
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन ऐसा ऐप्लिकेशन होता है जो इंटरनेट के बिना भी, अपने सभी या मुख्य फ़ंक्शन के ज़रूरी सबसेट को पूरा कर सकता है. इसका मतलब है कि यह अपने कारोबार के कुछ या सभी लॉजिक को ऑफ़लाइन तरीके से लागू कर सकता है.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन बनाने के लिए, डेटा लेयर से शुरुआत करें. इससे ऐप्लिकेशन के डेटा और कारोबार के लॉजिक को ऐक्सेस किया जा सकता है. समय-समय पर, ऐप्लिकेशन को इस डेटा को डिवाइस के बाहर के सोर्स से रीफ़्रेश करना पड़ सकता है. ऐसा करने के लिए, इसे अप-टू-डेट रहने के लिए नेटवर्क रिसॉर्स का इस्तेमाल करना पड़ सकता है.
नेटवर्क की उपलब्धता की हमेशा गारंटी नहीं होती. डिवाइसों में अक्सर नेटवर्क कनेक्शन ठीक से काम नहीं करता या धीमा होता है. उपयोगकर्ताओं को ये समस्याएं दिख सकती हैं:
- इंटरनेट की बैंडविथ कम होना
- कनेक्शन में कुछ समय के लिए रुकावटें आना. जैसे, लिफ़्ट या सुरंग में होने पर
- कभी-कभी डेटा ऐक्सेस करने वाले डिवाइस—उदाहरण के लिए, सिर्फ़ वाई-फ़ाई से कनेक्ट होने वाले टैबलेट
वजह चाहे जो भी हो, इन स्थितियों में अक्सर ऐप्लिकेशन ठीक से काम कर सकता है. यह पक्का करने के लिए कि आपका ऐप्लिकेशन ऑफ़लाइन होने पर सही तरीके से काम करे, उसमें ये सुविधाएं होनी चाहिए:
- नेटवर्क कनेक्शन न होने पर भी इस्तेमाल किया जा सकता है
- उपयोगकर्ताओं को स्थानीय डेटा तुरंत दिखाएं. इसके लिए, पहले नेटवर्क कॉल के पूरा होने या फ़ेल होने का इंतज़ार न करें
- बैटरी और डेटा के स्टेटस को ध्यान में रखकर डेटा फ़ेच करना—उदाहरण के लिए, सिर्फ़ सबसे अच्छी स्थितियों में डेटा फ़ेच करने का अनुरोध करना. जैसे, चार्जिंग के दौरान या वाई-फ़ाई से कनेक्ट होने पर
इन शर्तों को पूरा करने वाले ऐप्लिकेशन को अक्सर ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन कहा जाता है.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन डिज़ाइन करना
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन डिज़ाइन करते समय, डेटा लेयर से शुरू करें. साथ ही, ऐप्लिकेशन के डेटा पर की जा सकने वाली दो मुख्य कार्रवाइयां:
- पढ़ता है: ऐप्लिकेशन के अन्य हिस्सों में इस्तेमाल करने के लिए डेटा को वापस पाना. जैसे, उपयोगकर्ता को जानकारी दिखाना. Compose में, आम तौर पर state को देखकर ऐसा किया जाता है. जब आपका यूज़र इंटरफ़ेस (यूआई), लोकल डेटा सोर्स को स्टेट के तौर पर देखता है, तो स्क्रीन पर अपने-आप लोकल डेटा का नया वर्शन दिखता है.
- लिखता है: यह कुकी, उपयोगकर्ता के इनपुट को सेव करती है, ताकि बाद में उसे वापस पाया जा सके. Compose में, आम तौर पर यूज़र इंटरफ़ेस (यूआई) से ViewModel को भेजे गए इवेंट और कार्रवाइयों का इस्तेमाल करके ऐसा किया जाता है.
डेटा लेयर में मौजूद रिपॉज़िटरी, ऐप्लिकेशन का डेटा उपलब्ध कराने के लिए डेटा सोर्स को एक साथ लाने का काम करती हैं. ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में, कम से कम एक ऐसा डेटा सोर्स होना चाहिए जिसे सबसे ज़रूरी टास्क पूरे करने के लिए, नेटवर्क ऐक्सेस की ज़रूरत न हो. इन ज़रूरी कामों में से एक है डेटा पढ़ना.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में मॉडल डेटा
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में, हर उस रिपॉज़िटरी के लिए कम से कम दो डेटा सोर्स होते हैं जो नेटवर्क संसाधनों का इस्तेमाल करती है:
- लोकल डेटा सोर्स
- नेटवर्क का डेटा सोर्स
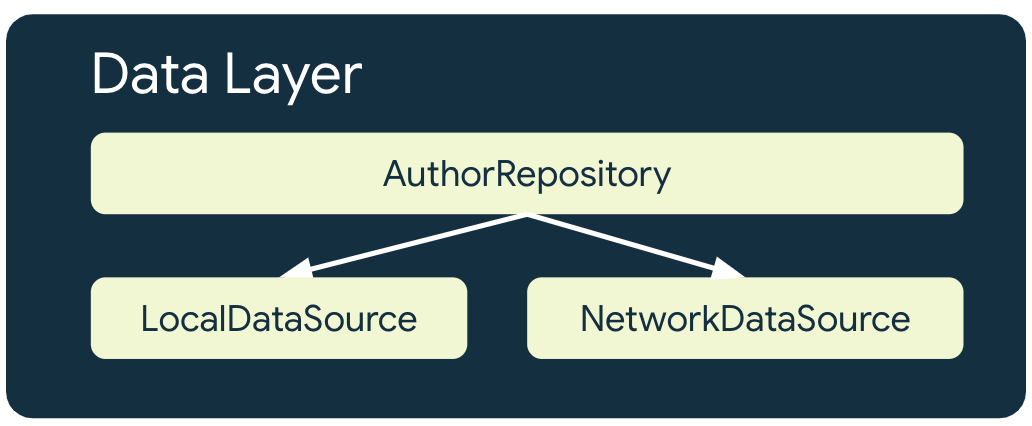
लोकल डेटा सोर्स
लोकल डेटा सोर्स, ऐप्लिकेशन के लिए कैननिकल सोर्स ऑफ़ ट्रुथ होता है. यह ऐप्लिकेशन की हायर लेयर में मौजूद डेटा का एक्सक्लूसिव सोर्स होना चाहिए. इससे यह पक्का किया जाता है कि कनेक्शन की स्थितियों के बीच डेटा में कोई अंतर न हो. लोकल डेटा सोर्स को अक्सर ऐसे स्टोरेज से बैकअप लिया जाता है जिसे डिस्क में सेव किया जाता है. डेटा को डिस्क में सेव करने के कुछ सामान्य तरीके यहां दिए गए हैं:
- स्ट्रक्चर्ड डेटा सोर्स, जैसे कि Room जैसे रिलेशनल डेटाबेस
- अनस्ट्रक्चर्ड डेटा सोर्स—उदाहरण के लिए, DataStore के साथ प्रोटोकॉल बफ़र
- सामान्य फ़ाइलें
नेटवर्क का डेटा सोर्स
नेटवर्क डेटा सोर्स, ऐप्लिकेशन की मौजूदा स्थिति होती है. ज़्यादा से ज़्यादा, लोकल डेटा सोर्स को नेटवर्क डेटा सोर्स के साथ सिंक किया जाता है. ऐसा भी हो सकता है कि लोकल डेटा सोर्स, नेटवर्क डेटा सोर्स से पीछे हो. ऐसे में, जब डिवाइस फिर से इंटरनेट से कनेक्ट हो जाए, तब ऐप्लिकेशन को अपडेट करना ज़रूरी होता है. इसके उलट, नेटवर्क डेटा सोर्स, लोकल डेटा सोर्स से पीछे रह सकता है. ऐसा तब तक होता है, जब तक कनेक्टिविटी वापस आने पर ऐप्लिकेशन इसे अपडेट नहीं कर पाता. ऐप्लिकेशन की डोमेन और यूज़र इंटरफ़ेस (यूआई) लेयर को नेटवर्क लेयर के साथ सीधे तौर पर कम्यूनिकेट नहीं करना चाहिए. होस्टिंग repository की यह ज़िम्मेदारी है कि वह इससे कम्यूनिकेट करे और इसका इस्तेमाल करके, स्थानीय डेटा सोर्स को अपडेट करे.
