
The trace view in the CPU Profiler provides several ways to view information from recorded traces.
For method traces and function traces, you can view the Call Chart directly in the Threads timeline and the Flame Chart, Top Down, Bottom Up, and Events tabs from the Analysis pane. For callstack frames, you can view the part of the code that has been executed, and why it was invoked. For system traces, you can view the Trace Events directly in the Threads timeline, and the Flame Chart, Top Down, Bottom Up, and Events tabs from the Analysis pane.
Mouse and keyboard shortcuts are available for easier navigation of Call Charts or Trace Events.
Inspect traces using the Call Chart
The Call Chart provides a graphical representation of a method trace or function trace, where the period and timing of a call is represented on the horizontal axis, and its callees are shown along the vertical axis. Calls to system APIs are shown in orange, calls to your app’s own methods are shown in green, and calls to third-party APIs (including Java language APIs) are shown in blue. Figure 4 shows an example call chart and illustrates the concept of self time, children time, and total time for a given method or function. You can learn more about these concepts in the section on how to inspect traces using Top Down and Bottom Up.
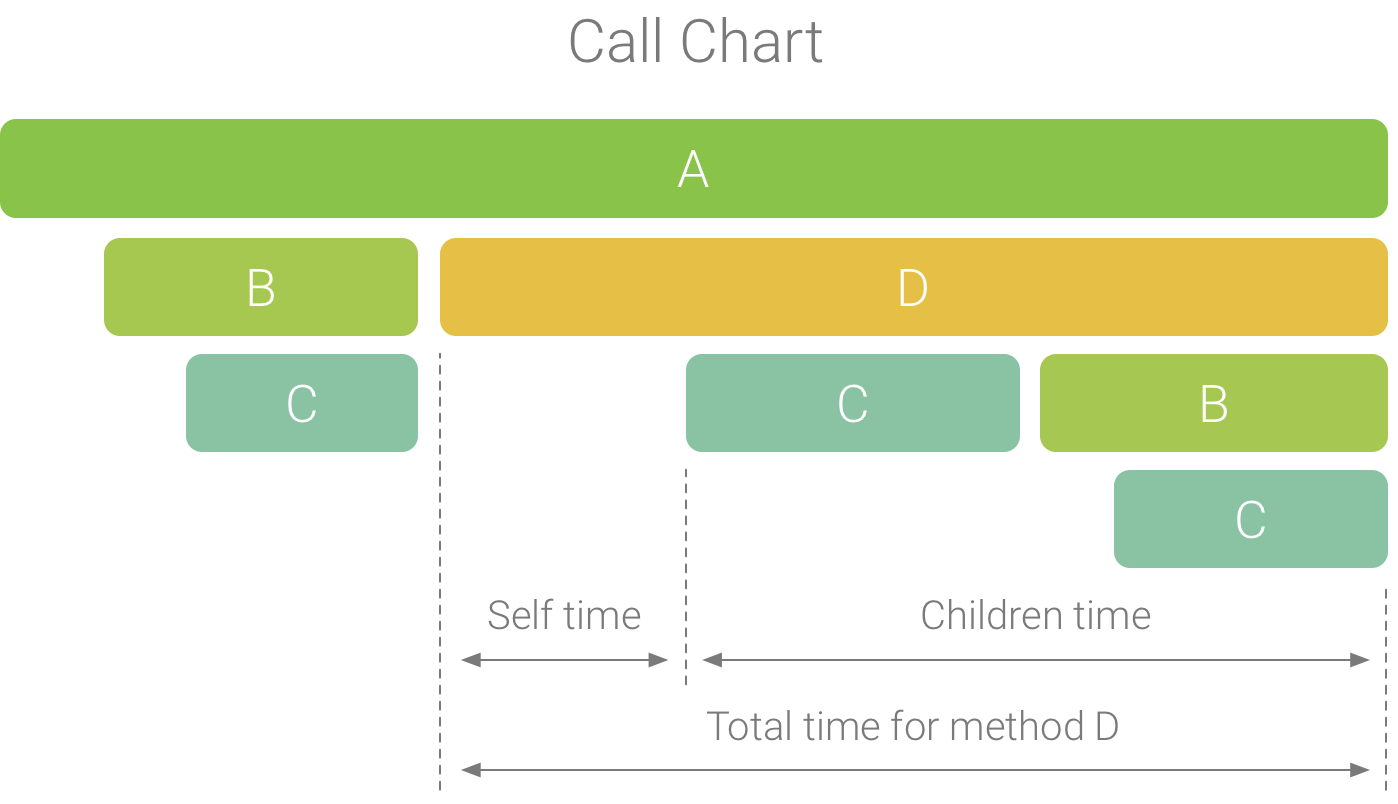
Figure 1. An example call chart that illustrates self, children, and total time for method D.
