

No Android 17, os apps destinados ao SDK 37 ou mais recente vão receber uma nova implementação do MessageQueue sem bloqueio. A nova implementação melhora o desempenho e reduz os frames perdidos, mas pode interromper clientes que refletem em campos e métodos particulares do MessageQueue. Para saber mais sobre a mudança de comportamento e como reduzir o impacto, confira a documentação sobre a mudança de comportamento do MessageQueue. Esta postagem técnica do blog oferece uma visão geral da reestruturação do MessageQueue e de como analisar problemas de disputa de bloqueio usando o Perfetto.
O Looper controla a linha de execução da interface de todos os aplicativos Android. Ele extrai o trabalho de uma MessageQueue, o envia para um Handler e repete. Por duas décadas, o MessageQueue usou um único bloqueio de monitor (ou seja, um bloco de código synchronized) para proteger o estado.
O Android 17 introduz uma atualização significativa nesse componente: uma implementação sem bloqueio chamada DeliQueue.
Esta postagem explica como os bloqueios afetam o desempenho da interface, como analisar esses problemas com o Perfetto e os algoritmos e otimizações específicos usados para melhorar a linha de execução principal do Android.
O problema: disputa de bloqueio e inversão de prioridade
A função legada MessageQueue funcionava como uma fila de prioridade protegida por um único bloqueio. Se uma linha de execução em segundo plano postar uma mensagem enquanto a linha de execução principal realiza a manutenção da fila, a linha de execução em segundo plano vai bloquear a principal.
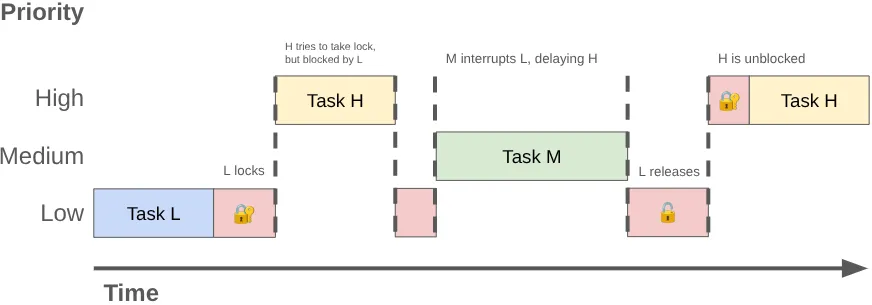
Quando duas ou mais linhas de execução competem pelo uso exclusivo do mesmo bloqueio, isso é chamado de disputa de bloqueio. Essa disputa pode causar inversão de prioridade, resultando em instabilidade da interface e outros problemas de desempenho.
A inversão de prioridade pode acontecer quando uma linha de execução de alta prioridade (como a linha de execução da UI) é obrigada a esperar por uma linha de execução de baixa prioridade. Considere esta sequência:
- Uma thread em segundo plano de baixa prioridade adquire o bloqueio
MessageQueuepara postar o resultado do trabalho realizado. - Uma linha de execução de prioridade média se torna executável, e o programador do kernel aloca tempo de CPU para ela, interrompendo a linha de execução de baixa prioridade.
- A linha de execução de UI de alta prioridade conclui a tarefa atual e tenta ler da fila, mas é bloqueada porque a linha de execução de baixa prioridade mantém o bloqueio.
A linha de execução de baixa prioridade bloqueia a linha de execução da interface, e o trabalho de prioridade média a atrasa ainda mais.
Analisar a disputa com o Perfetto
É possível diagnosticar esses problemas usando o Perfetto. Em um rastreamento padrão, uma linha de execução bloqueada em um bloqueio de monitor entra no estado de espera, e o Perfetto mostra uma fração indicando o proprietário do bloqueio.
Ao consultar dados de rastreamento, procure segmentos chamados "monitor contention with …" seguidos pelo nome da linha de execução proprietária do bloqueio e o site do código em que o bloqueio foi adquirido.
