
Приложение, ориентированное на работу в автономном режиме, — это приложение, способное выполнять все или критически важную часть своей основной функциональности без доступа к интернету. То есть, оно может выполнять часть или всю свою бизнес-логику в автономном режиме.
При разработке приложения, ориентированного на работу в автономном режиме, следует учитывать особенности уровня данных , который обеспечивает доступ к данным приложения и бизнес-логике. Время от времени приложению может потребоваться обновлять эти данные из внешних источников. Для этого ему может потребоваться использовать сетевые ресурсы, чтобы оставаться в курсе событий.
Доступность сети не всегда гарантирована. Устройства часто испытывают периоды нестабильного или медленного сетевого соединения. Пользователи могут столкнуться со следующими проблемами:
- Ограниченная пропускная способность интернета
- Временные перебои в соединении, например, в лифте или туннеле.
- Периодический доступ к данным — например, на планшетах, работающих только через Wi-Fi.
Независимо от причины, приложение часто может адекватно функционировать в подобных условиях. Чтобы ваше приложение корректно работало в автономном режиме, оно должно уметь следующее:
- Остается работоспособным даже без надежного сетевого соединения.
- Предоставляйте пользователям локальные данные немедленно, вместо того чтобы ждать завершения или сбоя первого сетевого вызова.
- Получайте данные с учетом состояния батареи и трафика — например, запрашивая получение данных только в оптимальных условиях, таких как зарядка или подключение к Wi-Fi.
Приложение, отвечающее этим критериям, часто называют приложением, ориентированным на работу в офлайн-режиме.
Разработайте приложение, ориентированное в первую очередь на работу в офлайн-режиме.
При разработке приложения, ориентированного на работу в автономном режиме, начните с уровня данных и двух основных операций, которые можно выполнять с данными приложения:
- Чтение : Получение данных для использования другими частями приложения, например, для отображения информации пользователю. В Compose это обычно достигается путем отслеживания состояния . Когда ваш пользовательский интерфейс отслеживает локальный источник данных как состояние, экран автоматически отображает последние локальные данные.
- Запись : Сохранение пользовательского ввода для последующего извлечения. В Compose это обычно достигается с помощью событий и действий, отправляемых из пользовательского интерфейса в ViewModel.
Репозитории на уровне данных отвечают за объединение источников данных для предоставления данных приложению. В приложении, работающем в автономном режиме, должен быть как минимум один источник данных, которому не требуется сетевой доступ для выполнения наиболее важных задач. Одной из таких важных задач является чтение данных.
Моделирование данных в приложении, ориентированном на работу в офлайн-режиме.
В приложении, ориентированном на работу в автономном режиме, для каждого репозитория, использующего сетевые ресурсы, должно быть как минимум 2 источника данных:
- Локальный источник данных
- Источник сетевых данных
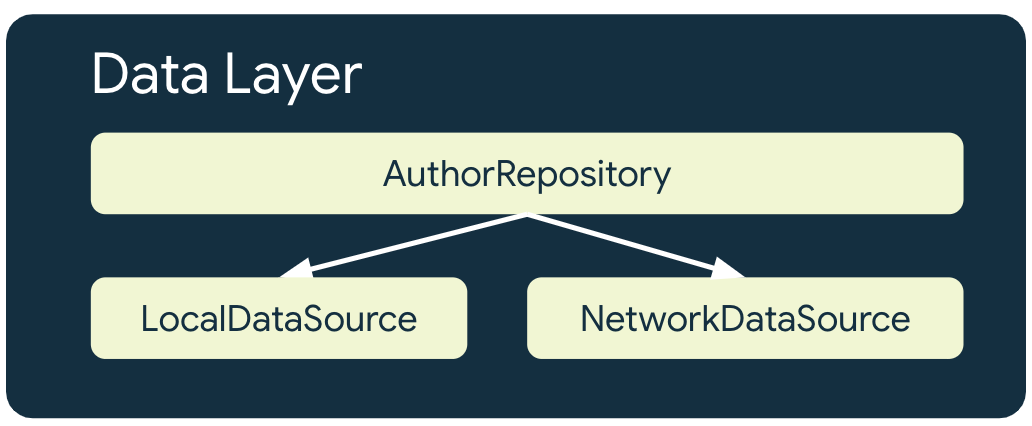
Локальный источник данных
Локальный источник данных является каноническим источником достоверной информации для приложения. Он должен быть единственным источником любых данных, которые считывают вышестоящие уровни приложения. Это обеспечивает согласованность данных между состояниями соединения. Локальный источник данных часто поддерживается хранилищем, данные которого сохраняются на диске. К распространенным способам сохранения данных на диск относятся следующие:
- Структурированные источники данных, такие как реляционные базы данных, например, Room.