संसाधन उपलब्ध कराना
लोकल और नेटवर्क डेटा सोर्स, इस मामले में बुनियादी तौर पर अलग-अलग हो सकते हैं कि आपका ऐप्लिकेशन उन्हें कैसे पढ़ और लिख सकता है. लोकल डेटा सोर्स से क्वेरी करने की प्रोसेस तेज़ और आसान हो सकती है. जैसे, एसक्यूएल क्वेरी का इस्तेमाल करते समय. इसके उलट, नेटवर्क डेटा सोर्स धीमे हो सकते हैं और उन पर पाबंदियां हो सकती हैं. जैसे, आईडी के हिसाब से RESTful रिसॉर्स को धीरे-धीरे ऐक्सेस करते समय. इसलिए, हर डेटा सोर्स को अक्सर अपने डेटा को अलग-अलग तरीके से दिखाने की ज़रूरत होती है. इसलिए, लोकल डेटा सोर्स और नेटवर्क डेटा सोर्स के अपने मॉडल हो सकते हैं.
नीचे दिए गए डायरेक्ट्री स्ट्रक्चर से, इस कॉन्सेप्ट को समझने में मदद मिलती है. AuthorEntity, ऐप्लिकेशन के लोकल डेटाबेस से पढ़े गए लेखक को दिखाता है. वहीं, NetworkAuthor, नेटवर्क पर क्रम से लगाए गए लेखक को दिखाता है:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity और NetworkAuthor के बारे में यहां बताया गया है:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
AuthorEntity और NetworkAuthor, दोनों को डेटा लेयर के अंदर रखना सबसे सही तरीका है. साथ ही, बाहरी लेयर के इस्तेमाल के लिए तीसरा टाइप उपलब्ध कराना चाहिए. इससे बाहरी लेयर को लोकल और नेटवर्क डेटा सोर्स में होने वाले छोटे-मोटे बदलावों से सुरक्षित रखा जाता है. इन बदलावों से ऐप्लिकेशन के व्यवहार में कोई बुनियादी बदलाव नहीं होता है. इसे इस स्निपेट में दिखाया गया है:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
इसके बाद, नेटवर्क मॉडल इसे लोकल मॉडल में बदलने के लिए एक्सटेंशन मेथड तय कर सकता है. इसी तरह, लोकल मॉडल में इसे बाहरी मॉडल में बदलने के लिए एक एक्सटेंशन मेथड होता है. इसे यहां दिए गए स्निपेट में दिखाया गया है:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
पढ़ता है
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में, ऐप्लिकेशन के डेटा को पढ़ने की सुविधा बुनियादी तौर पर उपलब्ध होती है. इसलिए, आपको यह पक्का करना होगा कि आपका ऐप्लिकेशन डेटा को पढ़ सके. साथ ही, नया डेटा उपलब्ध होते ही ऐप्लिकेशन उसे दिखा सके. ऐसा करने वाला ऐप्लिकेशन, रीऐक्टिव ऐप्लिकेशन होता है. ऐसा इसलिए, क्योंकि यह ऑब्ज़र्वेबल टाइप के साथ रीड एपीआई दिखाता है.
यहां दिए गए स्निपेट में, OfflineFirstTopicRepository अपने सभी रीड एपीआई के लिए Flows दिखाता है. इससे, नेटवर्क डेटा सोर्स से अपडेट मिलने पर, यह अपने उपयोगकर्ताओं को अपडेट कर पाता है. दूसरे शब्दों में कहें, तो इससे OfflineFirstTopicRepository को तब बदलावों को पुश करने की अनुमति मिलती है, जब उसका लोकल डेटा सोर्स अमान्य हो जाता है. इसलिए, OfflineFirstTopicRepository के हर रीडर को डेटा में होने वाले बदलावों को मैनेज करने के लिए तैयार रहना चाहिए. ये बदलाव, ऐप्लिकेशन में नेटवर्क कनेक्टिविटी वापस आने पर ट्रिगर हो सकते हैं. इसके अलावा, OfflineFirstTopicRepository स्थानीय डेटा सोर्स से सीधे डेटा को पढ़ता है. यह सिर्फ़ अपने रीडर को डेटा में हुए बदलावों के बारे में सूचना दे सकता है. इसके लिए, इसे सबसे पहले अपने लोकल डेटा सोर्स को अपडेट करना होगा.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
Jetpack Compose ऐप्लिकेशन में, डेटा लेयर और यूज़र इंटरफ़ेस (यूआई) के बीच पुल बनाने के लिए, ViewModel का इस्तेमाल करें.
ViewModel में, stateIn ऑपरेटर का इस्तेमाल करके, Flow को StateFlow में बदलें. इसके बाद, कंपोज़ेबल collectAsStateWithLifecycle() का इस्तेमाल करके उन स्टेटस को इकट्ठा करते हैं. साथ ही, लाइफ़साइकल के बारे में जानकारी रखने वाले तरीके से सदस्यताएं अपने-आप मैनेज करते हैं.
collectAsStateWithLifecycle() के बारे में ज़्यादा जानने के लिए, स्टेट और Jetpack Compose लेख पढ़ें.