Tip: To jump the source code of a method or function, right-click it and select Jump to Source. This works from any of the Analysis pane tabs.
Inspect traces using the Flame Chart tab
The Flame Chart tab provides an inverted call chart that aggregates identical call stacks. That is, identical methods or functions that share the same sequence of callers are collected and represented as one longer bar in a flame chart (rather than displaying them as multiple shorter bars, as shown in a call chart). This makes it easier to see which methods or functions consume the most time. However, this also means that the horizontal axis doesn't represent a timeline; instead, it indicates the relative amount of time each method or function takes to execute.
To help illustrate this concept, consider the call chart in Figure 2. Note that method D makes multiple calls to B (B1, B2, and B3), and some of those calls to B make a call to C (C1 and C3).
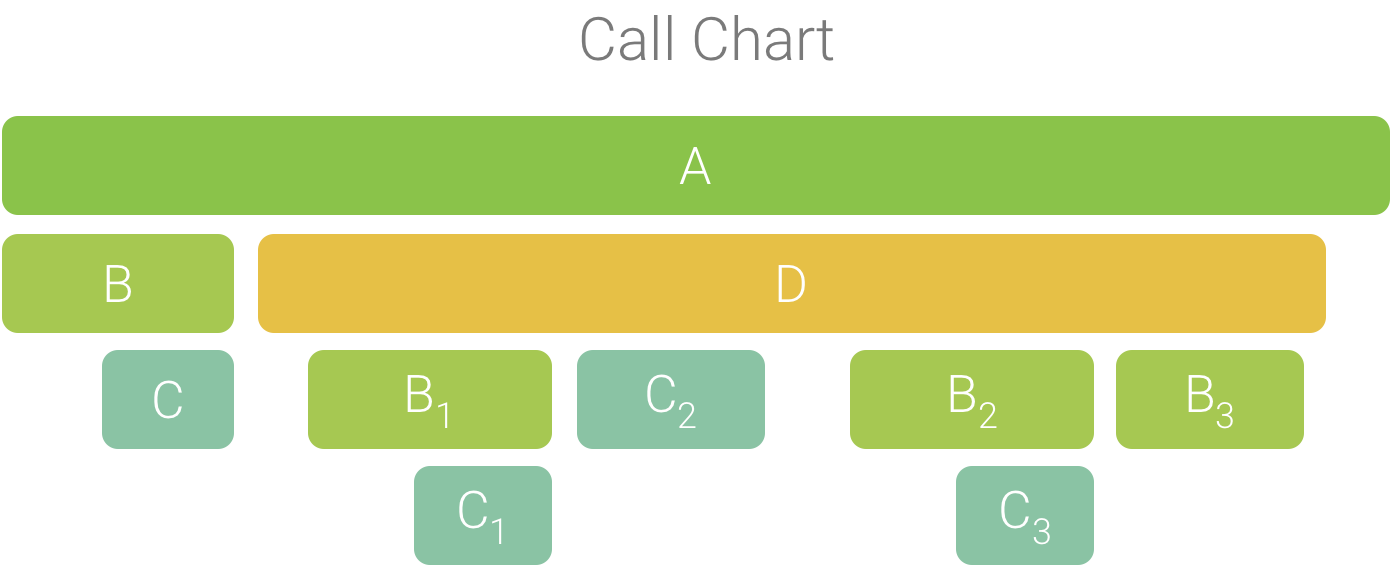
Figure 2. A call chart with multiple method calls that share a common sequence of callers.
Because B1, B2, and B3 share the same sequence of callers (A → D → B) they are aggregated, as shown in Figure 3. Similarly, C1 and C3 are aggregated because they share the same sequence of callers (A → D → B → C); note that C2 is not included because it has a different sequence of callers (A → D → C).