Estudo de caso: instabilidade do acesso rápido
Para ilustrar, vamos analisar um rastreamento em que um usuário teve instabilidade ao navegar na página inicial de um smartphone Pixel imediatamente após tirar uma foto no app de câmera. Abaixo, vemos uma captura de tela do Perfetto mostrando os eventos que levaram ao frame perdido:
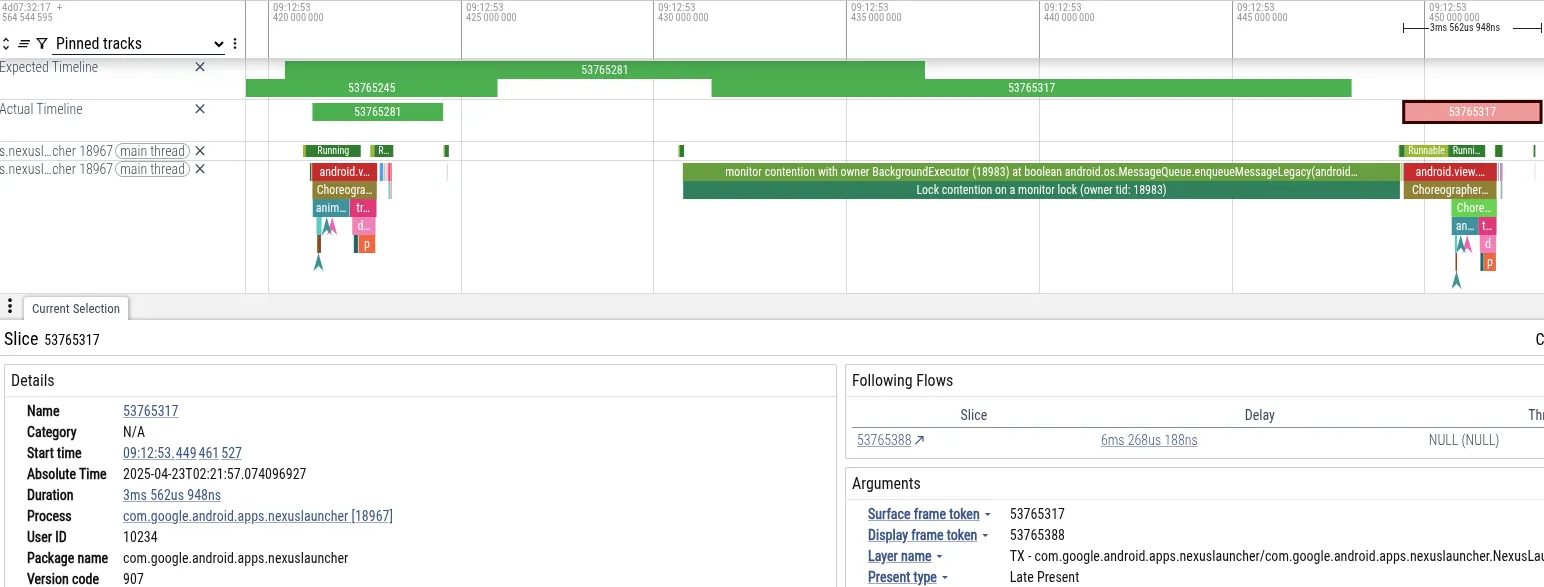
- Sintoma:a linha de execução principal do Launcher perdeu o prazo do frame. Ele ficou bloqueado por 18 ms, o que excede o prazo de 16 ms necessário para a renderização de 60 Hz.
- Diagnóstico:o Perfetto mostrou que a linha de execução principal estava bloqueada no bloqueio
MessageQueue. Uma linha de execução "BackgroundExecutor" era proprietária do bloqueio. - Causa raiz:o BackgroundExecutor é executado em Process.THREAD_PRIORITY_BACKGROUND (prioridade muito baixa). Ele realizou uma tarefa não urgente (verificar os limites de uso de apps). Ao mesmo tempo, threads de prioridade média estavam usando o tempo da CPU para processar dados da câmera. O programador do SO interrompeu a linha de execução do BackgroundExecutor para executar as linhas de execução da câmera.
Essa sequência fez com que a linha de execução da UI do Launcher (alta prioridade) fosse bloqueada indiretamente pela linha de execução do worker da câmera (prioridade média), o que impedia que a linha de execução em segundo plano do Launcher (baixa prioridade) liberasse o bloqueio.
Consultar rastreamentos com PerfettoSQL
Você pode usar o PerfettoSQL para consultar dados de rastreamento de padrões específicos. Isso é útil se você tiver um grande banco de rastreamentos de dispositivos ou testes de usuários e estiver procurando rastreamentos específicos que demonstrem um problema.
Por exemplo, esta consulta encontra contenção de MessageQueue coincidente com frames descartados (jank):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
Neste exemplo mais complexo, faça a junção de dados de rastreamento que abrangem várias tabelas para identificar a disputa de MessageQueue durante a inicialização do app:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Você pode usar seu LLM favorito para escrever consultas do PerfettoSQL e encontrar outros padrões.