- Неструктурированные источники данных — например, протокол буферизации с использованием DataStore.
- Простые файлы
Источник сетевых данных
Сетевой источник данных отражает фактическое состояние приложения. В лучшем случае локальный источник данных синхронизирован с сетевым. Локальный источник данных также может отставать от сетевого, в этом случае приложение необходимо обновить после восстановления онлайн-соединения. И наоборот, сетевой источник данных может отставать от локального до тех пор, пока приложение не сможет обновить его после восстановления связи. Домен и пользовательский интерфейс приложения никогда не должны напрямую взаимодействовать с сетевым уровнем. В обязанности хостинг- repository входит взаимодействие с ним и использование его для обновления локального источника данных.
Раскрытие ресурсов
Локальные и сетевые источники данных могут принципиально различаться по способу чтения и записи данных в них. Запросы к локальному источнику данных могут быть быстрыми и гибкими, например, при использовании SQL-запросов. В отличие от них, сетевые источники данных могут быть медленными и ограниченными, например, при инкрементальном доступе к RESTful-ресурсам по идентификатору. В результате каждому источнику данных часто требуется собственное представление предоставляемых им данных. Поэтому локальный и сетевой источники данных могут иметь свои собственные модели.
Следующая структура каталогов помогает визуализировать эту концепцию. AuthorEntity представляет автора, считанного из локальной базы данных приложения, а NetworkAuthor представляет автора, сериализованного по сети:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Ниже приведена подробная информация об объектах AuthorEntity и NetworkAuthor :
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Рекомендуется хранить AuthorEntity и NetworkAuthor внутри слоя данных и предоставлять третий тип для использования внешними слоями. Это защищает внешние слои от незначительных изменений в локальных и сетевых источниках данных, которые не вносят принципиального изменения в поведение приложения. Это демонстрируется в следующем фрагменте кода:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Затем сетевая модель может определить метод расширения для преобразования в локальную модель, и локальная модель, в свою очередь, имеет метод для преобразования во внешнее представление, как показано в следующем фрагменте кода:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Читает
Чтение — это основная операция над данными приложения в приложении, ориентированном на работу в автономном режиме. Поэтому необходимо убедиться, что ваше приложение может читать данные и что, как только новые данные становятся доступны, приложение может их отобразить. Приложение, способное это делать, является реактивным, поскольку оно предоставляет API для чтения с использованием наблюдаемых типов.
В приведенном ниже фрагменте кода OfflineFirstTopicRepository возвращает Flow для всех своих API чтения. Это позволяет ему обновлять данные своих читателей при получении обновлений из сетевого источника данных. Другими словами, это позволяет OfflineFirstTopicRepository отправлять изменения, когда его локальный источник данных становится недействительным. Следовательно, каждый читатель OfflineFirstTopicRepository должен быть готов обрабатывать изменения данных, которые могут быть вызваны восстановлением сетевого соединения с приложением. Кроме того, OfflineFirstTopicRepository считывает данные непосредственно из локального источника данных. Он может уведомлять своих читателей об изменениях данных только после предварительного обновления своего локального источника данных.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
В приложении Jetpack Compose используйте ViewModel для связи уровня данных и пользовательского интерфейса. В ViewModel преобразуйте Flow в StateFlow , используя оператор stateIn . Затем Composables собирают эти состояния с помощью collectAsStateWithLifecycle() и автоматически управляют подписками с учетом жизненного цикла.