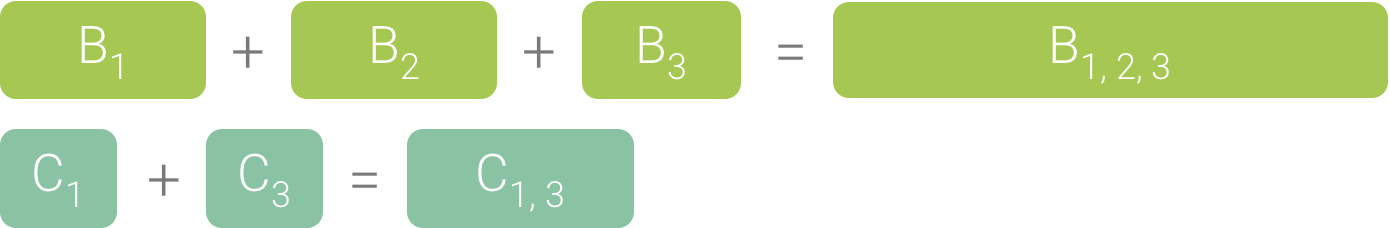
Figure 3. Aggregating identical methods that share the same call stack.
The aggregated calls are used to create the flame chart, as shown in Figure 4. Note that, for any given call in a flame chart, the callees that consume the most CPU time appear first.
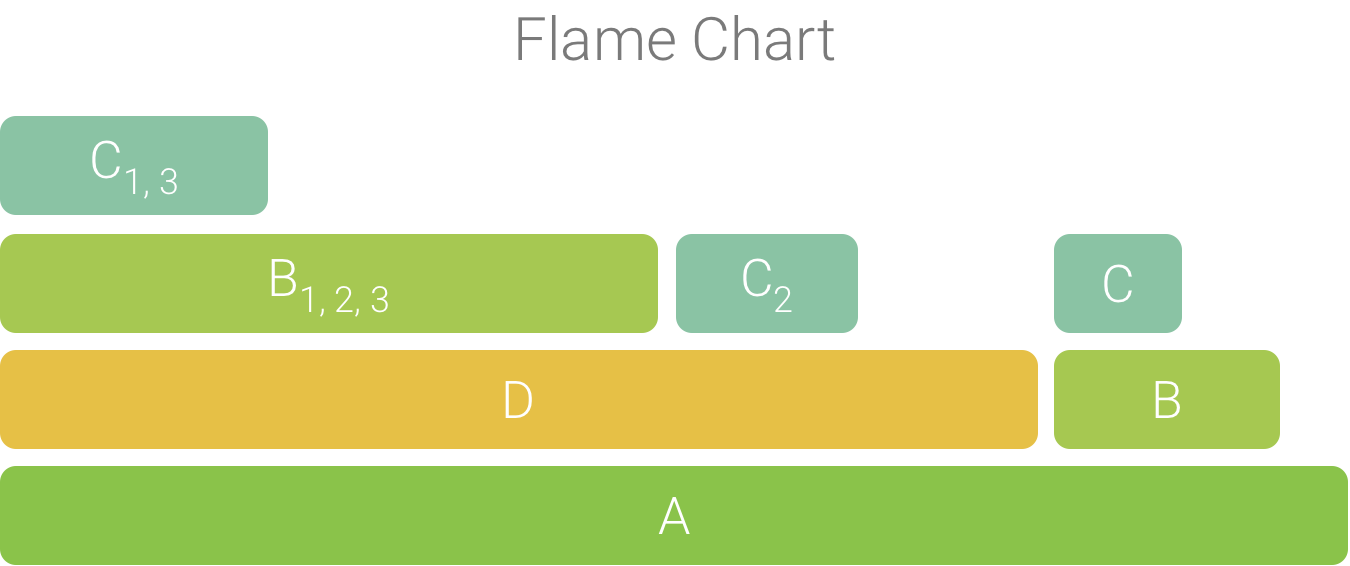
Figure 4. A flame chart representation of the call chart shown in figure 5.
