
The Profile GPU Rendering tool indicates the relative time that each stage of the rendering pipeline takes to render the previous frame. This knowledge can help you identify bottlenecks in the pipeline, so that you can know what to optimize to improve your app's rendering performance.
This page briefly explains what happens during each pipeline stage, and discusses issues that can cause bottlenecks there. Before reading this page, you should be familiar with the information presented in Profile GPU rendering. In addition, to understand how all of the stages fit together, it may be helpful to review how the rendering pipeline works.
Visual representation
The Profile GPU Rendering tool displays stages and their relative times in the form of a graph: a color-coded histogram. Figure 1 shows an example of such a display.
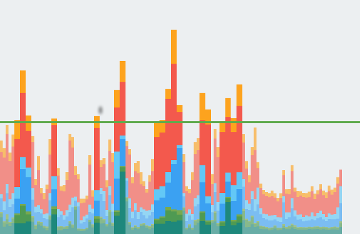
Figure 1. Profile GPU Rendering Graph
Each segment of each vertical bar displayed in the Profile GPU Rendering graph represents a stage of the pipeline and is highlighted using a specific color in the bar graph. Figure 2 shows a key to the meaning of each displayed color.

Figure 2. Profile GPU Rendering Graph Legend
Once you understand what each color signfiies, you can target specific aspects of your app to try to optimize its rendering performance.
Stages and their meanings
This section explains what happens during each stage corresponding to a color in Figure 2, as well as bottleneck causes to look out for.
Input handling
The input handling stage of the pipeline measures how long the app spent handling input events. This metric indicates how long the app spent executing code called as a result of input event callbacks.
When this segment is large
High values in this area are typically a result of too much work, or too-complex work, occurring inside the input-handler event callbacks. Since these callbacks always occur on the main thread, solutions to this problem focus on optimizing the work directly, or offloading the work to a different thread.
It’s also worth noting that
RecyclerView
scrolling can appear in this phase.
RecyclerView
scrolls immediately when it consumes the touch event. As a result,
it can inflate or populate new item views. For this reason, it’s important to
make this operation as fast as possible. Profiling tools like Traceview or
Systrace can help you investigate further.
Animation
The Animations phase shows you just how long it took to evaluate all the
animators that were running in that frame. The most common animators are
ObjectAnimator,
ViewPropertyAnimator, and
Transitions.
When this segment is large
High values in this area are typically a result of work that’s executing due
to some property change of the animation. For example, a fling animation,
which scrolls your ListView or
RecyclerView,
causes large amounts of view inflation and population.
Measurement/layout
In order for Android to draw your view items on the screen, it executes two specific operations across layouts and views in your view hierarchy.
First, the system measures the view items. Every view and layout has specific data that describes the size of the object on the screen. Some views can have a specific size; others have a size that adapts to the size of the parent layout container
Second, the system lays out the view items. Once the system calculates the sizes of children views, the system can proceed with layout, sizing and positioning the views on the screen.
The system performs measurement and layout not only for the views to be drawn, but also for the parent hierarchies of those views, all the way up to the root view.
When this segment is large
If your app spends a lot of time per frame in this area, it is usually either because of the sheer volume of views that need to be laid out, or problems such as double taxation at the wrong spot in your hierarchy. In either of these cases, addressing performance involves improving the performance of your view hierarchies.
Code that you’ve added to
onLayout(boolean, int, int, int, int) or
onMeasure(int, int)
can also cause performance
issues. Traceview and
Systrace can help you examine
the callstacks to identify problems your code may have.
Draw
The draw stage translates a view’s rendering operations, such as drawing a background or drawing text, into a sequence of native drawing commands. The system captures these commands into a display list.
The Draw bar records how much time it takes to complete capturing the commands
into the display list, for all the views that needed to be updated on the screen
this frame. The measured time applies to any code that you have added to the UI
objects in your app. Examples of such code may be the
onDraw(),
dispatchDraw(),
and the various draw ()methods belonging to the subclasses of the
Drawable class.