Для получения дополнительной информации о функции collectAsStateWithLifecycle() см. раздел «Состояние» и Jetpack Compose .
Стратегии обработки ошибок
В зависимости от источников данных, где могут возникать ошибки, в приложениях, работающих в автономном режиме, существуют уникальные способы их обработки. В следующих подразделах описаны эти стратегии.
Локальный источник данных
Старайтесь свести к минимуму ошибки при чтении из локального источника данных. Для защиты читателей от ошибок используйте оператор catch в Flow , из которых читатель получает данные.
Оператор catch можно использовать в ViewModel следующим образом:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Для более отказоустойчивого подхода рассмотрите решение LCE (Loading Content Error). В LCE при возникновении ошибки чтения отображается состояние ошибки. Обычно LCE реализуется путем моделирования состояний пользовательского интерфейса в виде закрытых классов Kotlin .
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Источник сетевых данных
Если при чтении данных из сетевого источника возникают ошибки, приложению необходимо использовать эвристический алгоритм для повторной попытки получения данных. К распространенным эвристическим алгоритмам относятся следующие:
Экспоненциальная задержка
При экспоненциальной задержке приложение продолжает попытки чтения данных из сетевого источника с увеличивающимися интервалами времени до тех пор, пока не добьется успеха или пока другие условия не потребуют его остановки.
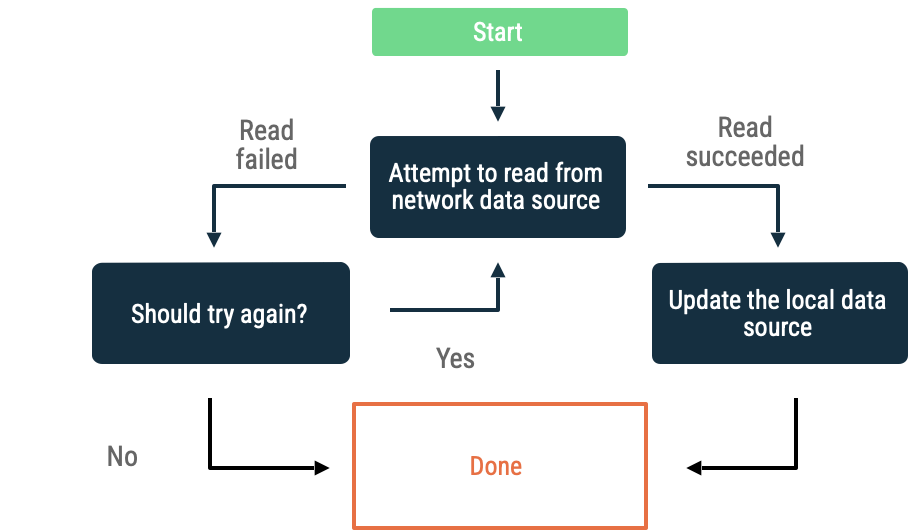
Критерии оценки того, продолжает ли приложение снижать производительность, включают следующее:
- Тип ошибки, указанный источником сетевых данных. Например, следует повторить сетевые вызовы, возвращающие ошибку, указывающую на отсутствие подключения. Не следует повторять HTTP-запросы, не авторизованные до получения корректных учетных данных.
- Максимально допустимое количество повторных попыток.