No Google, usamos o BigTrace para executar consultas do PerfettoSQL em milhões de rastros. Ao fazer isso, confirmamos que o que vimos de forma isolada era, na verdade, um problema sistêmico. Os dados revelaram que a disputa de bloqueio MessageQueue afeta os usuários em todo o ecossistema, comprovando a necessidade de uma mudança arquitetônica fundamental.
Solução: simultaneidade sem bloqueio
Para resolver o problema de disputa de MessageQueue, implementamos uma estrutura de dados sem bloqueio, usando operações de memória atômica em vez de bloqueios exclusivos para sincronizar o acesso ao estado compartilhado. Uma estrutura de dados ou um algoritmo é sem bloqueio se pelo menos uma linha de execução sempre puder progredir, independentemente do comportamento de programação das outras linhas. Essa propriedade geralmente é difícil de alcançar e não vale a pena buscar na maioria dos códigos.
As primitivas atômicas
O software sem bloqueio geralmente depende de primitivos atômicos de leitura-modificação-gravação fornecidos pelo hardware.
Em CPUs ARM64 de gerações mais antigas, os atômicos usavam um loop Load-Link/Store-Conditional (LL/SC). A CPU carrega um valor e marca o endereço. Se outra linha de execução gravar nesse endereço, o armazenamento vai falhar e o loop vai tentar novamente. Como as linhas de execução podem continuar tentando e ter sucesso sem esperar por outra linha, essa operação não tem bloqueio.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrAs arquiteturas ARM mais recentes (ARMv8.1) são compatíveis com extensões grandes do sistema (LSE, na sigla em inglês), que incluem instruções na forma de Compare-And-Swap (CAS) ou Load-And-Add (demonstrado abaixo). No Android 17, adicionamos suporte ao compilador do Android Runtime (ART) para detectar quando o LSE é compatível e emitir instruções otimizadas:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Nos nossos comparativos, o código de alta disputa que usa CAS alcança uma aceleração de aproximadamente 3 vezes em relação à variante LL/SC.
A linguagem de programação Java oferece primitivos atômicos via java.util.concurrent.atomic, que dependem dessas e de outras instruções especializadas da CPU.
A estrutura de dados: DeliQueue
Para remover a disputa de bloqueio de MessageQueue, nossos engenheiros projetaram uma nova estrutura de dados chamada DeliQueue. O DeliQueue separa a inserção de Message do processamento de Message:
- A lista de
Messages(pilha de Treiber): uma pilha sem bloqueio. Qualquer encadeamento pode enviar novosMessagesaqui sem disputa. - A fila de prioridade (min-heap): um heap de
Messagesa ser processado, de propriedade exclusiva da linha de execução do Looper. Portanto, não é necessário sincronização nem bloqueios para acessar.
Enfileirar: enviar para uma pilha Treiber
A lista de Messages é mantida em uma pilha de Treiber [1], uma pilha sem bloqueio que usa um loop CAS para atualizar o ponteiro de cabeçalho.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Código-fonte baseado em Java Concurrency in Practice [2], disponível on-line e lançado em domínio público
Qualquer produtor pode enviar novos Messages para a pilha a qualquer momento. É como pegar uma senha em uma padaria: seu número é determinado por quando você chegou, mas a ordem em que você recebe a comida não precisa corresponder. Como é uma pilha vinculada, cada Message é uma subpilha. É possível saber como era a fila de Message em qualquer momento rastreando o cabeçalho e iterando para frente. Não é possível ver novos Messages enviados para cima, mesmo que eles estejam sendo adicionados durante a travessia.
Remover da fila: transferência em massa para um minheap
Para encontrar o próximo Message a ser processado, o Looper processa novos Messages da pilha Treiber percorrendo a pilha de cima para baixo e repetindo até encontrar o último Message processado anteriormente. À medida que o Looper percorre a pilha, ele insere Messages no minheap ordenado por prazo. Como o Looper é o único proprietário do heap, ele ordena e processa Messages sem bloqueios ou operações atômicas.

Ao percorrer a pilha, o Looper também cria links de Messages empilhados de volta aos predecessores, formando uma lista duplamente vinculada. A criação da lista vinculada é segura porque os links que apontam para baixo na pilha são adicionados pelo algoritmo de pilha de Treiber com CAS, e os links para cima na pilha são lidos e modificados apenas pela thread Looper. Esses backlinks são usados para remover Messages de pontos arbitrários na pilha em tempo O(1).
