
Aplikacja działająca w trybie offline to aplikacja, która może wykonywać wszystkie lub kluczowe funkcje bez dostępu do internetu. Oznacza to, że może ona wykonywać część lub całość logiki biznesowej w trybie offline.
Kwestie związane z tworzeniem aplikacji działającej w trybie offline zaczynają się w warstwie danych, która zapewnia dostęp do danych aplikacji i logiki biznesowej. Aplikacja może co jakiś czas odświeżać te dane ze źródeł zewnętrznych. W tym celu może korzystać z zasobów sieciowych, aby być na bieżąco.
Dostępność sieci nie zawsze jest gwarantowana. Urządzenia często mają okresy niestabilnego lub wolnego połączenia z siecią. Użytkownicy mogą zauważyć następujące objawy:
- Ograniczona przepustowość internetu
- krótkotrwałe przerwy w połączeniu, np. podczas korzystania z windy lub przejazdu przez tunel;
- Okazjonalny dostęp do danych – np. tablety obsługujące tylko Wi-Fi
Niezależnie od przyczyny w takich okolicznościach aplikacja często może działać prawidłowo. Aby aplikacja działała prawidłowo w trybie offline, musi mieć możliwość:
- działać bez niezawodnego połączenia z siecią;
- natychmiastowe wyświetlanie użytkownikom danych produktów dostępnych lokalnie zamiast czekania na zakończenie lub niepowodzenie pierwszego wywołania sieciowego;
- Pobieranie danych w sposób uwzględniający stan baterii i danych – na przykład przez wysyłanie żądań pobierania danych tylko w optymalnych warunkach, takich jak ładowanie lub połączenie z Wi-Fi.
Aplikacja, która spełnia te kryteria, jest często nazywana aplikacją działającą w trybie offline.
Projektowanie aplikacji działającej w trybie offline
Projektując aplikację działającą w trybie offline, zacznij od warstwy danych i dwóch głównych operacji, które możesz wykonywać na danych aplikacji:
- Odczyt: pobieranie danych do wykorzystania przez inne części aplikacji, np. do wyświetlania informacji użytkownikowi. W Compose zwykle osiąga się to przez obserwowanie stanu. Gdy interfejs użytkownika obserwuje lokalne źródło danych jako stan, ekran automatycznie odzwierciedla najnowsze dane produktów dostępnych lokalnie.
- Zapisywanie: Utrwalanie danych wejściowych użytkownika w celu późniejszego pobrania. W Compose zwykle osiąga się to za pomocą zdarzeń i działań wysyłanych z interfejsu do ViewModelu.
Repozytoria w warstwie danych odpowiadają za łączenie źródeł danych w celu dostarczania danych aplikacji. W aplikacji działającej w trybie offline musi być co najmniej 1 źródło danych, które nie wymaga dostępu do sieci, aby wykonywać najważniejsze zadania. Jednym z tych kluczowych zadań jest odczytywanie danych.
Modelowanie danych w aplikacji działającej w trybie offline
Aplikacja działająca w trybie offline ma co najmniej 2 źródła danych dla każdego repozytorium, które korzysta z zasobów sieciowych:
- Lokalne źródło danych
- Źródło danych sieci
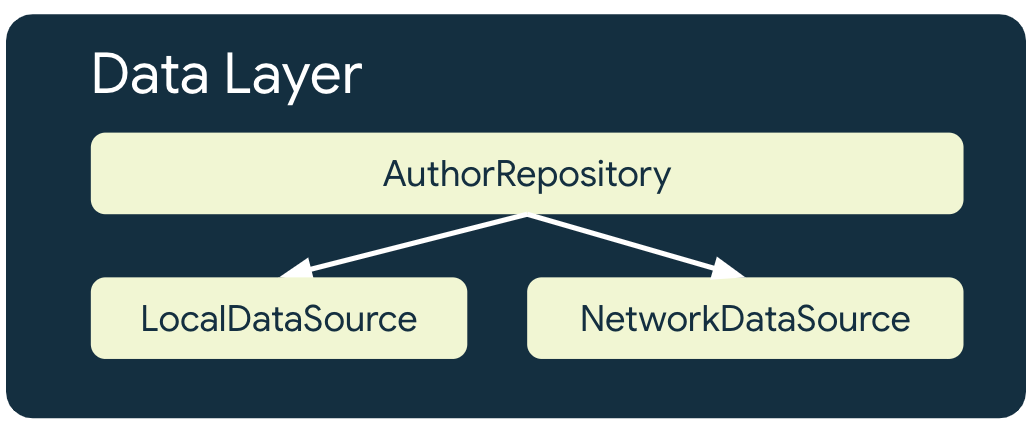
Lokalne źródło danych
Lokalne źródło danych jest kanonicznym źródłem informacji dla aplikacji. Powinno być wyłącznym źródłem danych odczytywanych przez wyższe warstwy aplikacji. Zapewnia to spójność danych między stanami połączenia. Lokalne źródło danych jest często obsługiwane przez pamięć masową, która jest zapisywana na dysku. Oto niektóre typowe sposoby zapisywania danych na dysku:
- źródła danych strukturalnych, takie jak relacyjne bazy danych, np. Room;
- Źródła danych nieuporządkowanych, np. bufory protokołu z magazynem danych
- Proste pliki
Źródło danych sieci
Źródło danych sieciowych to rzeczywisty stan aplikacji. W najlepszym przypadku lokalne źródło danych jest synchronizowane ze źródłem danych w sieci. Źródło danych produktów dostępnych lokalnie może też być opóźnione w stosunku do źródła danych sieciowych. W takim przypadku aplikację należy zaktualizować po ponownym połączeniu z internetem. Z kolei źródło danych sieciowych może być opóźnione w stosunku do danych produktów dostępnych lokalnie, dopóki aplikacja nie będzie mogła go zaktualizować po przywróceniu łączności. Warstwy domeny i interfejsu aplikacji nie mogą nigdy komunikować się bezpośrednio z warstwą sieciową. Za komunikację z nim i używanie go do aktualizowania danych produktów dostępnych lokalnie odpowiada hosting repository.