गड़बड़ी ठीक करने की रणनीतियां
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में गड़बड़ियों को ठीक करने के अलग-अलग तरीके होते हैं. ये तरीके, उन डेटा सोर्स पर निर्भर करते हैं जहां गड़बड़ियां हो सकती हैं. इन रणनीतियों के बारे में, यहां दिए गए सब-सेक्शन में बताया गया है.
लोकल डेटा सोर्स
लोकल डेटा सोर्स से डेटा पढ़ते समय गड़बड़ियों को कम करने की कोशिश करें. पढ़ने वालों को गड़बड़ियों से बचाने के लिए, उन Flow पर catch ऑपरेटर का इस्तेमाल करें जिनसे पढ़ने वाला व्यक्ति डेटा इकट्ठा कर रहा है.
ViewModel में catch ऑपरेटर का इस्तेमाल इस तरह किया जा सकता है:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
ज़्यादा भरोसेमंद तरीके के लिए, एलसीई (लोडिंग कॉन्टेंट में गड़बड़ी) समाधान का इस्तेमाल करें. एलसीई में, पढ़ने के दौरान गड़बड़ी होने पर, गड़बड़ी की स्थिति दिखाई जाती है. आम तौर पर, यूज़र इंटरफ़ेस (यूआई) की स्थितियों को Kotlin की सील की गई क्लास के तौर पर मॉडल करके, एलसीई हासिल किया जाता है.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
नेटवर्क डेटा सोर्स
अगर नेटवर्क डेटा सोर्स से डेटा पढ़ते समय गड़बड़ियां होती हैं, तो ऐप्लिकेशन को डेटा फ़ेच करने की कोशिश फिर से करने के लिए, अनुमान लगाने के तरीके का इस्तेमाल करना होगा. सामान्य तौर पर इस्तेमाल होने वाले अनुमानित तरीकों में ये शामिल हैं:
एक्स्पोनेंशियल बैकऑफ़
एक्सपोनेंशियल बैकऑफ़ में, ऐप्लिकेशन नेटवर्क डेटा सोर्स से डेटा को बार-बार पढ़ने की कोशिश करता रहता है. ऐसा तब तक होता है, जब तक वह डेटा को पढ़ नहीं लेता या अन्य शर्तों के मुताबिक उसे ऐसा करने से रोक नहीं दिया जाता. इस दौरान, ऐप्लिकेशन के डेटा पढ़ने की कोशिशों के बीच का समय बढ़ता जाता है.
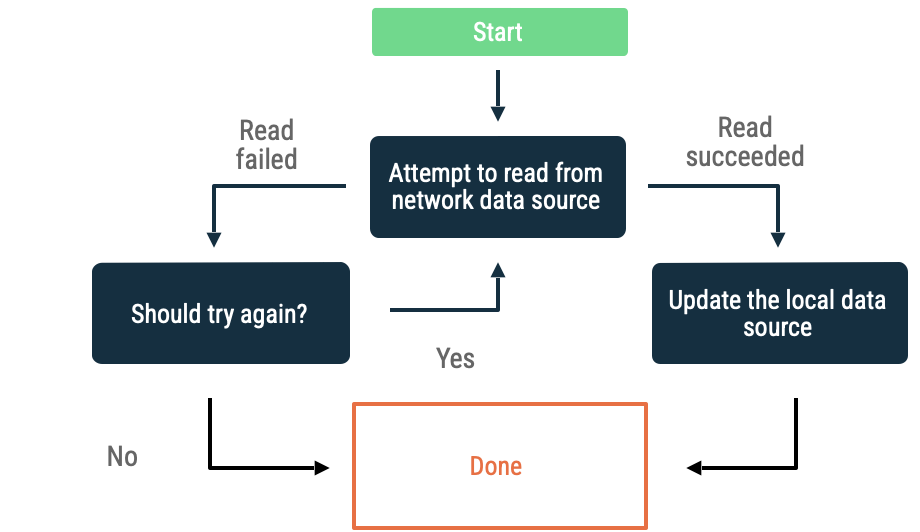
यह आकलन करने के लिए कि ऐप्लिकेशन बार-बार बैक ऑफ़ कर रहा है या नहीं, इन शर्तों को पूरा करना ज़रूरी है:
- नेटवर्क डेटा सोर्स से मिली गड़बड़ी का टाइप. उदाहरण के लिए, नेटवर्क कॉल को फिर से करने की कोशिश करें. इससे कनेक्टिविटी न होने की वजह से होने वाली गड़बड़ी ठीक हो जाती है. जब तक सही क्रेडेंशियल उपलब्ध न हों, तब तक उन एचटीटीपी अनुरोधों को फिर से न भेजें जिनकी अनुमति नहीं है.
- ज़्यादा से ज़्यादा कोशिशें की जा सकती हैं.
नेटवर्क कनेक्टिविटी को मॉनिटर करना
इस तरीके में, पढ़ने के अनुरोधों को तब तक कतार में रखा जाता है, जब तक ऐप्लिकेशन को यह पक्का नहीं हो जाता कि वह नेटवर्क डेटा सोर्स से कनेक्ट हो सकता है. कनेक्शन बन जाने के बाद, पढ़ने के अनुरोध को डीक्यू कर दिया जाता है. इसके बाद, डेटा पढ़ा जाता है और लोकल डेटा सोर्स को अपडेट किया जाता है. Android पर, इस क्यू को Room डेटाबेस की मदद से मैनेज किया जा सकता है. साथ ही, WorkManager का इस्तेमाल करके इसे लगातार प्रोसेस किया जा सकता है.