Inspect traces using Top Down and Bottom Up
The Top Down tab displays a list of calls in which expanding a method or function node displays its callees. Figure 5 shows a top down graph for the call chart in Figure 1. Each arrow in the graph points from a caller to a callee.
As shown in Figure 5, expanding the node for method A in the Top Down tab displays its callees, methods B and D. After that, expanding the node for method D exposes its callees, methods B and C, and so on. Similar to the Flame chart tab, the top down tree aggregates trace information for identical methods that share the same call stack. That is, the Flame chart tab provides a graphical representation of the Top down tab.
The Top Down tab provides the following information to help describe CPU time spent on each call (times are also represented as a percentage of the thread’s total time over the selected range):
- Self: the time the method or function call spent executing its own code and not that of its callees, as illustrated in Figure 1 for method D.
- Children: the time the method or function call spent executing its callees and not its own code, as illustrated in Figure 1 for method D.
- Total: the sum of the method’s Self and Children time. This represents the total time the app spent executing a call, as illustrated in Figure 1 for method D.
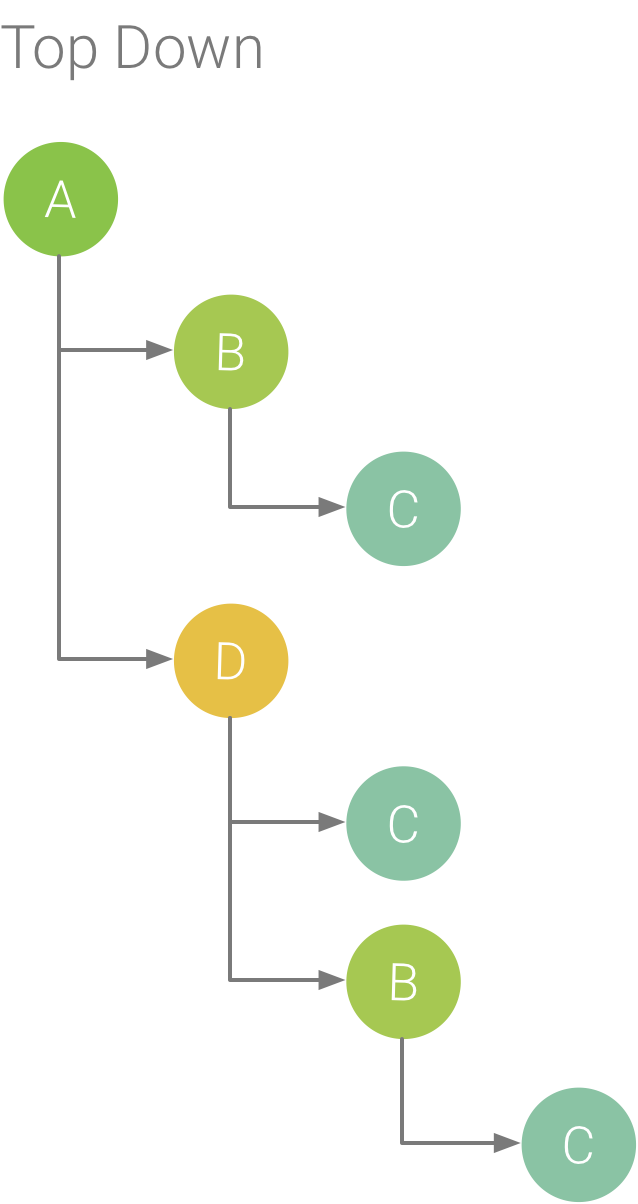
Figure 5. A Top Down tree.