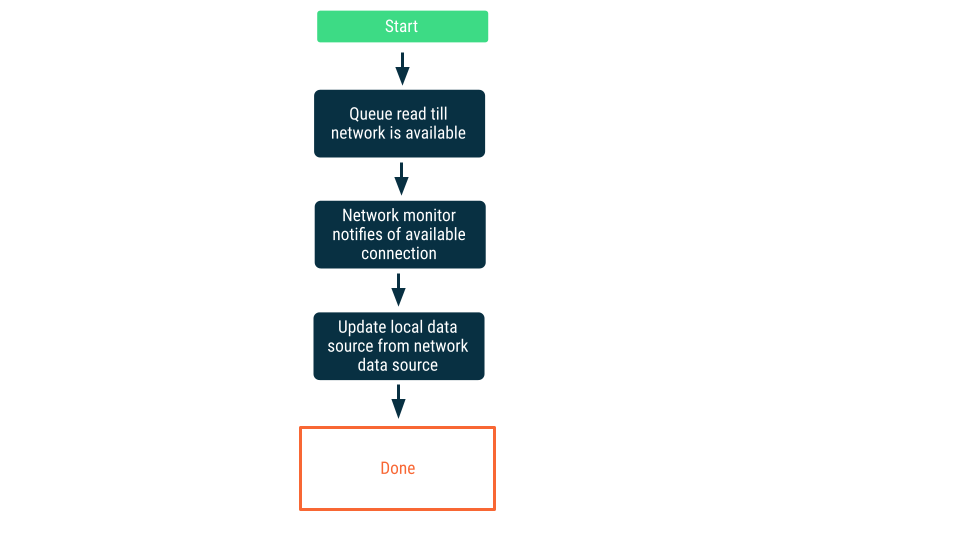
мониторинг сетевого подключения
При таком подходе запросы на чтение ставятся в очередь до тех пор, пока приложение не убедится, что может подключиться к сетевому источнику данных. После установления соединения запрос на чтение извлекается из очереди, данные считываются, и локальный источник данных обновляется. На Android эта очередь может поддерживаться с помощью базы данных Room и очищаться как постоянная задача с помощью WorkManager.
Пишет
Хотя рекомендуемый способ чтения данных в приложениях, работающих в автономном режиме, — использование наблюдаемых типов, эквивалентом для API записи являются асинхронные API, такие как функции приостановки. Это позволяет избежать блокировки потока пользовательского интерфейса и упрощает обработку ошибок, поскольку запись в приложениях, работающих в автономном режиме, может завершиться неудачей при пересечении границы сети.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
В приведенном выше фрагменте кода в качестве асинхронного API выбраны корутины , поскольку метод приостанавливается.
Разрабатывайте стратегии
При записи данных в приложениях, ориентированных на работу в офлайн-режиме, следует учитывать три стратегии. Выбор стратегии зависит от типа записываемых данных и требований приложения:
Автор статей, публикуемых исключительно в интернете.
Попытайтесь записать данные через сетевую границу. В случае успеха обновите локальный источник данных; в противном случае сгенерируйте исключение и предоставьте вызывающей стороне возможность принять соответствующие меры.
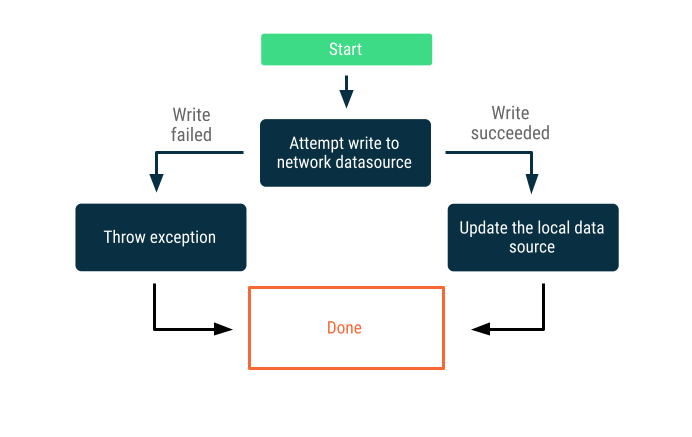
Эта стратегия часто используется для операций записи, которые должны происходить в режиме реального времени — например, банковский перевод. Поскольку запись может завершиться неудачей, часто необходимо сообщить пользователю о сбое или предотвратить попытку записи данных. Вот несколько стратегий, которые можно использовать в таких сценариях:
- Если приложению для записи данных требуется доступ к интернету, вы можете не показывать пользователю интерфейс, позволяющий записывать данные, или, по крайней мере, отключить его.