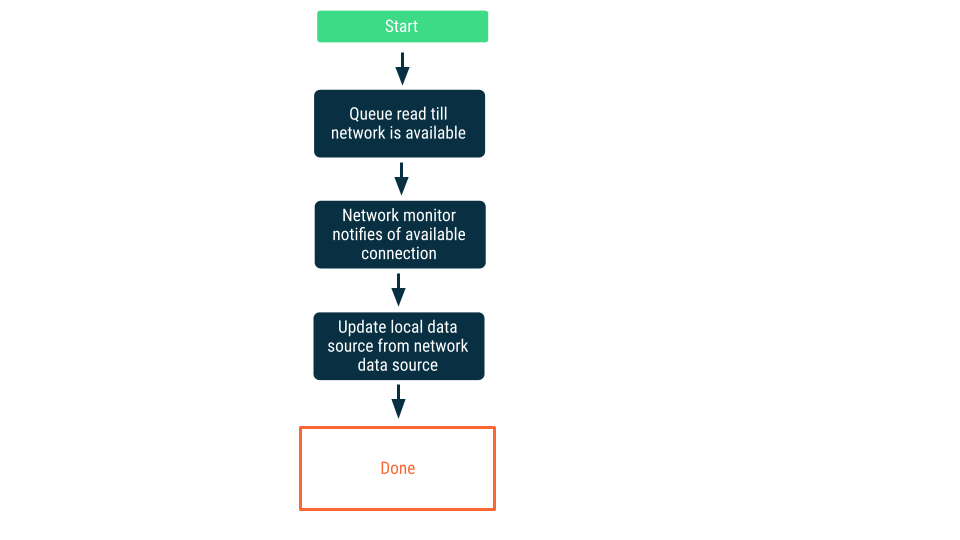
लिखता है
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में डेटा पढ़ने का सबसे सही तरीका, ऑब्ज़र्वेबल टाइप का इस्तेमाल करना है. हालांकि, राइट एपीआई के लिए एसिंक्रोनस एपीआई का इस्तेमाल किया जाता है. जैसे, सस्पेंड फ़ंक्शन. इससे यूज़र इंटरफ़ेस (यूआई) थ्रेड ब्लॉक नहीं होती. साथ ही, गड़बड़ी को ठीक करने में मदद मिलती है. ऐसा इसलिए, क्योंकि नेटवर्क की सीमा पार करने पर, ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में लिखने की प्रोसेस पूरी नहीं हो सकती.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
ऊपर दिए गए स्निपेट में, एसिंक्रोनस एपीआई के तौर पर Coroutines को चुना गया है, क्योंकि यह तरीका निलंबित हो जाता है.
रणनीतियां बनाना
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में डेटा लिखते समय, तीन रणनीतियों पर विचार किया जा सकता है. आपको कौनसा विकल्प चुनना है, यह इस बात पर निर्भर करता है कि किस तरह का डेटा लिखा जा रहा है और ऐप्लिकेशन की क्या ज़रूरतें हैं:
सिर्फ़ ऑनलाइन लिखने की अनुमति
नेटवर्क बाउंड्री में डेटा लिखने की कोशिश करना. अगर ऐसा हो जाता है, तो स्थानीय डेटा सोर्स को अपडेट करें. ऐसा न होने पर, एक अपवाद दिखाएं और कॉलर को उचित जवाब देने के लिए कहें.
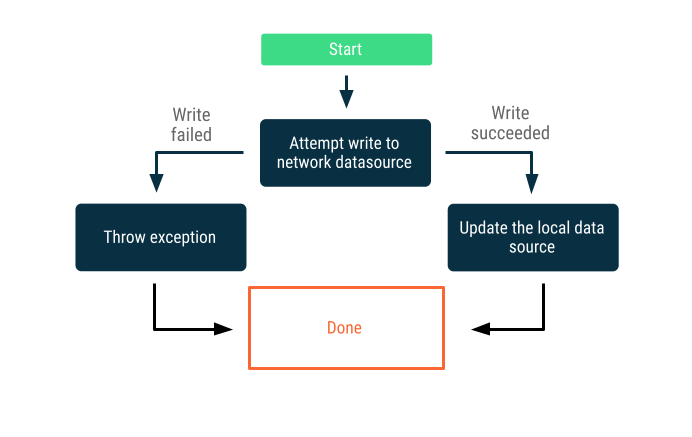
इस रणनीति का इस्तेमाल अक्सर उन लेन-देन के लिए किया जाता है जिन्हें ऑनलाइन और लगभग रीयल टाइम में पूरा करना होता है. उदाहरण के लिए, बैंक ट्रांसफ़र. लिखने की प्रोसेस पूरी न होने पर, उपयोगकर्ता को इसकी सूचना देना ज़रूरी होता है. इसके अलावा, उपयोगकर्ता को डेटा लिखने की कोशिश करने से रोकना भी ज़रूरी होता है. यहां कुछ ऐसी रणनीतियां दी गई हैं जिनका इस्तेमाल इन स्थितियों में किया जा सकता है:
- अगर किसी ऐप्लिकेशन को डेटा सेव करने के लिए इंटरनेट ऐक्सेस करने की ज़रूरत होती है, तो आपके पास उपयोगकर्ता को ऐसा यूज़र इंटरफ़ेस (यूआई) न दिखाने का विकल्प होता है जिससे वे डेटा सेव कर सकें. इसके अलावा, कम से कम इस सुविधा को बंद किया जा सकता है.
- उपयोगकर्ता को ऑफ़लाइन होने की सूचना देने के लिए,
AlertDialogका इस्तेमाल किया जा सकता है. उपयोगकर्ता इस सूचना को खारिज नहीं कर सकता. इसके अलावा,Snackbarका इस्तेमाल भी किया जा सकता है.
लिखे जाने के लिए कतार में रखे गए दस्तावेज़
जब आपको कोई ऑब्जेक्ट लिखना हो, तो उसे किसी कतार में डालें. जब ऐप्लिकेशन फिर से ऑनलाइन हो जाता है, तो एक्स्पोनेंशियल बैकऑफ़ का इस्तेमाल करके, क्यू को खाली कर दें. Android पर, ऑफ़लाइन क्यू को खाली करने का काम लगातार चलता रहता है. इसे अक्सर WorkManager को सौंपा जाता है.
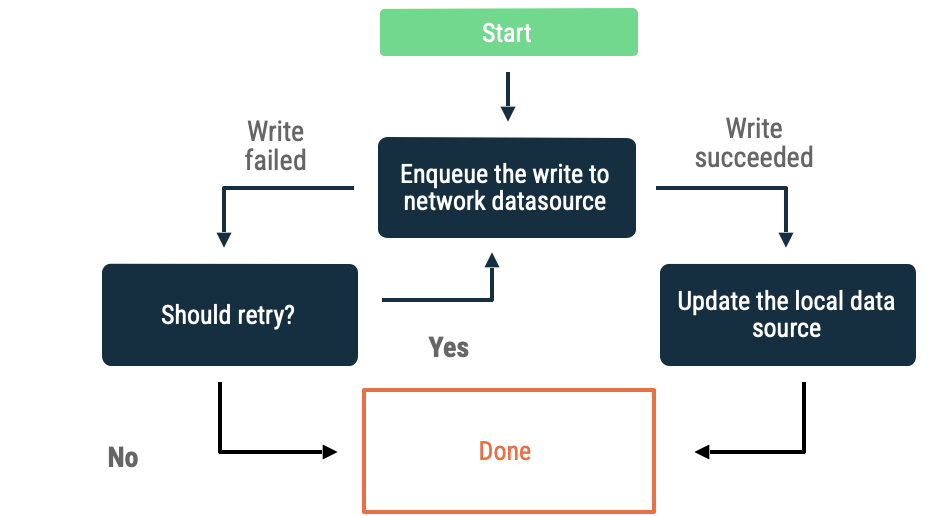
यह तरीका इन स्थितियों में सबसे सही है:
- यह ज़रूरी नहीं है कि डेटा को नेटवर्क पर लिखा जाए.