Esse design oferece inserção O(1) para produtores (threads que postam trabalho na fila) e processamento O(log N) amortizado para o consumidor (o Looper).
Usar um min-heap para ordenar Messages também resolve uma falha fundamental no MessageQueue legado, em que os Messages eram mantidos em uma lista encadeada única (com raiz na parte superior). Na implementação legada, a remoção do início era O(1), mas a inserção tinha um caso pior de O(N), com escalonamento ruim para filas sobrecarregadas. Por outro lado, a inserção e a remoção do min-heap são dimensionadas de forma logarítmica, oferecendo um desempenho médio competitivo, mas realmente excelente em latências de cauda.
Legado (bloqueado) MessageQueue | DeliQueue | |
| Inserir | O(N) | O(1) para a linha de execução de chamada O(logN) para a linha de execução |
| Remover da cabeça | O(1) | O(logN) |
Na implementação legada da fila, os produtores e o consumidor usavam um bloqueio para coordenar o acesso exclusivo à lista encadeada simples subjacente. No DeliQueue, a pilha Treiber processa o acesso simultâneo, e o único consumidor processa a ordenação da fila de trabalho.
Remoção: consistência por lápides
A DeliQueue é uma estrutura de dados híbrida que une uma pilha de Treiber sem bloqueio com um minheap de uma única linha de execução. Manter essas duas estruturas sincronizadas sem um bloqueio global apresenta um desafio único: uma mensagem pode estar fisicamente presente na pilha, mas removida logicamente da fila.
Para resolver isso, o DeliQueue usa uma técnica chamada "tombstoning". Cada Message rastreia sua posição na pilha usando os ponteiros para trás e para frente, o índice no array do heap e uma flag booleana que indica se ele foi removido. Quando um Message está pronto para ser executado, a linha de execução Looper faz CAS na flag removida e a remove do heap e da pilha.
Quando outra linha de execução precisa remover um Message, ele não é extraído imediatamente da estrutura de dados. Em vez disso, ele executa as seguintes etapas:
- Remoção lógica: a linha de execução usa um CAS para definir atomicamente a flag de remoção do
Messagede "false" para "true". OMessagepermanece na estrutura de dados como evidência da remoção pendente, um chamado "túmulo". Depois que umMessageé sinalizado para remoção, o DeliQueue o trata como se ele não existisse mais na fila sempre que é encontrado. - Limpeza adiada: a remoção real da estrutura de dados é responsabilidade da thread
Loopere é adiada até mais tarde. Em vez de modificar a pilha ou o heap, a thread do removedor adiciona oMessagea outra pilha freelist sem bloqueio. - Remoção estrutural: somente o
Looperpode interagir com o heap ou remover elementos da pilha. Quando ele é ativado, limpa a lista livre e processa osMessages que continha. CadaMessageé desvinculado da pilha e removido do heap.
Essa abordagem mantém todo o gerenciamento do heap em uma única linha de execução. Ele minimiza o número de operações simultâneas e barreiras de memória necessárias, tornando o caminho crítico mais rápido e simples.
Traversal: benign Java memory model data races
A maioria das APIs de simultaneidade, como Future na biblioteca padrão do Java ou Job e Deferred do Kotlin, inclui um mecanismo para cancelar o trabalho antes da conclusão. Uma instância de uma dessas classes corresponde a uma unidade de trabalho subjacente, e chamar cancel em um objeto cancela as operações específicas associadas a ele.
Os dispositivos Android atuais têm CPUs multi-core e coleta de lixo simultânea e geracional. Mas, quando o Android foi desenvolvido, era muito caro alocar um objeto para cada unidade de trabalho. Consequentemente, o Handler do Android oferece suporte ao cancelamento por várias sobrecargas de removeMessages. Em vez de remover um Message específico, ele remove todos os Messages que correspondem aos critérios especificados. Na prática, isso exige iterar por todos os Messages inseridos antes de removeMessages ser chamado e remover os que correspondem.