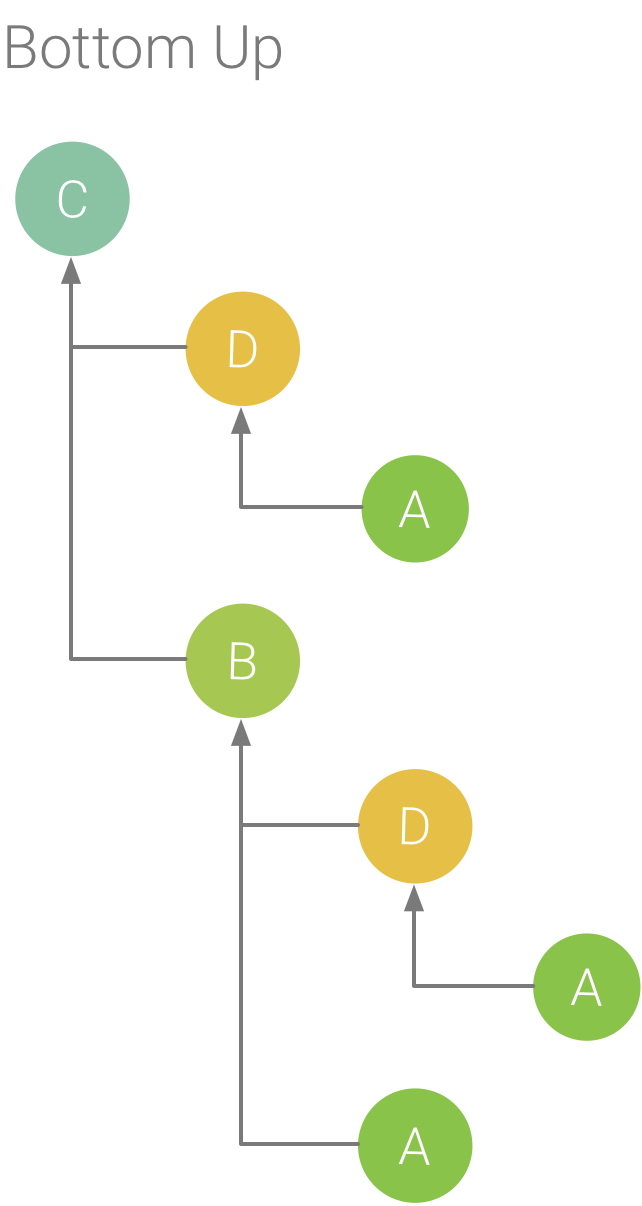
Figure 6. A Bottom Up tree for method C from Figure 5.
The Bottom Up tab displays a list of calls in which expanding a function or method’s node displays its callers. Using the example trace shown in Figure 5, figure 6 provides a bottom up tree for method C. Opening the node for method C in the bottom up tree displays each of its unique callers, methods B and D. Note that, although B calls C twice, B appears only once when expanding the node for method C in the bottom up tree. After that, expanding the node for B displays its caller, methods A and D.
The Bottom Up tab is useful for sorting methods or functions by those that consume the most (or least) CPU time. You can inspect each node to determine which callers spend the most CPU time invoking those methods or functions. Compared to the top down tree, timing info for each method or function in a bottom up tree is in reference to the method at the top of each tree (top node). CPU time is also represented as a percentage of the thread’s total time during that recording. The following table helps explain how to interpret timing information for the top node and its callers (sub-nodes).
| Self | Children | Total | |
|---|---|---|---|
| Method or function at the top of the bottom up tree (top node) | Represents the total time the method or function spent executing its own code and not that of its callees. Compared to the top down tree, this timing information represents a sum of all calls to this method or function over the duration of the recording. | Represents the total time the method or function spent executing its callees and not its own code. Compared to the top down tree, this timing information represents the sum of all calls to this method or function's callees over the duration of the recording. | The sum of the self time and children time. |
| Callers (sub-nodes) | Represents the total self time of the callee when being called by the caller. Using the bottom up tree in Figure 6 as an example, the self time for method B would equal the sum of the self times for each execution of method C when called by B. | Represents the total children time of the callee when being invoked by the caller. Using the bottom up tree in Figure 6 as an example, the children time for method B would equal the sum of the children times for each execution of method C when called by B. | The sum of the self time and children time. |
Note: For a given recording, Android Studio stops collecting new data when the profiler reaches the file size limit (however, this does not stop the recording). This typically happens much more quickly when performing instrumented traces because this type of tracing collects more data in a shorter time, compared to a sampled trace. If you extend the inspection time into a period of the recording that occurred after reaching the limit, timing data in the trace pane does not change (because no new data is available). Additionally, the trace pane displays NaN for timing information when you select only the portion of a recording that has no data available.
Inspect traces using the Events table
The Events table lists all calls in the currently selected thread. You can sort them by clicking on the column headers. By selecting a row in the table, you can navigate the timeline to the start and end time of the selected call. This allows you to accurately locate events on the timeline.