- Для уведомления пользователя о том, что он находится в автономном режиме, можно использовать
AlertDialog, который пользователь не сможет закрыть, илиSnackbar.
Queued пишет
Когда у вас есть объект, который вы хотите записать, вставьте его в очередь. Когда приложение снова подключится к сети, очистите очередь с экспоненциальной задержкой. На Android очистка офлайн-очереди — это постоянная задача, которая часто делегируется WorkManager .
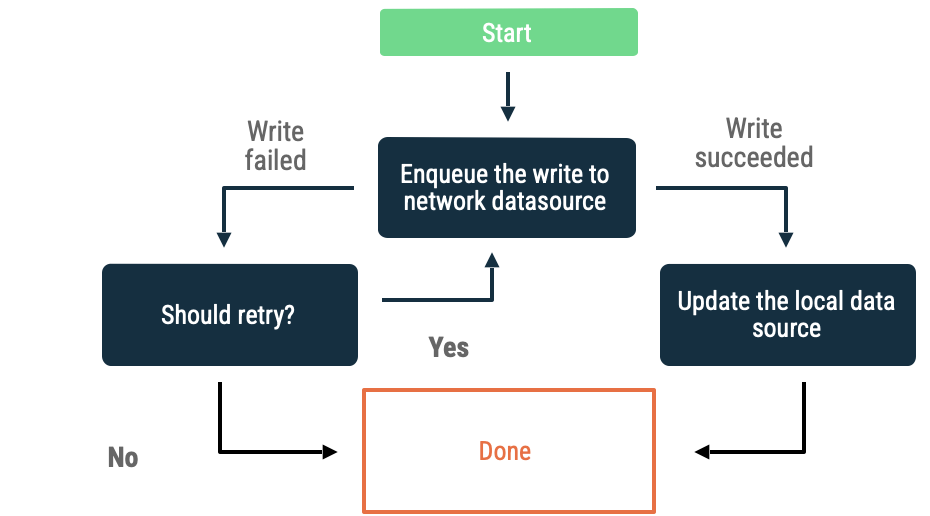
Этот подход является хорошим выбором в следующих сценариях:
- Нет необходимости записывать данные в сеть.
- Сроки совершения сделки не ограничены.
- Уведомлять пользователя в случае сбоя операции необязательно.
Примеры применения этого подхода включают аналитические события и ведение журналов.
Ленивые пишут
Сначала запишите данные в локальный источник, а затем поставьте запись в очередь, чтобы при первой же возможности уведомить сеть. Это нетривиальная задача, поскольку при повторном подключении приложения могут возникнуть конфликты между сетевым и локальным источниками данных. Более подробная информация приведена в следующем разделе, посвященном разрешению конфликтов.
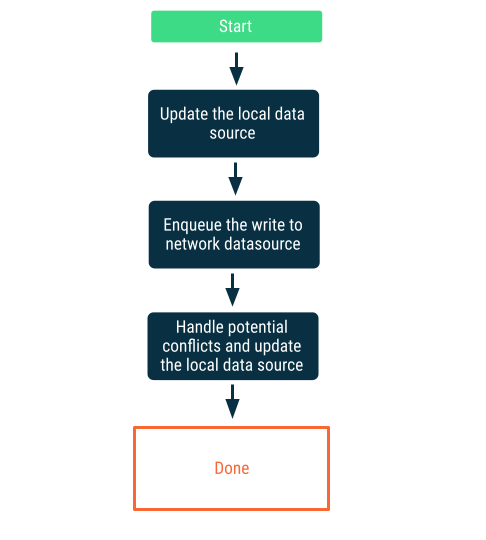
Такой подход является правильным выбором, когда данные имеют решающее значение для приложения. Например, в приложении-списке дел, ориентированном на работу в автономном режиме, крайне важно, чтобы все задачи, добавленные пользователем в автономном режиме, хранились локально во избежание риска потери данных.