Ao iterar para frente, uma linha de execução só exige uma operação atômica ordenada para ler o cabeçalho atual da pilha. Depois disso, leituras de campo comuns são usadas para encontrar o próximo Message. Se a linha Looper modificar os campos next ao remover Messages, a gravação do Looper e a leitura de outra linha não serão sincronizadas. Isso é uma disputa de dados. Normalmente, uma disputa de dados é um bug grave que pode causar grandes problemas no app: vazamentos, loops infinitos, falhas, travamentos e muito mais. No entanto, em determinadas condições específicas, as disputas de dados podem ser benignas no modelo de memória Java. Suponha que começamos com uma pilha de:

Realizamos uma leitura atômica do cabeçalho e vemos A. O próximo ponteiro de A aponta para B. Ao mesmo tempo em que processamos B, o looper pode remover B e C atualizando A para apontar para C e depois para D.
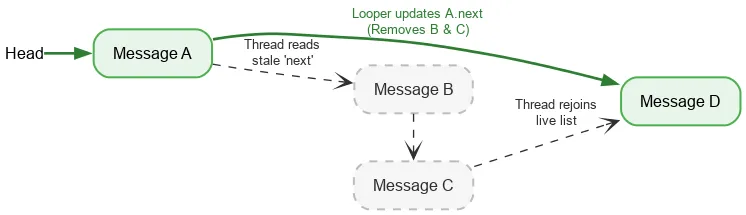
Embora B e C sejam removidos logicamente, B mantém o próximo ponteiro para C, e C para D. A linha de execução de leitura continua atravessando os nós removidos e eventualmente se junta à pilha ativa em D.
Ao projetar o DeliQueue para lidar com disputas entre travessia e remoção, permitimos uma iteração segura e sem bloqueios.
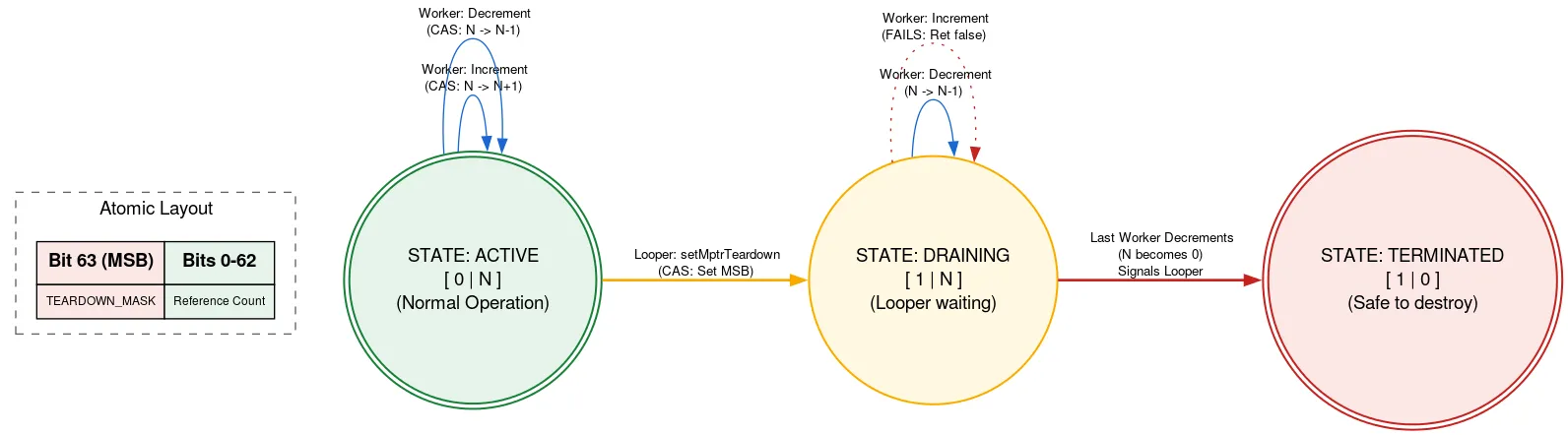
Saindo: contagem de referência nativa
Looper é apoiado por uma alocação nativa que precisa ser liberada manualmente quando o Looper é encerrado. Se outra linha de execução estiver adicionando Messages enquanto o Looper está sendo encerrado, ela poderá usar a alocação nativa depois que ela for liberada, o que é uma violação de segurança de memória. Para evitar isso, usamos uma contagem de referência com tag, em que um bit do atômico é usado para indicar se o Looper está sendo encerrado.
Antes de usar a alocação nativa, uma linha de execução lê o refcount atômico. Se o bit de saída estiver definido, ele vai retornar que o Looper está sendo encerrado e que a alocação nativa não deve ser usada. Caso contrário, ele tenta um CAS para incrementar o número de linhas de execução ativas usando a alocação nativa. Depois de fazer o que precisa, ele diminui a contagem. Se o bit de saída foi definido após o incremento, mas antes do decremento, e a contagem agora é zero, ele ativa a thread Looper.