Udostępnianie zasobów
Lokalne i sieciowe źródła danych mogą się zasadniczo różnić pod względem sposobu, w jaki aplikacja może z nich odczytywać i do nich zapisywać dane. Wysyłanie zapytań do lokalnego źródła danych może być szybkie i elastyczne, np. w przypadku zapytań SQL. Z kolei źródła danych sieciowych mogą być wolne i ograniczone, np. podczas przyrostowego uzyskiwania dostępu do zasobów RESTful według identyfikatora. Dlatego każde źródło danych często wymaga własnej reprezentacji dostarczanych przez nie danych. Lokalne źródło danych i sieciowe źródło danych mogą więc mieć własne modele.
Tę koncepcję ilustruje poniższa struktura katalogów. Symbol AuthorEntity oznacza autora odczytanego z lokalnej bazy danych aplikacji, a symbol NetworkAuthor oznacza autora serializowanego w sieci:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Szczegóły plików AuthorEntity i NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Sprawdzoną metodą jest przechowywanie zarówno AuthorEntity, jak i NetworkAuthor w warstwie danych oraz udostępnianie trzeciego typu warstwom zewnętrznym. Chroni to warstwy zewnętrzne przed drobnymi zmianami w lokalnych i sieciowych źródłach danych, które nie zmieniają zasadniczo działania aplikacji. Ilustruje to poniższy fragment kodu:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Model sieciowy może następnie zdefiniować metodę rozszerzenia, aby przekonwertować go na model lokalny, a model lokalny ma podobną metodę, aby przekonwertować go na reprezentację zewnętrzną, jak pokazano w tym fragmencie:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Odczyty
Odczytywanie to podstawowa operacja na danych aplikacji działającej w trybie offline. Musisz więc zadbać o to, aby aplikacja mogła odczytywać dane i wyświetlać je, gdy tylko staną się dostępne. Aplikacja, która to umożliwia, jest reaktywna, ponieważ udostępnia interfejsy API do odczytu z typami obserwowalnymi.
W tym fragmencie kodu funkcja OfflineFirstTopicRepository zwraca Flows dla wszystkich interfejsów API do odczytu. Dzięki temu może informować czytniki o otrzymywanych aktualizacjach ze źródła danych sieci. Innymi słowy, umożliwia to OfflineFirstTopicRepository przesyłanie zmian, gdy lokalne źródło danych zostanie unieważnione. Dlatego każdy czytnik OfflineFirstTopicRepository musi być przygotowany na obsługę zmian danych, które mogą być wywoływane po przywróceniu połączenia sieciowego z aplikacją. Ponadto OfflineFirstTopicRepository odczytuje dane bezpośrednio ze źródła danych lokalnych. Może powiadamiać czytelników o zmianach danych tylko wtedy, gdy najpierw zaktualizuje lokalne źródło danych.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
W aplikacji Jetpack Compose używaj ViewModelu do łączenia warstwy danych z interfejsem.
W obiekcie ViewModel przekonwertuj Flow na StateFlow za pomocą operatora stateIn. Funkcje kompozycyjne zbierają te stany za pomocą funkcji collectAsStateWithLifecycle() i automatycznie zarządzają subskrypcjami w sposób uwzględniający cykl życia.
Więcej informacji o collectAsStateWithLifecycle() znajdziesz w artykule Stan i Jetpack Compose.
Strategie obsługi błędów
W aplikacjach działających w trybie offline błędy można obsługiwać na różne sposoby, w zależności od źródeł danych, w których mogą wystąpić. W kolejnych podsekcjach opisujemy te strategie.
Lokalne źródło danych
Staraj się minimalizować błędy podczas odczytywania danych produktów dostępnych lokalnie z lokalnego źródła danych. Aby chronić czytelników przed błędami, użyj operatora catch w przypadku Flow, z których czytelnik zbiera dane.