- लेन-देन को तय समय में पूरा करना ज़रूरी नहीं है.
- अगर कार्रवाई पूरी नहीं होती है, तो उपयोगकर्ता को इसकी सूचना देना ज़रूरी नहीं है.
इस तरीके का इस्तेमाल, इन मामलों में किया जा सकता है: आंकड़ों से जुड़े इवेंट और लॉगिंग.
लेज़ी राइट
सबसे पहले लोकल डेटा सोर्स में लिखें. इसके बाद, नेटवर्क को जल्द से जल्द सूचना देने के लिए, लिखने की प्रोसेस को लाइन में लगाएं. यह एक सामान्य समस्या नहीं है, क्योंकि जब ऐप्लिकेशन वापस ऑनलाइन होता है, तो नेटवर्क और लोकल डेटा सोर्स के बीच टकराव हो सकता है. विवाद के समाधान के बारे में अगले सेक्शन में ज़्यादा जानकारी दी गई है.
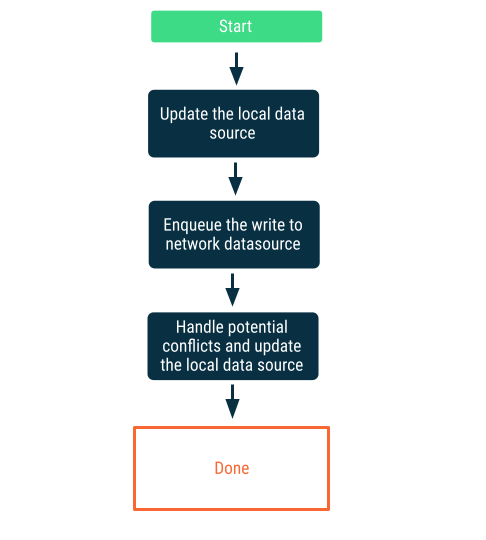
यह तरीका तब सही होता है, जब डेटा ऐप्लिकेशन के लिए ज़रूरी हो. उदाहरण के लिए, ऑफ़लाइन-फ़र्स्ट टू-डू लिस्ट वाले ऐप्लिकेशन में, यह ज़रूरी है कि उपयोगकर्ता ऑफ़लाइन में जो भी टास्क जोड़े उन्हें स्थानीय तौर पर सेव किया जाए, ताकि डेटा के नुकसान से बचा जा सके.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन के लिए, ऑफ़लाइन होने पर डेटा लिखने की सुविधा होना ज़रूरी नहीं है.सिंक करना और विवाद का समाधान करना
जब ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन की कनेक्टिविटी वापस आ जाती है, तो उसे अपने लोकल डेटा सोर्स में मौजूद डेटा को नेटवर्क डेटा सोर्स में मौजूद डेटा से मैच करना होता है. इस प्रोसेस को सिंक करना कहते हैं. कोई ऐप्लिकेशन, अपने नेटवर्क डेटा सोर्स के साथ इन दो मुख्य तरीकों से सिंक कर सकता है:
- पुल-आधारित सिंक्रनाइज़ेशन
- पुश-आधारित सिंक्रनाइज़ेशन
पुल-आधारित सिंक्रनाइज़ेशन
पुल-आधारित सिंक्रनाइज़ेशन में, ऐप्लिकेशन नेटवर्क से संपर्क करके, मांग पर ऐप्लिकेशन का नया डेटा पढ़ता है. इस तरीके के लिए, सामान्य तौर पर इस्तेमाल होने वाला अनुमानित तरीका नेविगेशन पर आधारित होता है. इसमें ऐप्लिकेशन, उपयोगकर्ता को डेटा दिखाने से ठीक पहले ही उसे फ़ेच करता है.
यह तरीका तब सबसे अच्छा काम करता है, जब ऐप्लिकेशन को कुछ समय के लिए नेटवर्क कनेक्टिविटी न मिलने की उम्मीद हो. ऐसा इसलिए होता है, क्योंकि डेटा रीफ़्रेश होने की सुविधा कभी-कभी ही मिलती है. साथ ही, लंबे समय तक कनेक्टिविटी न होने से, इस बात की संभावना बढ़ जाती है कि उपयोगकर्ता ऐसे ऐप्लिकेशन डेस्टिनेशन पर जाने की कोशिश करे जिसमें कैश मेमोरी में सेव किया गया डेटा पुराना हो या मौजूद न हो.