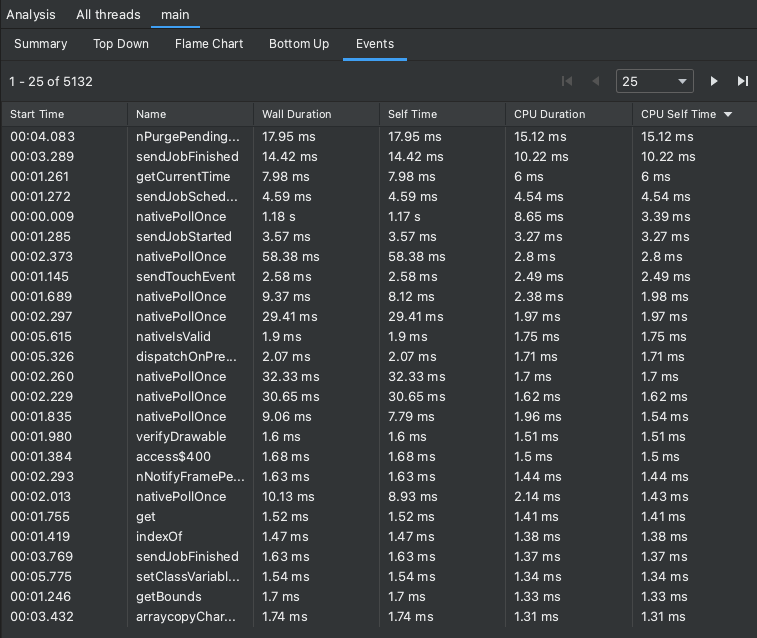
Figure 7. Viewing the Events tab in the Analysis pane.
Inspect callstack frames
Callstacks are useful to understand which part of the code has been executed,
and why it was invoked. If a Callstack Sample Recording is collected for a
Java/Kotlin program, the callstack usually includes not only Java/Kotlin code,
but also frames from the JNI native code, Java virtual machine (e.g.,
android::AndroidRuntime::start), and the system kernel
([kernel.kallsyms]+offset). This is because a Java/Kotlin program typically
executes through a Java virtual machine. Native code is required to run the
program itself and for the program to talk with the system and hardware. The
profiler presents these frames for precision; however, depending on your
investigation, you may or may not find these extra call frames useful. The
profiler provides a way to collapse frames that you are not interested in so
that you can hide information that is irrelevant for your investigation.
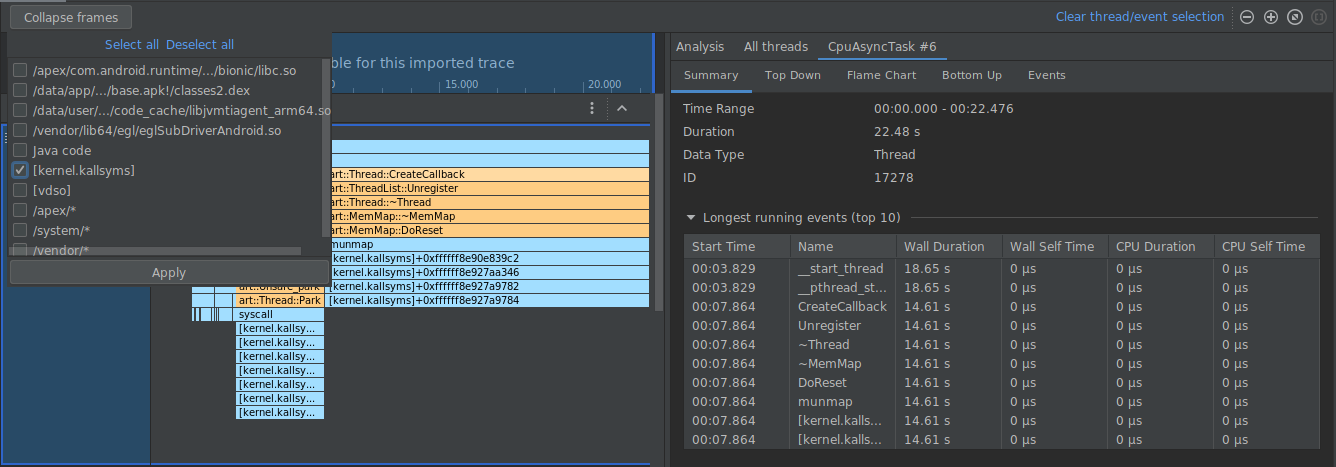
In the example below, the trace below has many frames labeled
[kernel.kallsyms]+offset, which are not currently useful for development.