When this segment is large
In simplified terms, you can understand this metric as showing how long it took
to run all of the calls to
onDraw()
for each invalidated view. This
measurement includes any time spent dispatching draw commands to children and
drawables that may be present. For this reason, when you see this bar spike, the
cause could be that a bunch of views suddenly became invalidated. Invalidation
makes it necessary to regenerate views' display lists. Alternatively, a
lengthy time may be the result of a few custom views that have some extremely
complex logic in their
onDraw() methods.
Sync/upload
The Sync & Upload metric represents the time it takes to transfer bitmap objects from CPU memory to GPU memory during the current frame.
As different processors, the CPU and the GPU have different RAM areas dedicated to processing. When you draw a bitmap on Android, the system transfers the bitmap to GPU memory before the GPU can render it to the screen. Then, the GPU caches the bitmap so that the system doesn’t need to transfer the data again unless the texture gets evicted from the GPU texture cache.
Note: On Lollipop devices, this stage is purple.
When this segment is large
All resources for a frame need to reside in GPU memory before they can be used to draw a frame. This means that a high value for this metric could mean either a large number of small resource loads or a small number of very large resources. A common case is when an app displays a single bitmap that’s close to the size of the screen. Another case is when an app displays a large number of thumbnails.
To shrink this bar, you can employ techniques such as:
- Ensuring your bitmap resolutions are not much larger than the size at which they will be displayed. For example, your app should avoid displaying a 1024x1024 image as a 48x48 image.
-
Taking advantage of
prepareToDraw()to asynchronously pre-upload a bitmap before the next sync phase.
Issue commands
The Issue Commands segment represents the time it takes to issue all of the commands necessary for drawing display lists to the screen.
For the system to draw display lists to the screen, it sends the necessary commands to the GPU. Typically, it performs this action through the OpenGL ES API.
This process takes some time, as the system performs final transformation and clipping for each command before sending the command to the GPU. Additional overhead then arises on the GPU side, which computes the final commands. These commands include final transformations, and additional clipping.
When this segment is large
The time spent in this stage is a direct measure of the complexity and quantity of display lists that the system renders in a given frame. For example, having many draw operations, especially in cases where there's a small inherent cost to each draw primitive, could inflate this time. For example:
Kotlin
for (i in 0 until 1000) { canvas.drawPoint() }
Java
for (int i = 0; i < 1000; i++) { canvas.drawPoint() }
is a lot more expensive to issue than:
Kotlin
canvas.drawPoints(thousandPointArray)
Java
canvas.drawPoints(thousandPointArray);
There isn’t always a 1:1 correlation between issuing commands and actually drawing display lists. Unlike Issue Commands, which captures the time it takes to send drawing commands to the GPU, the Draw metric represents the time that it took to capture the issued commands into the display list.
This difference arises because the display lists are cached by the system wherever possible. As a result, there are situations where a scroll, transform, or animation requires the system to re-send a display list, but not have to actually rebuild it—recapture the drawing commands—from scratch. As a result, you can see a high “Issue commands” bar without seeing a high Draw commands bar.
Process/swap buffers
Once Android finishes submitting all its display list to the GPU, the system issues one final command to tell the graphics driver that it's done with the current frame. At this point, the driver can finally present the updated image to the screen.
When this segment is large
It’s important to understand that the GPU executes work in parallel with the CPU. The Android system issues draw commands to the GPU, and then moves on to the next task. The GPU reads those draw commands from a queue and processes them.
In situations where the CPU issues commands faster than the GPU consumes them, the communications queue between the processors can become full. When this occurs, the CPU blocks, and waits until there is space in the queue to place the next command. This full-queue state arises often during the Swap Buffers stage, because at that point, a whole frame’s worth of commands have been submitted.
The key to mitigating this problem is to reduce the complexity of work occurring on the GPU, in similar fashion to what you would do for the “Issue Commands” phase.
Miscellaneous
In addition to the time it takes the rendering system to perform its work, there’s an additional set of work that occurs on the main thread and has nothing to do with rendering. Time that this work consumes is reported as misc time. Misc time generally represents work that might be occurring on the UI thread between two consecutive frames of rendering.
When this segment is large
If this value is high, it is likely that your app has callbacks, intents, or other work that should be happening on another thread. Tools such as Method tracing or Systrace can provide visibility into the tasks that are running on the main thread. This information can help you target performance improvements.