Quando a thread Looper está pronta para sair, ela usa CAS para definir o bit de saída no atômico. Se o refcount for 0, ele poderá liberar a alocação nativa. Caso contrário, ele fica parado, sabendo que será ativado quando o último usuário da alocação nativa diminuir a contagem de referências. Essa abordagem significa que a linha de execução Looper aguarda o progresso de outras linhas de execução, mas apenas quando está sendo encerrada. Isso só acontece uma vez e não é sensível ao desempenho. Além disso, mantém o outro código para usar a alocação nativa totalmente sem bloqueio.
Há muitos outros truques e complexidades na implementação. Para saber mais sobre o DeliQueue, consulte o código-fonte.
Otimização: programação sem ramificações
Ao desenvolver e testar o DeliQueue, a equipe executou muitos comparativos e criou perfis do novo código com cuidado. Um problema identificado usando a ferramenta simpleperf foram os fluxos de pipeline causados pelo código do comparador Message.
Um comparador padrão usa saltos condicionais, com a condição para decidir qual Message vem primeiro simplificada abaixo:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Esse código é compilado para jumps condicionais (instruções b.le e cbnz). Quando a CPU encontra uma ramificação condicional, ela não sabe se a ramificação será executada até que a condição seja calculada. Portanto, ela não sabe qual instrução ler em seguida e precisa adivinhar, usando uma técnica chamada previsão de ramificação. Em um caso como a pesquisa binária, a direção da ramificação será imprevisivelmente diferente em cada etapa. Portanto, é provável que metade das previsões esteja errada. A previsão de ramificação geralmente é ineficaz em algoritmos de pesquisa e classificação (como o usado em um min-heap), porque o custo de adivinhar errado é maior do que a melhoria de adivinhar certo. Quando o preditor de ramificação adivinha errado, ele precisa descartar o trabalho feito depois de assumir o valor previsto e começar de novo pelo caminho que foi realmente tomado. Isso é chamado de limpeza de pipeline.
Para encontrar esse problema, criamos um perfil dos nossos comparativos de mercado usando o contador de desempenho branch-misses, que registra rastreamentos de pilha em que o preditor de ramificação adivinha errado. Em seguida, visualizamos os resultados com o Google pprof, conforme mostrado abaixo:
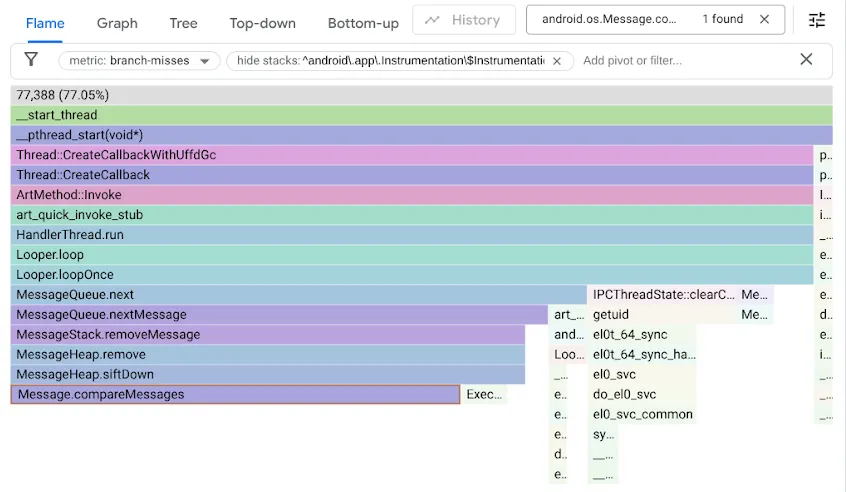
O código MessageQueue original usava uma lista encadeada simples para a fila ordenada. A inserção percorre a lista em ordem classificada como uma pesquisa linear, parando no primeiro elemento que está além do ponto de inserção e vinculando o novo Message antes dele. Para remover a cabeça, basta desvincular. Enquanto o DeliQueue usa um min-heap, em que as mutações exigem a reordenação de alguns elementos (peneirando para cima ou para baixo) com complexidade logarítmica em uma estrutura de dados balanceada, em que qualquer comparação tem uma chance igual de direcionar a travessia para um filho à esquerda ou à direita. O novo algoritmo é assintoticamente mais rápido, mas expõe um novo gargalo, já que o código de pesquisa para em erros de ramificação metade do tempo.