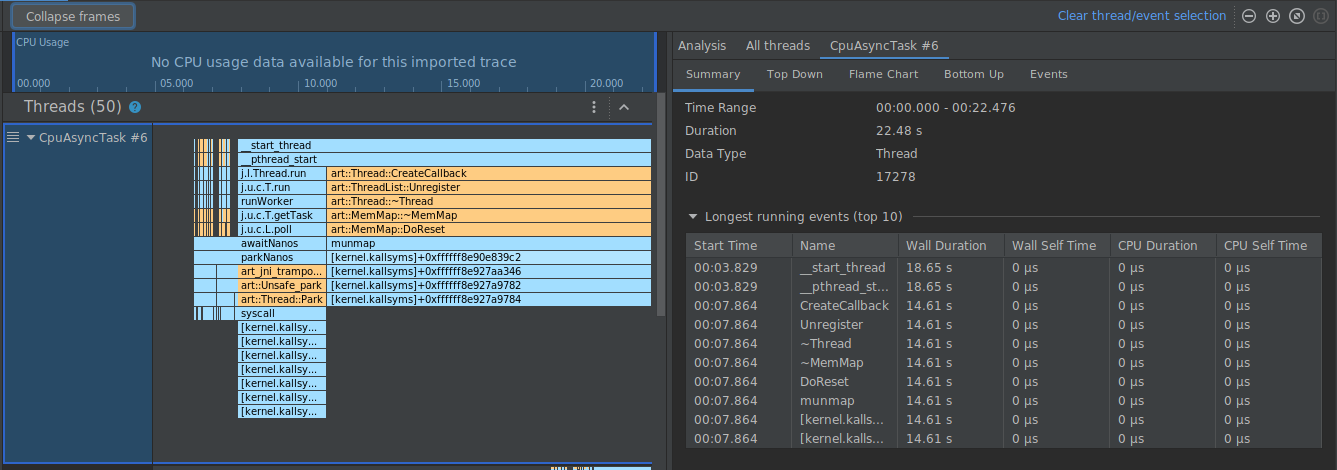
To collapse these frames into one, you would select the Collapse frames
button from the toolbar, choose the paths to collapse, and select the Apply
button to apply your changes. In this example, the path is [kernel.kallsyms].
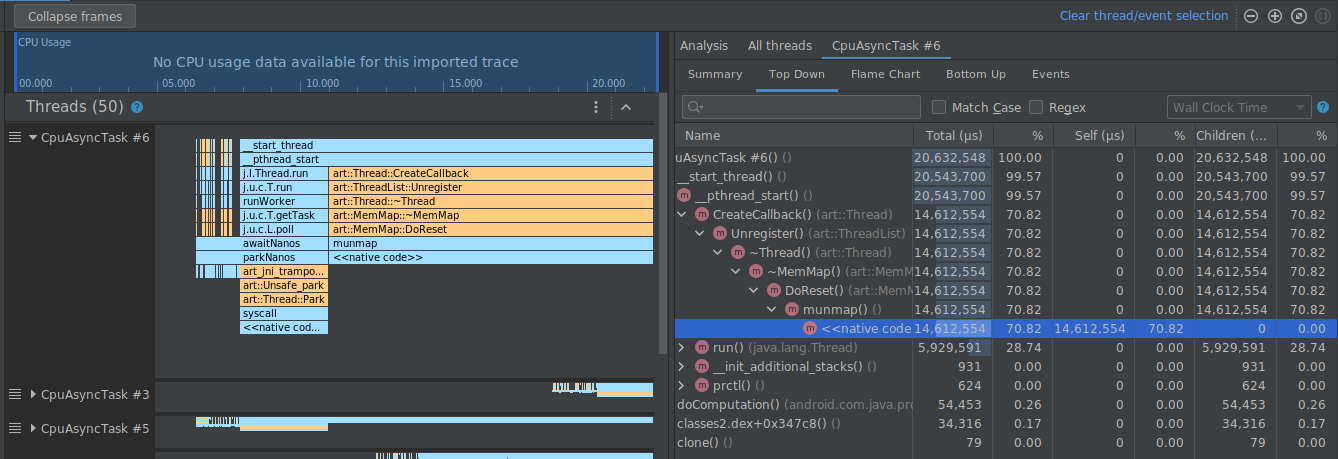
Doing so collapses the frames corresponding to the selected path on both the left and right panels, as shown below.