Синхронизация и разрешение конфликтов
Когда приложение, работающее в автономном режиме, восстанавливает подключение к сети, ему необходимо согласовать данные в локальном источнике данных с данными в сетевом источнике данных. Этот процесс называется синхронизацией . Существует два основных способа синхронизации приложения с сетевым источником данных:
- Синхронизация на основе запросов
- Синхронизация на основе push-уведомлений
Синхронизация на основе запросов
При синхронизации по запросу приложение обращается к сети для чтения последних данных приложения по требованию. Распространенным эвристическим методом для этого подхода является навигационный подход, при котором приложение получает данные только непосредственно перед тем, как отобразить их пользователю.
Этот подход наиболее эффективен, когда приложение ожидает коротких или средних периодов отсутствия сетевого подключения. Это связано с тем, что обновление данных происходит по мере необходимости, а длительные периоды отсутствия подключения увеличивают вероятность того, что пользователь попытается посетить сайты приложения с устаревшим или пустым кэшем.
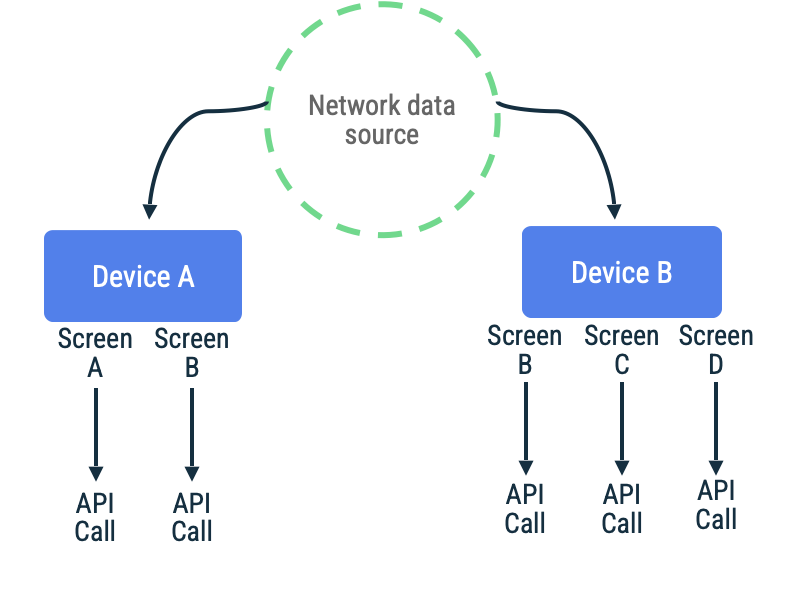
Рассмотрим приложение, в котором токены страниц используются для получения элементов в бесконечно прокручиваемом списке на определенном экране. Реализация может отложенно обращаться к сети, сохранять данные в локальном источнике данных, а затем считывать данные из локального источника данных для отображения информации пользователю. В случае отсутствия сетевого подключения репозиторий может запрашивать данные только из локального источника данных. Именно такой шаблон используется библиотекой Jetpack Paging Library с её API RemoteMediator .
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Преимущества и недостатки синхронизации по принципу "запроса" суммированы в следующей таблице:
| Преимущества | Недостатки |
|---|---|
| Реализовать относительно легко. | Склонность к интенсивному использованию данных. Это связано с тем, что повторные посещения одной и той же страницы навигации приводят к ненужной повторной загрузке неизмененной информации. Это можно смягчить с помощью надлежащего кэширования. Это можно сделать на уровне пользовательского интерфейса с помощью оператора cachedIn или на сетевом уровне с помощью HTTP-кэша. |
| Данные, которые не нужны, никогда не извлекаются. | Этот подход плохо масштабируется при работе с реляционными данными, поскольку загружаемая модель должна быть самодостаточной. Если синхронизируемая модель зависит от других моделей, которые необходимо загрузить для ее заполнения, упомянутая ранее проблема чрезмерного использования данных становится еще более серьезной. Кроме того, это может привести к зависимостям между репозиториями родительской модели и репозиториями вложенной модели. |
Синхронизация на основе push-уведомлений
При синхронизации по принципу «push» локальный источник данных пытается максимально точно воспроизвести набор реплик сетевого источника данных. При первом запуске он заблаговременно получает необходимое количество данных для установки базового уровня. После этого он полагается на уведомления от сервера, которые оповещают его об устаревании этих данных.