Operatora catch możesz używać w ViewModel w ten sposób:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Aby uzyskać bardziej odporne rozwiązanie, rozważ użycie LCE (Loading Content Error). W LCE, gdy podczas odczytu wystąpi błąd, wyświetlasz stan błędu. Zwykle stan LCE osiąga się, modelując stany interfejsu jako klasy zapieczętowane w Kotlinie.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Źródło danych sieciowych
Jeśli podczas odczytywania danych ze źródła danych sieciowych wystąpią błędy, aplikacja musi zastosować heurystykę, aby ponowić pobieranie danych. Do typowych heurystyk należą:
Wzrastający czas do ponowienia
W przypadku wzrastającego czasu do ponowienia aplikacja próbuje odczytać dane ze źródła danych sieciowych z coraz dłuższymi odstępami czasu, dopóki nie zakończy się to powodzeniem lub inne warunki nie spowodują, że należy przerwać tę czynność.
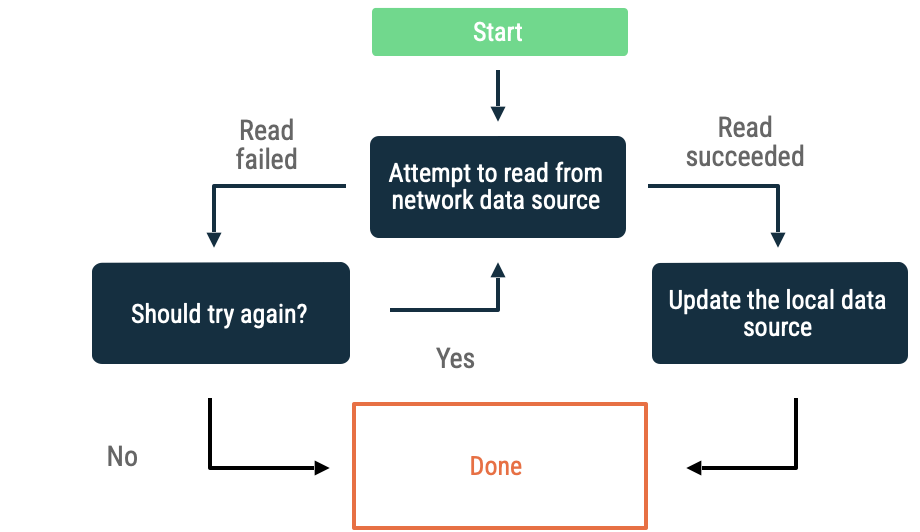
Kryteria oceny, czy aplikacja nadal się wycofuje, obejmują:
- Rodzaj błędu wskazanego przez sieciowe źródło danych. Na przykład ponawiaj wywołania sieciowe, które zwracają błąd wskazujący na brak łączności. Nie ponawiaj nieautoryzowanych żądań HTTP, dopóki nie będą dostępne odpowiednie dane logowania.
- Maksymalna dozwolona liczba ponownych prób.
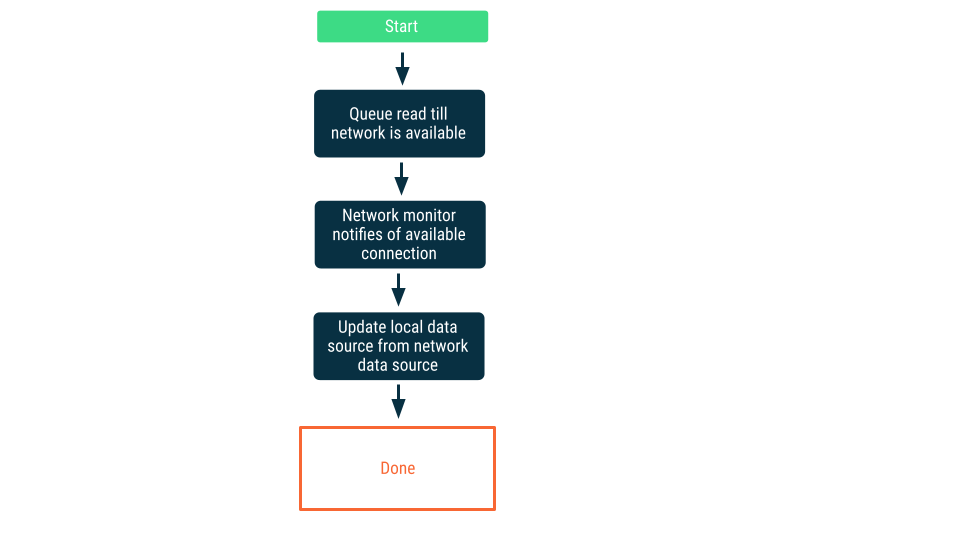
Monitorowanie połączeń sieciowych
W tym podejściu żądania odczytu są umieszczane w kolejce, dopóki aplikacja nie będzie mieć pewności, że może połączyć się ze źródłem danych sieciowych. Po nawiązaniu połączenia żądanie odczytu jest usuwane z kolejki, dane są odczytywane, a lokalne źródło danych jest aktualizowane. Na Androidzie ta kolejka może być utrzymywana w bazie danych Room i opróżniana w ramach trwałej pracy za pomocą WorkManagera.