Percebendo que as falhas de ramificação estavam diminuindo a velocidade do nosso código de heap, otimizamos o código usando a programação sem ramificação:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Para entender a otimização, desmonte os dois exemplos no Compiler Explorer e use o LLVM-MCA, um simulador de CPU que pode gerar uma linha do tempo estimada de ciclos de CPU.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Observe a ramificação condicional, b.le, que evita comparar os campos insertSeq se o resultado já for conhecido pela comparação dos campos when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
Nesse caso, a implementação sem ramificação usa menos ciclos e instruções do que até mesmo o caminho mais curto pelo código ramificado. Ela é melhor em todos os casos. A implementação mais rápida e a eliminação de ramificações previstas incorretamente resultaram em uma melhoria de cinco vezes em alguns dos nossos comparativos de mercado.
No entanto, essa técnica nem sempre é aplicável. As abordagens sem ramificação geralmente exigem um trabalho que será descartado. Se a ramificação for previsível na maioria das vezes, esse trabalho desperdiçado poderá deixar seu código mais lento. Além disso, a remoção de uma ramificação geralmente introduz uma dependência de dados. As CPUs modernas executam várias operações por ciclo, mas não podem executar uma instrução até que as entradas de uma instrução anterior estejam prontas. Por outro lado, uma CPU pode especular sobre dados em ramificações e trabalhar com antecedência se uma ramificação for prevista corretamente.
Teste e validação
Validar a correção de algoritmos sem bloqueio é notoriamente difícil.
Além dos testes de unidade padrão para validação contínua durante o desenvolvimento, também escrevemos testes de estresse rigorosos para verificar os invariantes da fila e tentar induzir condições de disputa de dados, se existissem. Nos nossos laboratórios de teste, podemos executar milhões de instâncias de teste em dispositivos emulados e em hardware real.
Com a instrumentação do Java ThreadSanitizer (JTSan), podemos usar os mesmos testes para detectar algumas condições de disputa de dados no nosso código. O JTSan não encontrou nenhuma disputa de dados problemática no DeliQueue, mas, surpreendentemente, detectou dois bugs de simultaneidade no framework Robolectric, que corrigimos imediatamente.
Para melhorar nossos recursos de depuração, criamos novas ferramentas de análise. Confira abaixo um exemplo que mostra um problema no código da plataforma Android em que uma linha de execução está sobrecarregando outra com Messages, causando um grande backlog, visível no Perfetto graças ao recurso de instrumentação MessageQueue que adicionamos.