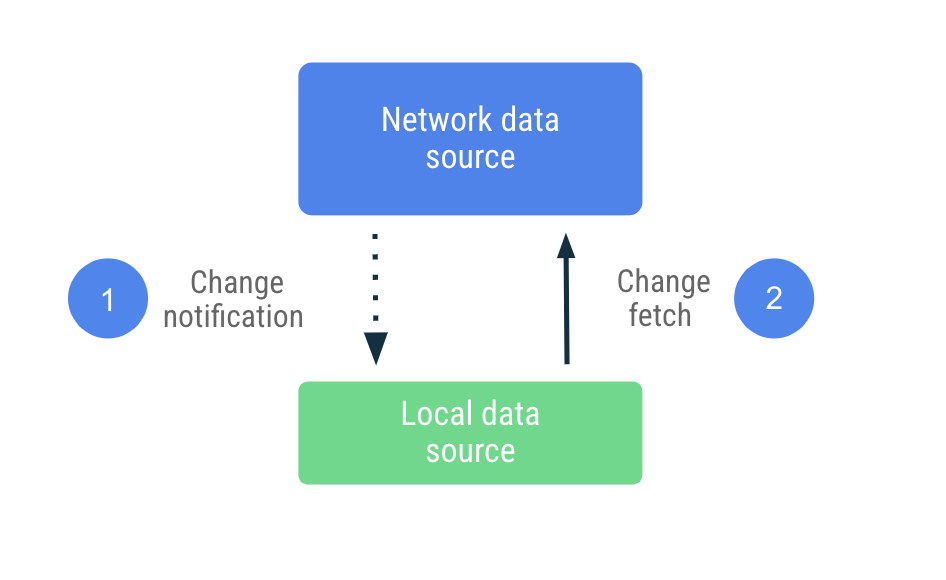
После получения уведомления об устаревании данных приложение обращается к сети для обновления только тех данных, которые были помечены как устаревшие. Эта работа делегируется Repository , который обращается к сетевому источнику данных и сохраняет полученные данные в локальном источнике данных. Поскольку репозиторий предоставляет свои данные с помощью наблюдаемых типов, читатели получают уведомления о любых изменениях.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
При таком подходе приложение гораздо меньше зависит от сетевого источника данных и может работать без него в течение длительного времени. Оно обеспечивает доступ как для чтения, так и для записи в автономном режиме, поскольку предполагает, что располагает самой актуальной информацией из сетевого источника данных локально.
Преимущества и недостатки синхронизации на основе push-уведомлений суммированы в следующей таблице:
| Преимущества | Недостатки |
|---|---|
| Приложение может оставаться в автономном режиме неограниченное время. | Создание версий данных для разрешения конфликтов — задача нетривиальная. |
| Минимальный объем используемых данных. Приложение получает только изменившиеся данные. | При синхронизации необходимо учитывать проблемы, связанные с записью данных. |
| Хорошо подходит для реляционных данных. Каждое хранилище отвечает за получение данных только для той модели, которую оно поддерживает. | Источник сетевых данных должен поддерживать синхронизацию. |
Гибридная синхронизация
Некоторые приложения используют гибридный подход, основанный на запросах (pull-speaking) или отправке (push-speaking) данных в зависимости от их объема. Например, приложение для социальных сетей может использовать синхронизацию по запросу для получения ленты подписчиков пользователя по мере необходимости из-за высокой частоты обновлений ленты. В то же время, это же приложение может выбрать синхронизацию по отправке данных для информации о вошедшем в систему пользователе, включая его имя пользователя, фотографию профиля и так далее.
В конечном итоге, выбор способа синхронизации (сначала автономный) зависит от требований к продукту и доступной технической инфраструктуры.