Zapisy
Zalecanym sposobem odczytywania danych w aplikacji działającej w trybie offline jest używanie typów obserwowalnych. Odpowiednikiem interfejsów API do zapisu są asynchroniczne interfejsy API, takie jak funkcje zawieszania. Pozwala to uniknąć blokowania wątku UI i ułatwia obsługę błędów, ponieważ zapisywanie w aplikacjach działających w trybie offline może się nie powieść podczas przekraczania granicy sieci.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
W powyższym fragmencie kodu wybranym asynchronicznym interfejsem API są korutyny, ponieważ metoda jest zawieszana.
Strategie pisania
Podczas zapisywania danych w aplikacjach działających w trybie offline należy wziąć pod uwagę 3 strategie. Wybór zależy od rodzaju zapisywanych danych i wymagań aplikacji:
Zapisy tylko online
Próba zapisania danych poza granicami sieci. Jeśli się powiedzie, zaktualizuj lokalne źródło danych. W przeciwnym razie zgłoś wyjątek i pozostaw odpowiedź wywołującemu.
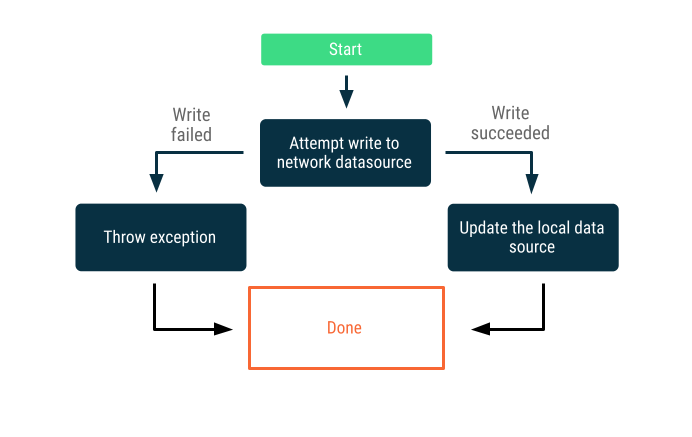
Ta strategia jest często używana w przypadku transakcji zapisu, które muszą być przeprowadzane online w czasie zbliżonym do rzeczywistego, np. przelew bankowy. Ponieważ zapisywanie może się nie udać, często konieczne jest poinformowanie użytkownika o tym, że zapisywanie się nie powiodło, lub uniemożliwienie mu próby zapisania danych. Oto kilka strategii, które możesz zastosować w takich sytuacjach:
- Jeśli aplikacja wymaga dostępu do internetu, aby zapisywać dane, możesz nie wyświetlać użytkownikowi interfejsu, który umożliwia zapisywanie danych, lub przynajmniej go wyłączyć.
- Możesz użyć
AlertDialog, którego użytkownik nie może zamknąć, lubSnackbar, aby powiadomić użytkownika, że jest offline.
Zapisy w kolejce
Gdy masz obiekt, o którym chcesz napisać, umieść go w kolejce. Gdy aplikacja ponownie połączy się z internetem, opróżnij kolejkę, stosując wzrastający czas do ponowienia. Na Androidzie opróżnianie kolejki offline to ciągła praca, która jest często delegowana do WorkManager.
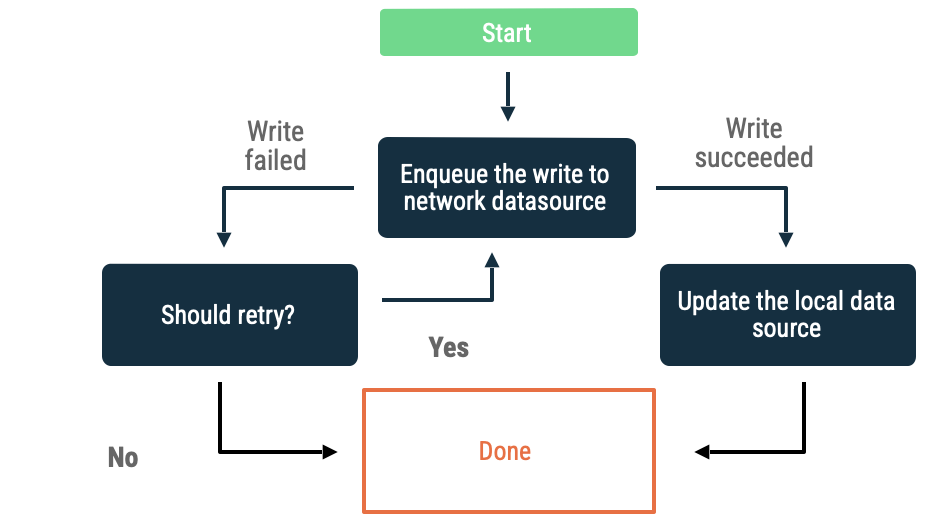
To podejście jest dobrym wyborem w tych sytuacjach:
- Nie jest konieczne, aby dane były kiedykolwiek zapisywane w sieci.