Inspect system traces
When inspecting a system trace, you can examine Trace Events in the Threads timeline to view the details of the events occurring on each thread. Hover your mouse pointer over an event to see the name of the event and the time spent in each state. Click an event to see more information in the Analysis pane.
Inspect system traces: CPU cores
In addition to CPU scheduling data, system traces also include CPU frequency by core. This shows the amount of activity on each core and may give you an idea of which ones are the "big" or "little" cores in modern mobile processors.
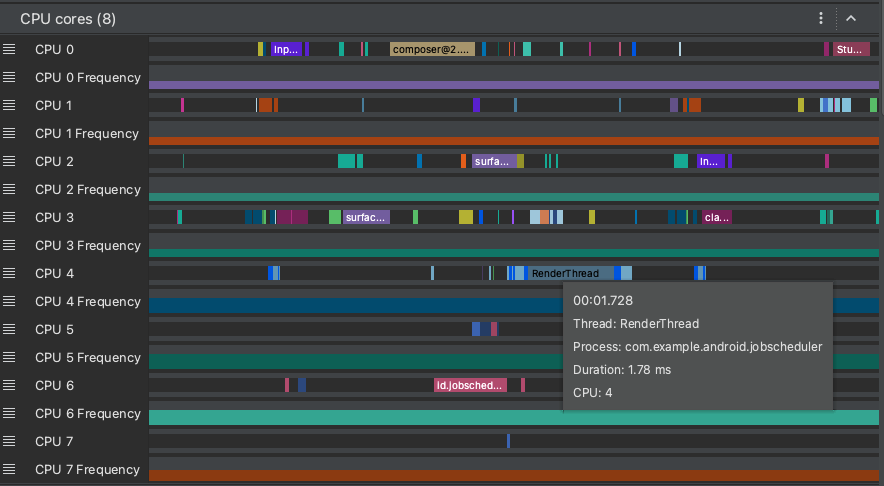
Figure 8. Viewing CPU activity and trace events for the render thread.
The CPU Cores pane (as shown in Figure 8) shows thread activity scheduled on every core. Hover your mouse pointer over a thread activity to see which thread this core is running on at that particular time.
For additional information on inspecting system trace information, see the
Investigate UI performance problems
section of the systrace documentation.
Inspect system traces: Frame rendering timeline
You can inspect how long it takes your app to render each frame on the main
thread and RenderThread to investigate bottlenecks that cause UI jank and low
framerates. To learn about how to use system traces to investigate and help
reduce UI jank, see UI jank detection.
Inspect system traces: Process Memory (RSS)
For apps deployed to devices running Android 9 or higher, the Process Memory (RSS) section shows the amount of physical memory currently in use by the app.

Figure 9. Viewing physical memory in the profiler.
Total
This is the total amount of physical memory currently in use by your process. On Unix-based systems, this is known as the "Resident Set Size", and is the combination of all the memory used by anonymous allocations, file mappings, and shared memory allocations.
For Windows developers, Resident Set Size is analogous to the Working Set Size.
Allocated
This counter tracks how much physical memory is currently used by the
process's normal memory allocations. These are allocations which are
anonymous (not backed by a specific file) and private (not shared). In most
applications, these are made up of heap allocations (with malloc or
new) and stack memory. When swapped out from physical memory, these
allocations are written to the system swap file.
File Mappings
This counter tracks the amount of physical memory the process is using for file mappings – that is, memory mapped from files into a region of memory by the memory manager.
Shared
This counter tracks how much physical memory is being used to share memory between this process and other processes in the system.