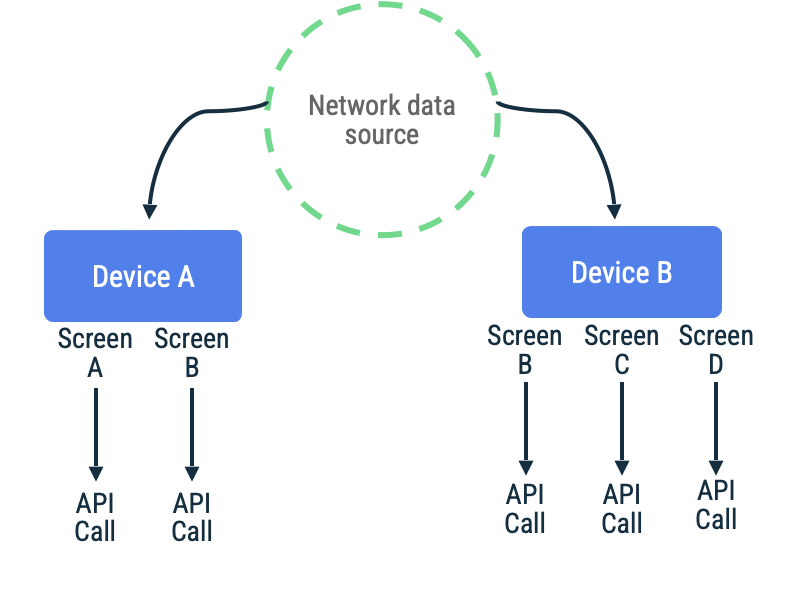
मान लें कि किसी ऐप्लिकेशन में, पेज टोकन का इस्तेमाल किया जाता है. इससे किसी स्क्रीन के लिए, कभी न खत्म होने वाली स्क्रोलिंग सूची में आइटम फ़ेच किए जाते हैं. लागू करने के बाद, यह नेटवर्क से धीरे-धीरे कनेक्ट हो सकता है. साथ ही, डेटा को लोकल डेटा सोर्स में सेव कर सकता है. इसके बाद, यह लोकल डेटा सोर्स से डेटा को पढ़कर, उपयोगकर्ता को जानकारी दिखा सकता है. अगर नेटवर्क कनेक्टिविटी नहीं है, तो रिपॉज़िटरी सिर्फ़ लोकल डेटा सोर्स से डेटा का अनुरोध कर सकती है. इस पैटर्न का इस्तेमाल Jetpack Paging Library, RemoteMediator एपीआई के साथ करता है.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
पुल-आधारित सिंक्रनाइज़ेशन के फ़ायदे और नुकसान के बारे में यहां बताया गया है:
| फ़ायदे | नुकसान |
|---|---|
| इसे लागू करना आसान है. | इसमें डेटा का इस्तेमाल ज़्यादा होता है. ऐसा इसलिए होता है, क्योंकि नेविगेशन के लिए बार-बार किसी गंतव्य पर जाने से, बिना किसी बदलाव वाली जानकारी को बार-बार फ़ेच करने की ज़रूरत पड़ती है. सही तरीके से कैश मेमोरी का इस्तेमाल करके, इस समस्या को कम किया जा सकता है. इसे यूज़र इंटरफ़ेस (यूआई) लेयर में cachedIn ऑपरेटर की मदद से या नेटवर्क लेयर में एचटीटीपी कैश मेमोरी की मदद से किया जा सकता है. |
| जिस डेटा की ज़रूरत नहीं होती उसे कभी फ़ेच नहीं किया जाता. | यह मॉडल, रिलेशनल डेटा के साथ अच्छी तरह से काम नहीं करता, क्योंकि मॉडल को खुद ही सभी ज़रूरी जानकारी हासिल करनी होती है. अगर सिंक किया जा रहा मॉडल, खुद को भरने के लिए अन्य मॉडल पर निर्भर करता है, तो डेटा के ज़्यादा इस्तेमाल की समस्या और भी गंभीर हो जाती है. इसके अलावा, इससे पैरंट मॉडल की रिपॉज़िटरी और नेस्ट किए गए मॉडल की रिपॉज़िटरी के बीच डिपेंडेंसी (निर्भरता) पैदा हो सकती है. |
पुश-आधारित सिंक्रनाइज़ेशन
पुश-आधारित सिंक्रनाइज़ेशन में, लोकल डेटा सोर्स नेटवर्क डेटा सोर्स के रेप्लिका सेट की नकल करने की पूरी कोशिश करता है. यह पहली बार चालू होने पर, बेसलाइन सेट करने के लिए ज़रूरत के मुताबिक डेटा पहले से ही फ़ेच कर लेता है. इसके बाद, यह सर्वर से मिलने वाली सूचनाओं पर निर्भर करता है. जब डेटा पुराना हो जाता है, तो सर्वर से सूचना मिलती है.
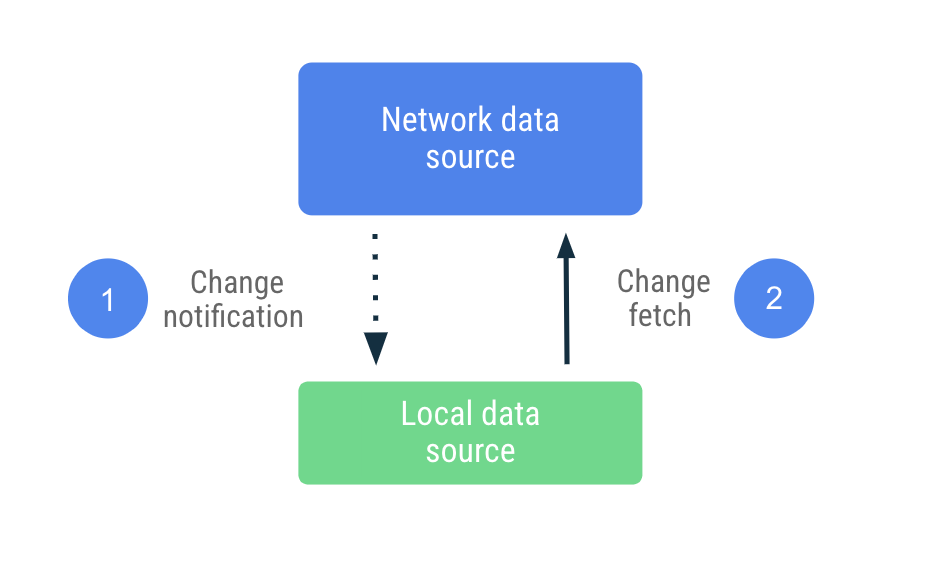
पुरानी सूचना मिलने पर, ऐप्लिकेशन नेटवर्क से संपर्क करता है. ऐसा सिर्फ़ उस डेटा को अपडेट करने के लिए किया जाता है जिसे पुरानी सूचना के तौर पर मार्क किया गया था. यह काम Repository को सौंपा जाता है. यह नेटवर्क डेटा सोर्स से संपर्क करता है और फ़ेच किए गए डेटा को लोकल डेटा सोर्स में सेव करता है. रिपॉज़िटरी, अपने डेटा को ऑब्ज़र्वेबल टाइप के साथ दिखाती है. इसलिए, पढ़ने वालों को किसी भी बदलाव के बारे में सूचना मिल जाती है.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
इस तरीके में, ऐप्लिकेशन नेटवर्क डेटा सोर्स पर बहुत कम निर्भर होता है. साथ ही, यह लंबे समय तक इसके बिना काम कर सकता है. यह ऑफ़लाइन होने पर, पढ़ने और लिखने, दोनों की अनुमति देता है. ऐसा इसलिए, क्योंकि यह मानता है कि इसके पास नेटवर्क डेटा सोर्स से मिली, स्थानीय तौर पर सेव की गई सबसे नई जानकारी है.