- Transakcja nie jest wrażliwa na czas.
- Nie jest konieczne informowanie użytkownika o niepowodzeniu operacji.
Przykłady zastosowań tego podejścia to zdarzenia analityczne i logowanie.
Opóźnione zapisy
Najpierw zapisz dane produktów dostępnych lokalnie w lokalnym źródle danych, a potem umieść zapis w kolejce, aby jak najszybciej powiadomić sieć. Nie jest to proste, ponieważ po ponownym połączeniu aplikacji z siecią mogą wystąpić konflikty między siecią a lokalnymi źródłami danych. Więcej informacji znajdziesz w następnej sekcji dotyczącej rozwiązywania konfliktów.
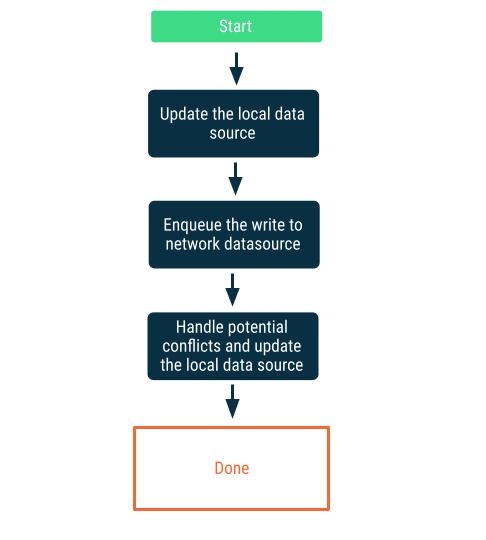
To właściwe rozwiązanie, gdy dane są kluczowe dla aplikacji. Na przykład w aplikacji do tworzenia list zadań działającej w trybie offline najważniejsze jest, aby wszystkie zadania dodane przez użytkownika w trybie offline były przechowywane lokalnie, co pozwala uniknąć ryzyka utraty danych.
Synchronizacja i rozwiązywanie konfliktów
Gdy aplikacja działająca w trybie offline odzyska połączenie, musi uzgodnić dane w lokalnym źródle danych z danymi w źródle danych w sieci. Ten proces nazywa się synchronizacją. Aplikacja może synchronizować się ze źródłem danych sieciowych na 2 główne sposoby:
- Synchronizacja oparta na pobieraniu
- Synchronizacja oparta na wysyłaniu
Synchronizacja oparta na pobieraniu
W synchronizacji opartej na pobieraniu aplikacja kontaktuje się z siecią, aby na żądanie odczytać najnowsze dane aplikacji. Powszechną heurystyką w tym podejściu jest nawigacja, w której aplikacja pobiera dane tylko tuż przed wyświetleniem ich użytkownikowi.
To podejście sprawdza się najlepiej, gdy aplikacja spodziewa się krótkich lub średnich okresów braku połączenia z siecią. Dzieje się tak, ponieważ odświeżanie danych jest oportunistyczne, a długie okresy braku łączności zwiększają prawdopodobieństwo, że użytkownik spróbuje odwiedzić miejsca docelowe w aplikacji z pamięcią podręczną, która jest nieaktualna lub pusta.
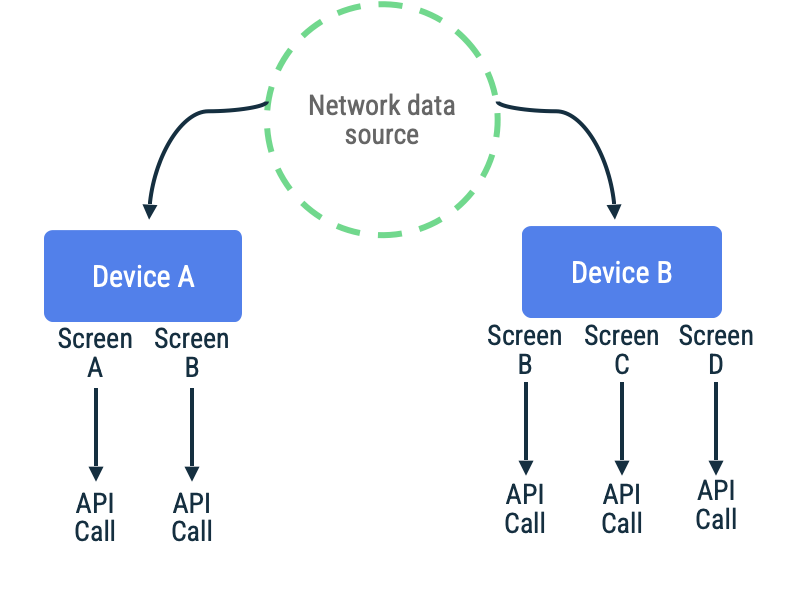
Rozważmy aplikację, w której tokeny stron są używane do pobierania elementów z listy z nieskończonym przewijaniem na konkretnym ekranie. Implementacja może leniwie łączyć się z siecią, zapisywać dane w lokalnym źródle danych, a następnie odczytywać je z tego źródła, aby wyświetlać informacje użytkownikowi. W przypadku braku połączenia z siecią repozytorium może wysyłać żądania danych tylko do lokalnego źródła danych. Jest to wzorzec używany przez bibliotekę paginowania Jetpack z interfejsem RemoteMediator API.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Zalety i wady synchronizacji opartej na pobieraniu zostały podsumowane w tabeli poniżej:
| Zalety | Wady |
|---|---|
| Stosunkowo łatwe do wdrożenia. | Może zużywać duże ilości danych. Dzieje się tak, ponieważ wielokrotne wizyty w miejscu docelowym nawigacji powodują niepotrzebne ponowne pobieranie niezmienionych informacji. Możesz temu zapobiec, stosując odpowiednie buforowanie. Możesz to zrobić w warstwie interfejsu za pomocą operatora cachedIn lub w warstwie sieci za pomocą pamięci podręcznej HTTP. |
| Dane, które nie są potrzebne, nigdy nie są pobierane. | Nie skaluje się dobrze w przypadku danych relacyjnych, ponieważ pobrany model musi być samowystarczalny. Jeśli synchronizowany model zależy od innych modeli, które muszą zostać pobrane, aby można było go wypełnić, problem z dużym zużyciem danych, o którym wspomnieliśmy wcześniej, staje się jeszcze poważniejszy. Może to również powodować zależności między repozytoriami modelu nadrzędnego a repozytoriami modelu zagnieżdżonego. |
Synchronizacja oparta na wysyłaniu
W synchronizacji opartej na wysyłaniu dane produktów dostępnych lokalnie w największym możliwym stopniu próbują naśladować zestaw replik sieciowego źródła danych. Podczas pierwszego uruchomienia aktywnie pobiera odpowiednią ilość danych, aby ustalić wartość bazową. Następnie polega na powiadomieniach z serwera, które informują o tym, że dane są nieaktualne.
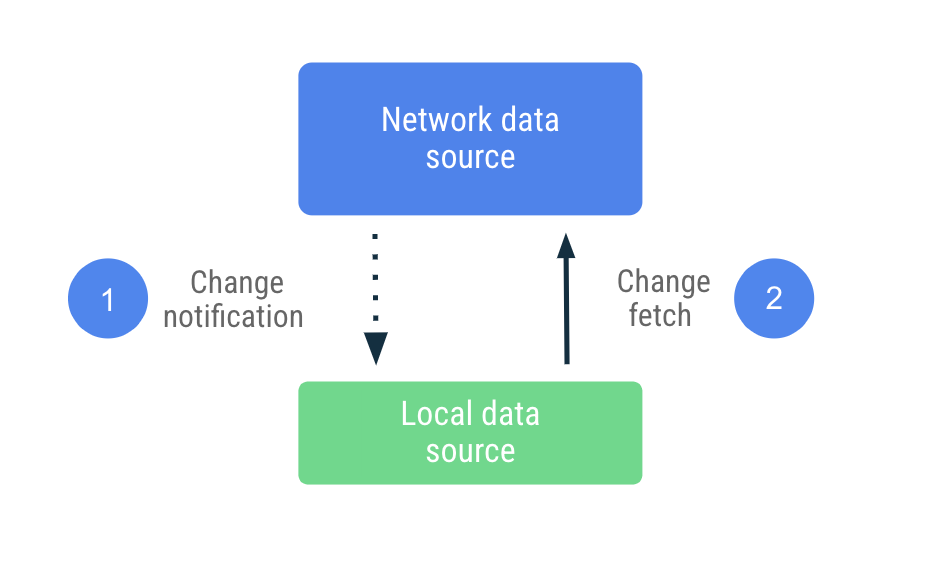
Po otrzymaniu nieaktualnego powiadomienia aplikacja kontaktuje się z siecią, aby zaktualizować tylko dane oznaczone jako nieaktualne. To zadanie jest delegowane do Repository, który łączy się ze źródłem danych w sieci i zapisuje pobrane dane w lokalnym źródle danych. Ponieważ repozytorium udostępnia dane w postaci typów obserwowalnych, czytelnicy są powiadamiani o wszelkich zmianach.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
W tym podejściu aplikacja jest znacznie mniej zależna od źródła danych sieciowych i może działać bez niego przez dłuższy czas. W trybie offline zapewnia dostęp do odczytu i zapisu, ponieważ zakłada, że lokalnie ma najnowsze informacje ze źródła danych sieciowych.
