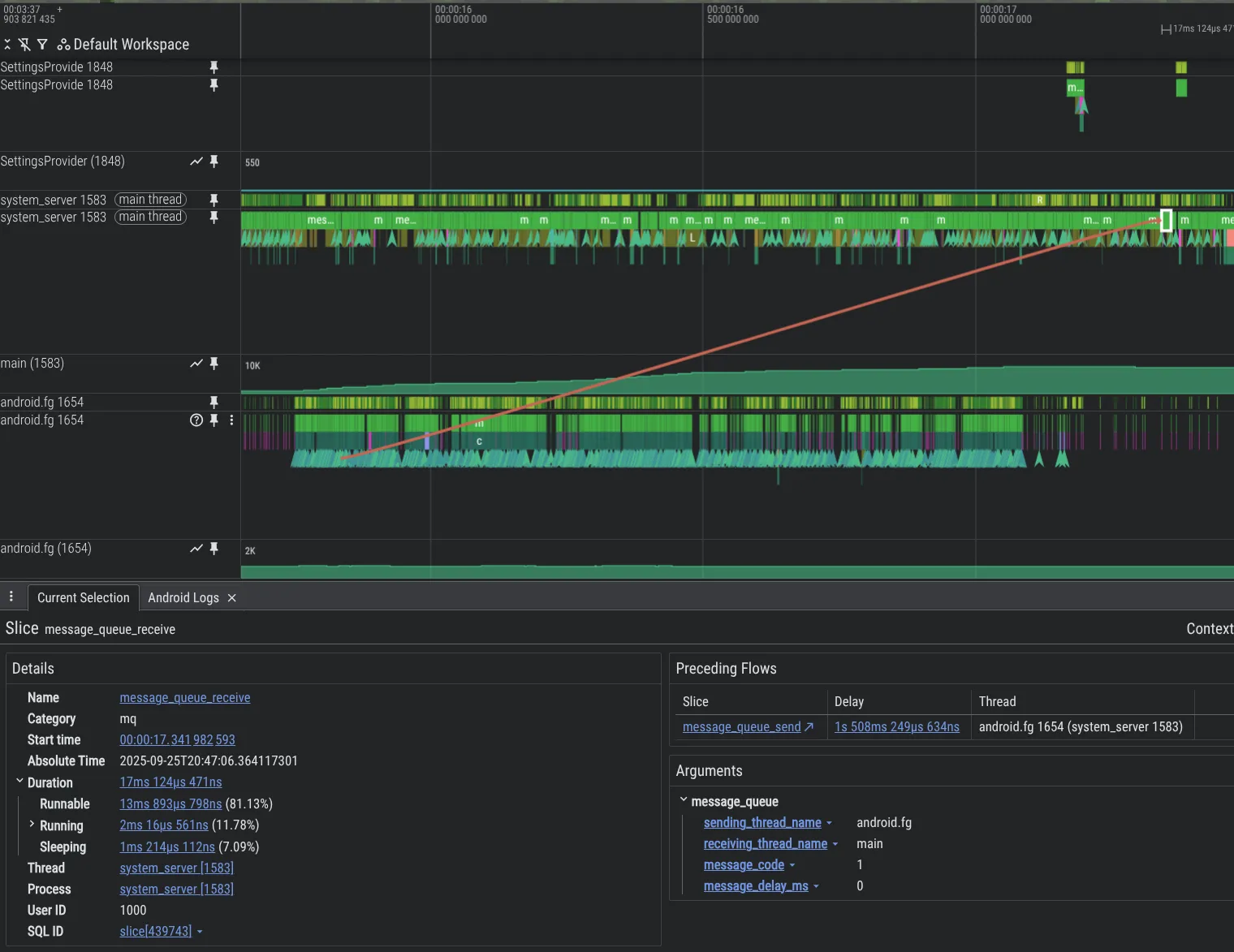
system_server 프로세스에서 MessageQueue 추적을 사용 설정하려면 Perfetto 구성에 다음을 포함하세요.
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}효과
DeliQueue는 MessageQueue에서 잠금을 제거하여 시스템 및 앱 성능을 개선합니다.
- 합성 벤치마크: 개선된 동시성 (Treiber 스택)과 더 빠른 삽입 (최소 힙) 덕분에 사용 중인 대기열에 다중 스레드 삽입이 기존
MessageQueue보다 최대 5,000배 빠릅니다. - 내부 베타 테스터로부터 획득한 Perfetto 트레이스에서 잠금 경합에 소요된 앱 기본 스레드 시간이 15% 감소한 것으로 확인됩니다.
- 동일한 테스트 기기에서 잠금 경합이 감소하면 다음과 같은 사용자 환경이 크게 개선됩니다.
- 앱에서 프레임 누락이 4% 감소했습니다.
- 시스템 UI 및 런처 상호작용에서 누락된 프레임이 7.7% 입니다.
- 앱 시작부터 첫 번째 프레임이 그려질 때까지 걸리는 시간이 95% 백분위수에서 9.1%감소했습니다.
다음 단계
DeliQueue는 Android 17에서 앱에 출시됩니다. 앱 개발자는 Android 개발자 블로그에서 새로운 잠금 해제 MessageQueue를 위한 앱 준비를 검토하여 앱을 테스트하는 방법을 알아야 합니다.
참조
[1] Treiber, R.K., 1986. 시스템 프로그래밍: 병렬 처리 대처 International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 제품 소식
제품 소식3월에 Google은 실제 Android 개발 작업을 위한 LLM 리더보드인 Android Bench를 도입했습니다. 이후 Google은 광고주의 의견을 바탕으로 오픈 가중치 모델을 평가하고 리더보드에 비용 및 효율성 측정기준을 추가하는 등 벤치마크를 개선했습니다.
Zoe Lopez-Latorre • 3분 읽기 -

 제품 소식
제품 소식Google Play는 사용자에게 최상의 경험을 제공하는 동시에 개발자가 성공하는 데 필요한 도구와 적응력을 갖출 수 있도록 최선을 다하고 있습니다.
Paul Feng • 전문 길이: 3분 -

 제품 소식
제품 소식지난해 Google은 생태계 보안을 강화하고 악의적인 행위자가 익명성 뒤에 숨어 유해한 앱을 출시하는 것을 막기 위해 Android 개발자 인증을 도입했습니다.
Matthew Forsythe • 전문 길이: 2분
Android 개발 관련 최신 정보를 이메일로 받아 보세요.