पुश-आधारित सिंक्रनाइज़ेशन के फ़ायदे और नुकसान के बारे में यहां बताया गया है:
| फ़ायदे | नुकसान |
|---|---|
| ऐप्लिकेशन को हमेशा के लिए ऑफ़लाइन रखा जा सकता है. | विरोध को हल करने के लिए, वर्शनिंग डेटा बहुत ज़रूरी है. |
| कम से कम डेटा का इस्तेमाल. यह ऐप्लिकेशन सिर्फ़ उस डेटा को फ़ेच करता है जिसमें बदलाव हुआ है. | सिंक करने के दौरान, आपको राइट कंसर्न को ध्यान में रखना होगा. |
| यह रिलेशनल डेटा के लिए बेहतर तरीके से काम करता है. हर रिपॉज़िटरी, सिर्फ़ उस मॉडल के लिए डेटा फ़ेच करती है जिसके साथ वह काम करती है. | नेटवर्क डेटा सोर्स में सिंक्रनाइज़ेशन की सुविधा होनी चाहिए. |
हाइब्रिड सिंक्रनाइज़ेशन
कुछ ऐप्लिकेशन, डेटा के आधार पर पुल या पुश करने का हाइब्रिड तरीका इस्तेमाल करते हैं. उदाहरण के लिए, कोई सोशल मीडिया ऐप्लिकेशन, पुल-आधारित सिंक्रनाइज़ेशन का इस्तेमाल कर सकता है. ऐसा इसलिए, ताकि वह उपयोगकर्ता के फ़ॉलो किए जा रहे लोगों के फ़ीड को ज़रूरत के हिसाब से फ़ेच कर सके. इसकी वजह यह है कि फ़ीड को बार-बार अपडेट किया जाता है. साइन इन किए हुए उपयोगकर्ता के डेटा के लिए, एक ही ऐप्लिकेशन पुश-आधारित सिंक्रनाइज़ेशन का इस्तेमाल कर सकता है. इसमें उपयोगकर्ता का नाम, प्रोफ़ाइल फ़ोटो वगैरह शामिल है.
ऑफ़लाइन-फ़र्स्ट सिंक्रनाइज़ेशन का विकल्प चुनने का फ़ैसला, प्रॉडक्ट की ज़रूरी शर्तों और उपलब्ध तकनीकी इन्फ़्रास्ट्रक्चर पर निर्भर करता है.
विवाद का हल
अगर ऐप्लिकेशन ऑफ़लाइन होने पर, स्थानीय तौर पर ऐसा डेटा लिखता है जो नेटवर्क डेटा सोर्स से मेल नहीं खाता, तो आपको सिंक करने से पहले इस टकराव को ठीक करना होगा.
कॉन्फ़्लिक्ट को हल करने के लिए, अक्सर वर्शनिंग की ज़रूरत होती है. बदलावों को ट्रैक करने के लिए, ऐप्लिकेशन को कुछ बुककीपिंग करनी होती है, ताकि वह नेटवर्क डेटा सोर्स को मेटाडेटा भेज सके. इसके बाद, नेटवर्क डेटा सोर्स की यह ज़िम्मेदारी होती है कि वह भरोसेमंद सोर्स से डेटा उपलब्ध कराए. टकराव की समस्या को हल करने के लिए, कई रणनीतियों का इस्तेमाल किया जा सकता है. हालांकि, यह ऐप्लिकेशन की ज़रूरतों पर निर्भर करता है. मोबाइल ऐप्लिकेशन के लिए, "आखिरी बार किए गए बदलाव को लागू करना" एक सामान्य तरीका है.
लास्ट राइट विंस
इस तरीके में, डिवाइस नेटवर्क पर लिखे गए डेटा में टाइमस्टैंप मेटाडेटा जोड़ते हैं. नेटवर्क डेटा सोर्स को ये अपडेट मिलने पर, वह अपनी मौजूदा स्थिति से पहले के डेटा को खारिज कर देता है. हालांकि, वह अपनी मौजूदा स्थिति के बाद के डेटा को स्वीकार कर लेता है.
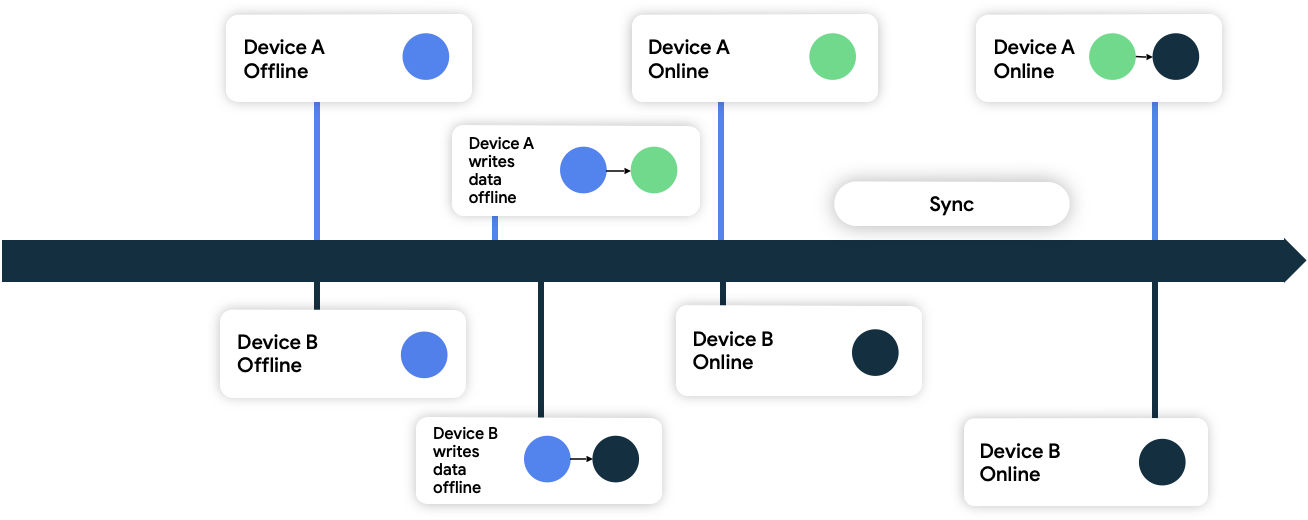
आंकड़े 9 में, दोनों डिवाइस ऑफ़लाइन हैं और शुरू में नेटवर्क डेटा सोर्स के साथ सिंक हैं. ऑफ़लाइन होने पर, दोनों ऐप्लिकेशन स्थानीय तौर पर डेटा लिखते हैं और यह ट्रैक करते हैं कि उन्होंने डेटा कब लिखा था. जब दोनों डिवाइस फिर से ऑनलाइन होते हैं और नेटवर्क डेटा सोर्स के साथ सिंक होते हैं, तो नेटवर्क इस समस्या को हल करता है. इसके लिए, वह डिवाइस B से मिले डेटा को सेव करता है, क्योंकि डिवाइस B ने अपना डेटा बाद में लिखा था.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन में WorkManager का इस्तेमाल करना
पढ़ने और लिखने की रणनीतियों में, दो सामान्य यूटिलिटी होती हैं. इनके बारे में पहले बताया जा चुका है:
- क्यू
- पढ़ता है: इस कुकी का इस्तेमाल, नेटवर्क कनेक्टिविटी उपलब्ध होने तक पढ़ने की प्रोसेस को रोकने के लिए किया जाता है.