Zalety i wady synchronizacji opartej na wysyłaniu znajdziesz w tabeli poniżej:
| Zalety | Wady |
|---|---|
| Aplikacja może pozostawać offline przez czas nieokreślony. | Dane dotyczące wersji do rozwiązywania konfliktów są nietrywialne. |
| Minimalne wykorzystywanie danych. Aplikacja pobiera tylko dane, które uległy zmianie. | Podczas synchronizacji musisz wziąć pod uwagę kwestie związane z zapisem. |
| Sprawdza się w przypadku danych relacyjnych. Każde repozytorium jest odpowiedzialne za pobieranie danych tylko dla obsługiwanego przez nie modelu. | Źródło danych sieci musi obsługiwać synchronizację. |
Synchronizacja hybrydowa
Niektóre aplikacje stosują podejście hybrydowe, które w zależności od danych jest oparte na pobieraniu lub wysyłaniu. Na przykład aplikacja do obsługi mediów społecznościowych może używać synchronizacji opartej na pobieraniu, aby na żądanie pobierać kanał obserwowanych użytkowników ze względu na dużą częstotliwość aktualizacji kanału. Ta sama aplikacja może używać synchronizacji opartej na pushu w przypadku danych zalogowanego użytkownika, w tym jego nazwy użytkownika, zdjęcia profilowego itp.
Ostatecznie wybór synchronizacji w trybie offline zależy od wymagań produktu i dostępnej infrastruktury technicznej.
Rozwiązywanie konfliktów
Jeśli w trybie offline aplikacja zapisuje lokalnie dane, które są niezgodne ze źródłem danych sieciowych, musisz rozwiązać konflikt, zanim będzie można przeprowadzić synchronizację.
Rozwiązywanie konfliktów często wymaga tworzenia wersji. Aplikacja musi prowadzić ewidencję, aby śledzić, kiedy nastąpiły zmiany, i przekazywać metadane do sieciowego źródła danych. Źródło danych sieciowych jest wtedy odpowiedzialne za dostarczanie absolutnego źródła informacji. Istnieje wiele strategii rozwiązywania konfliktów, które można zastosować w zależności od potrzeb aplikacji. W przypadku aplikacji mobilnych powszechnie stosowane jest podejście „ostatni zapis wygrywa”.
Ostatni zapis wygrywa
W tym podejściu urządzenia dołączają metadane sygnatury czasowej do danych zapisywanych w sieci. Gdy źródło danych sieciowych je otrzyma, odrzuci wszystkie dane starsze niż jego obecny stan, a zaakceptuje te nowsze.
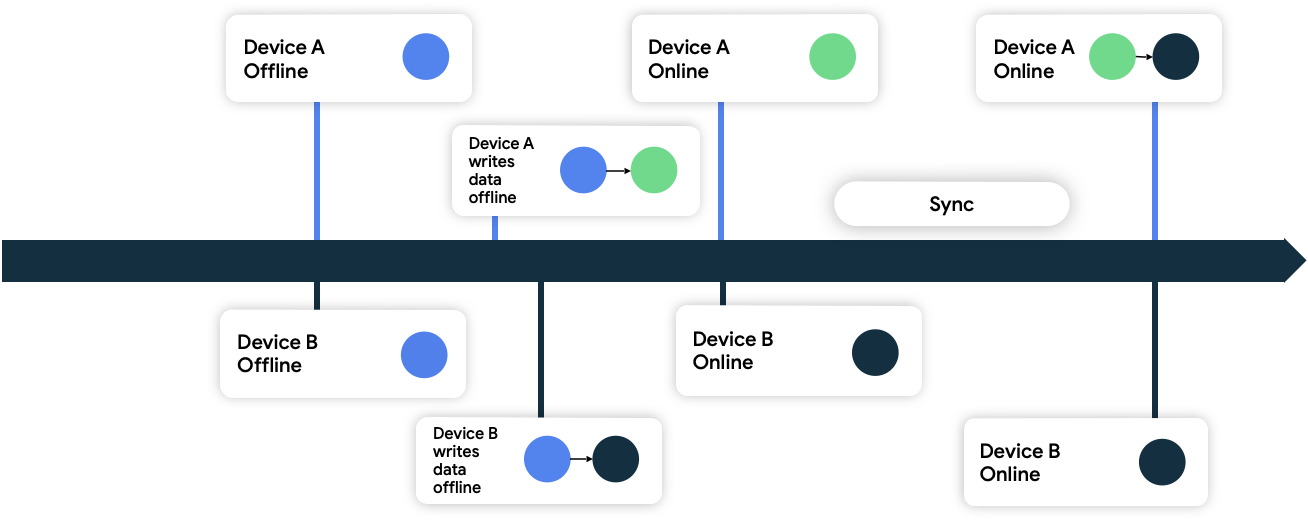
Na rysunku 9 oba urządzenia są offline i początkowo zsynchronizowane ze źródłem danych sieciowych. W trybie offline oba urządzenia zapisują dane lokalnie i śledzą czas, w którym zostały one zapisane. Gdy oba urządzenia ponownie połączą się z internetem i zsynchronizują ze źródłem danych w sieci, sieć rozwiąże konflikt, zachowując dane z urządzenia B, ponieważ zostały one zapisane później.
WorkManager w aplikacjach działających w trybie offline
W przypadku obu strategii odczytu i zapisu omówionych wcześniej istnieją 2 popularne narzędzia:
- Kolejki
- Odczytuje: służy do odraczania odczytów do czasu, aż będzie dostępne połączenie sieciowe.