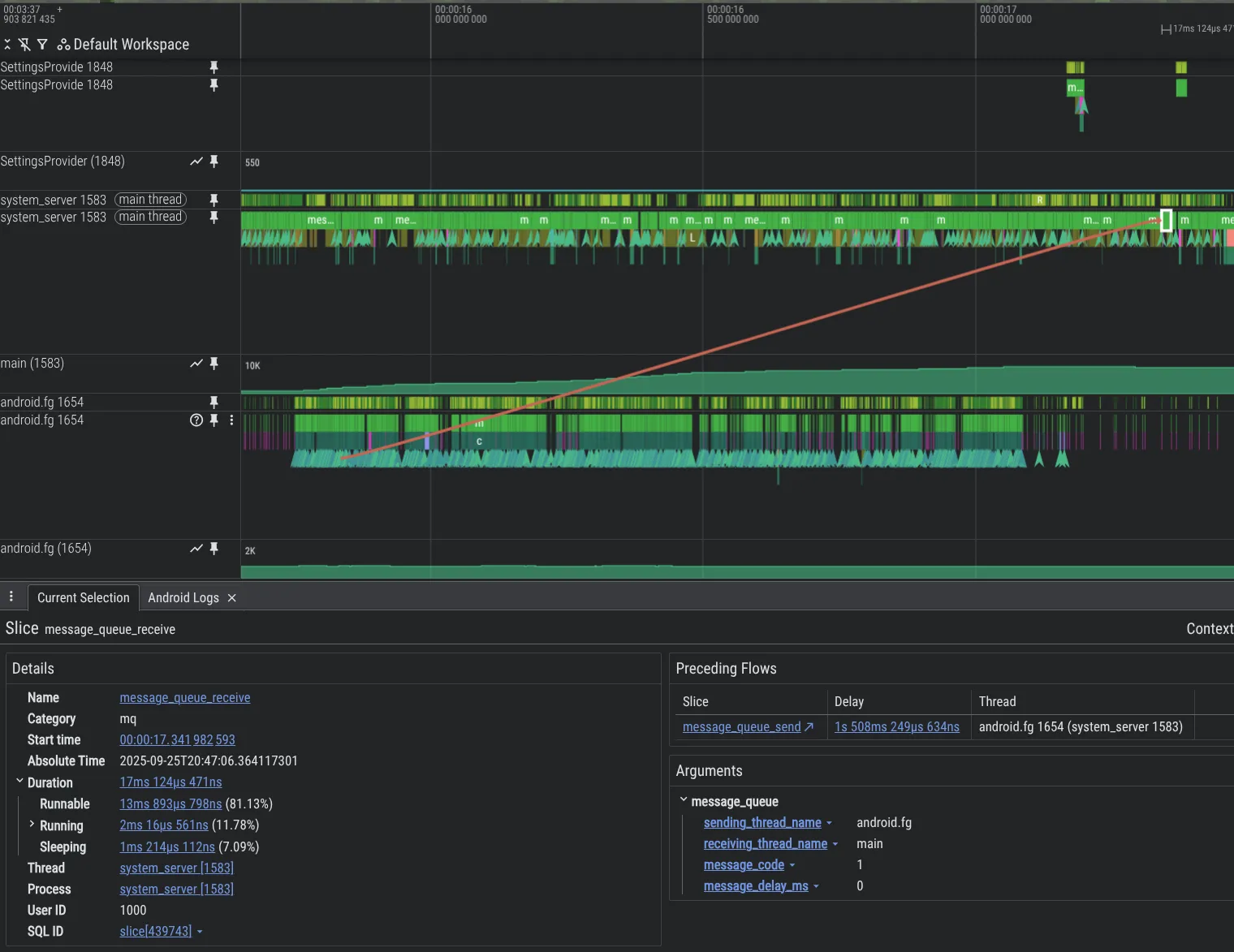
Para ativar o rastreamento MessageQueue no processo system_server, inclua o seguinte na configuração do Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Impacto
O DeliQueue melhora o desempenho do sistema e dos apps ao eliminar bloqueios de MessageQueue.
- Benchmarks sintéticos:as inserções multithread em filas ocupadas são até 5.000 vezes mais rápidas do que o
MessageQueuelegado, graças à melhoria da simultaneidade (a pilha de Treiber) e inserções mais rápidas (o min-heap). - Em Rastreamentos do Perfetto adquiridos de testadores Beta internos, vemos uma redução de 15% no tempo da linha de execução principal do app gasto em contenção de bloqueio.
- Nos mesmos dispositivos de teste, a redução da disputa de bloqueio leva a melhorias significativas na experiência do usuário, como:
- -4% de frames perdidos em apps.
- -7,7% de frames perdidos nas interações da interface do sistema e do acesso rápido.
- -9,1% no tempo entre a inicialização do app e o primeiro frame renderizado, no 95º percentil.
Próximas etapas
O DeliQueue está sendo lançado para apps no Android 17. Os desenvolvedores de apps precisam ler o artigo "Como preparar seu app para o novo MessageQueue sem bloqueio" no blog para desenvolvedores Android e saber como testar os apps.
Referências
[1] Treiber, R.K., 1986. Programação de sistemas: lidando com o paralelismo. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., e Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
-

 Novidades sobre produtos
Novidades sobre produtosEm março, apresentamos o Android Bench, nosso ranking de LLMs para tarefas de desenvolvimento em Android no mundo real. Desde então, aprimoramos o comparativo com base no seu feedback, incluindo a avaliação de modelos de peso aberto e a adição de dimensões de custo e eficiência ao ranking.
Zoe Lopez-Latorre • Leitura de 3 minutos -

 Novidades sobre produtos
Novidades sobre produtosNo Google Play, temos o compromisso de oferecer a melhor experiência possível aos usuários, além de garantir que os desenvolvedores tenham as ferramentas e a adaptabilidade necessárias para conquistar o sucesso.
Paul Feng • Leitura de 3 minutos -

 Novidades sobre produtos
Novidades sobre produtosNo ano passado, lançamos a verificação de desenvolvedor do Android para reforçar a segurança do ecossistema e impedir que usuários maliciosos se escondam no anonimato para lançar apps nocivos.
Matthew Forsythe • Leitura de 2 minutos
Receba os insights mais recentes sobre desenvolvimento Android na sua caixa de entrada semanalmente.