- लिखता है: इस कुकी का इस्तेमाल, नेटवर्क कनेक्टिविटी उपलब्ध होने तक लिखने की प्रोसेस को स्थगित करने के लिए किया जाता है. साथ ही, फिर से कोशिश करने के लिए लिखने की प्रोसेस को फिर से कतार में लगाने के लिए किया जाता है.
- नेटवर्क कनेक्टिविटी मॉनिटर
- पढ़ता है: इसका इस्तेमाल, ऐप्लिकेशन के कनेक्ट होने पर रीड क्यू को खाली करने के सिग्नल के तौर पर किया जाता है. साथ ही, इसका इस्तेमाल सिंक्रनाइज़ेशन के लिए भी किया जाता है.
- लिखता है: इस कुकी का इस्तेमाल, ऐप्लिकेशन के कनेक्ट होने पर राइट क्यू को खाली करने के सिग्नल के तौर पर किया जाता है. साथ ही, इसका इस्तेमाल सिंक्रनाइज़ेशन के लिए भी किया जाता है.
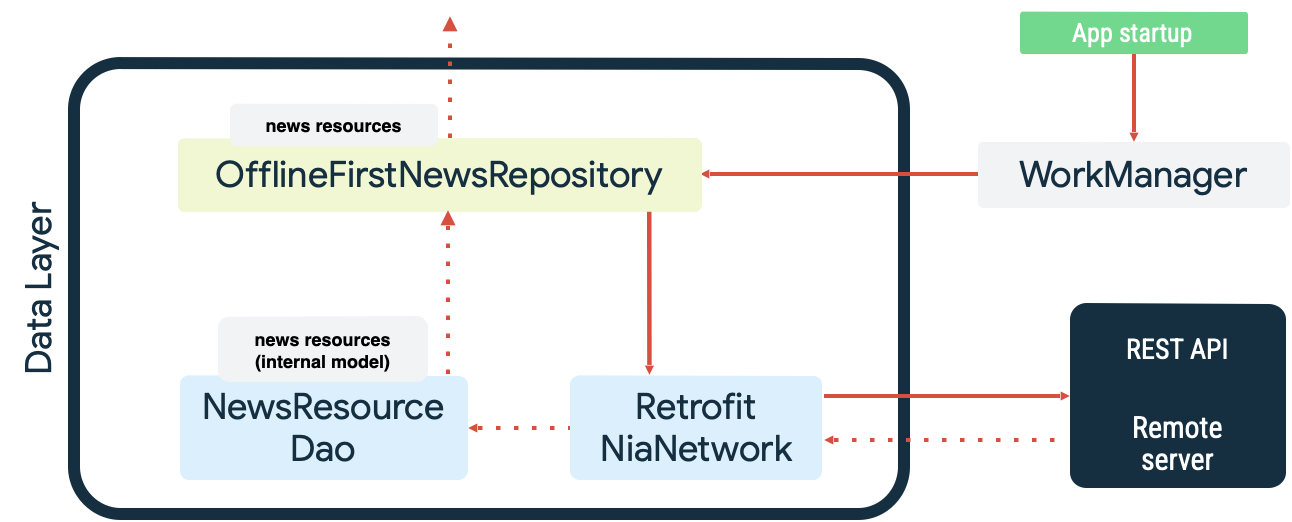
ये दोनों उदाहरण, लंबे समय तक चलने वाले टास्क के हैं. WorkManager ऐसे टास्क को आसानी से मैनेज कर सकता है. उदाहरण के लिए, Now in Android सैंपल ऐप्लिकेशन में, स्थानीय डेटा सोर्स को सिंक करते समय WorkManager का इस्तेमाल, रीड क्यू और नेटवर्क मॉनिटर, दोनों के तौर पर किया जाता है. स्टार्टअप पर, ऐप्लिकेशन ये काम करता है:
- यह कुकी, पढ़ने के लिए सिंक करने का काम करती है. इससे यह पक्का किया जाता है कि लोकल डेटा सोर्स और नेटवर्क डेटा सोर्स के बीच समानता बनी रहे.
- यह कुकी, पढ़ने के लिए सिंक की गई कतार को खाली करती है. साथ ही, ऐप्लिकेशन के ऑनलाइन होने पर सिंक करने की प्रोसेस शुरू करती है.
- यह कुकी, एक्स्पोनेंशियल बैकऑफ़ का इस्तेमाल करके नेटवर्क डेटा सोर्स से डेटा को पढ़ती है.
- यह कुकी, लोकल डेटा सोर्स में पढ़ने के नतीजों को सेव करती है. साथ ही, होने वाले किसी भी टकराव को ठीक करती है.
- यह ऐप्लिकेशन की अन्य लेयर के लिए, लोकल डेटा सोर्स से डेटा दिखाता है, ताकि वे इसका इस्तेमाल कर सकें.
इन कार्रवाइयों को इस डायग्राम में दिखाया गया है:
WorkManager की मदद से, सिंक करने के काम को इस तरह से कतार में लगाया जाता है कि इसे KEEP ExistingWorkPolicy की मदद से यूनीक वर्क के तौर पर सेट किया जाता है:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() को इस तरह परिभाषित किया गया है:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
खास तौर पर, SyncConstraints के ज़रिए तय किए गए Constraints के लिए, यह ज़रूरी है कि NetworkType NetworkType.CONNECTED हो. इसका मतलब है कि यह तब तक नहीं चलता, जब तक नेटवर्क उपलब्ध नहीं हो जाता.
नेटवर्क उपलब्ध होने पर, Worker, SyncWorkName के ज़रिए तय की गई यूनीक वर्क क्यू को खाली कर देता है. इसके लिए, वह सही Repository इंस्टेंस को काम सौंपता है. अगर सिंक नहीं हो पाता है, तो doWork() तरीके से Result.retry() दिखता है. WorkManager, एक्स्पोनेंशियल बैकऑफ़ के साथ सिंक्रनाइज़ेशन को अपने-आप फिर से शुरू कर देगा. अगर ऐसा नहीं होता है, तो यह Result.success() दिखाता है और सिंक करने की प्रोसेस पूरी हो जाती है.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
सैंपल
Google के इन सैंपल से, ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन के बारे में पता चलता है. इन दिशा-निर्देशों को लागू करने के तरीके के बारे में जानने के लिए, इन्हें देखें:
आपके लिए सुझाव
- ध्यान दें: JavaScript बंद होने पर लिंक का टेक्स्ट दिखता है
- यूज़र इंटरफ़ेस (यूआई) स्टेट प्रोडक्शन
- यूज़र इंटरफ़ेस (यूआई) लेयर
- डेटा लेयर