- Zapisywanie: służy do odraczania zapisów do momentu, gdy połączenie sieciowe będzie dostępne, oraz do ponownego kolejkowania zapisów w celu ponowienia prób.
- Monitory połączeń sieciowych
- Odczyt: używany jako sygnał do opróżniania kolejki odczytu, gdy aplikacja jest połączona, oraz do synchronizacji.
- Zapisywanie: używane jako sygnał do opróżniania kolejki zapisu, gdy aplikacja jest połączona, oraz do synchronizacji.
Oba te przypadki są przykładami trwałej pracy, w której WorkManager sprawdza się doskonale. Na przykład w przykładowej aplikacji Now in Android usługa WorkManager jest używana jako kolejka odczytu i monitor sieci podczas synchronizacji lokalnego źródła danych. Po uruchomieniu aplikacja wykonuje te czynności:
- Kolejkuje zadanie synchronizacji odczytu, aby zapewnić równość między lokalnym a sieciowym źródłem danych.
- Opróżnia kolejkę synchronizacji odczytu i rozpoczyna synchronizację, gdy aplikacja jest online.
- Wykonuje odczyt ze źródła danych sieciowych przy użyciu wzrastającego czasu do ponowienia.
- Utrwala wyniki odczytu w lokalnym źródle danych i rozwiązuje wszelkie konflikty.
- Udostępnia dane produktów dostępnych lokalnie z lokalnego źródła danych innym warstwom aplikacji.
Te działania przedstawia poniższy diagram:
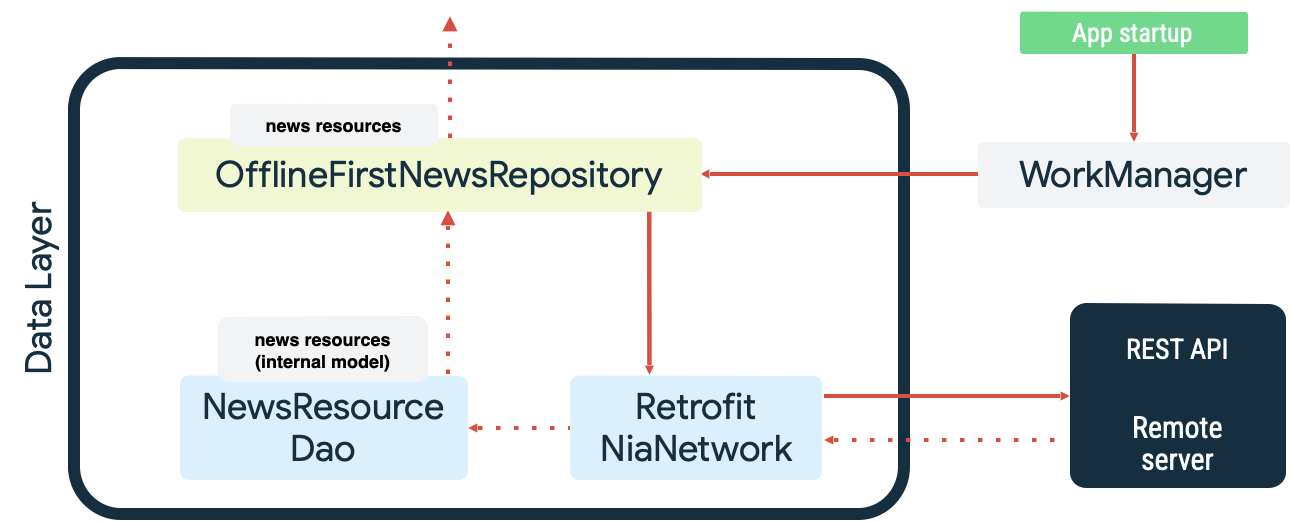
Kolejkowanie pracy synchronizacji za pomocą WorkManagera odbywa się przez określenie jej jako unikalnej pracy za pomocą KEEP ExistingWorkPolicy:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() jest zdefiniowane w ten sposób:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
W szczególności Constraints zdefiniowane przez SyncConstraints wymagają, aby NetworkType miało wartość NetworkType.CONNECTED. Oznacza to, że czeka na dostępność sieci, zanim zacznie działać.
Gdy sieć jest dostępna, instancja robocza opróżnia unikalną kolejkę zadań określoną przez SyncWorkName, delegując zadania do odpowiednich instancji Repository. Jeśli synchronizacja się nie powiedzie, metoda doWork() zwraca wartość Result.retry(). Biblioteka WorkManager automatycznie ponowi synchronizację ze wzrastającym czasem do ponowienia. W przeciwnym razie zwraca wartość Result.success(), kończąc synchronizację.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Przykłady
Poniższe przykłady Google pokazują aplikacje działające w trybie offline. Zapoznaj się z nimi, aby zobaczyć te wskazówki w praktyce:
Polecane dla Ciebie
- Uwaga: tekst linku jest wyświetlany, gdy język JavaScript jest wyłączony.
- Produkcja stanu interfejsu
- Warstwa interfejsu
- Warstwa danych