Разрешение конфликтов
Если в автономном режиме приложение записывает локально данные, не совпадающие с данными, хранящимися в сети, необходимо разрешить этот конфликт, прежде чем произойдет синхронизация.
Разрешение конфликтов часто требует версионирования. Приложению необходимо вести учет изменений, чтобы передавать метаданные в сетевой источник данных. Сетевой источник данных, в свою очередь, несет ответственность за предоставление абсолютной достоверной информации. Существует множество стратегий разрешения конфликтов, в зависимости от потребностей приложения. Для мобильных приложений распространенный подход — «победа последней записи».
Последний бросок клавиши выигрывает
При таком подходе устройства добавляют к данным, записываемым в сеть, метаданные в виде временных меток. Когда источник сетевых данных получает эти данные, он отбрасывает все данные старше текущего состояния, принимая при этом данные новее текущего состояния.
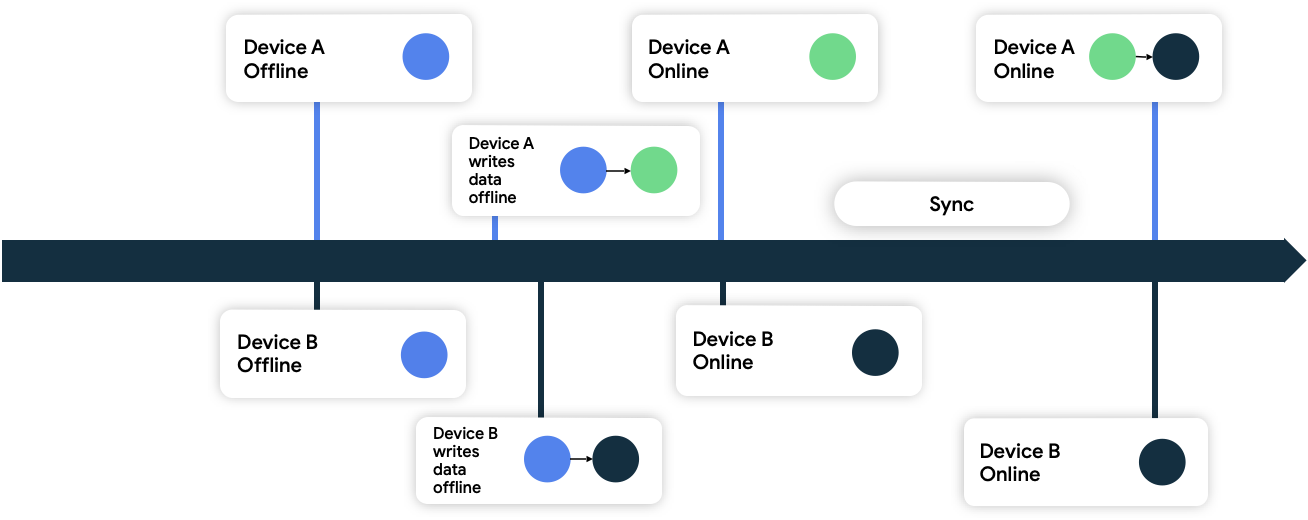
На рисунке 9 оба устройства находятся в автономном режиме и изначально синхронизированы с сетевым источником данных. В автономном режиме они оба записывают данные локально и отслеживают время записи. Когда они оба снова подключаются к сети и синхронизируются с сетевым источником данных, сеть разрешает конфликт, сохраняя данные с устройства B, поскольку оно записало свои данные позже.
Менеджер задач в приложениях, работающих в автономном режиме.
В стратегиях чтения и записи, рассмотренных ранее, есть две общие функции:
- Очереди
- Чтение: Используется для отсрочки чтения до тех пор, пока не будет восстановлено сетевое соединение.
- Функция записи: используется для отсрочки операций записи до восстановления сетевого соединения, а также для повторной постановки операций записи в очередь.
- Мониторы сетевого подключения
- Чтение: Используется в качестве сигнала для очистки очереди чтения при подключении приложения, а также для синхронизации.
- Запись: Используется в качестве сигнала для очистки очереди записи при подключении приложения, а также для синхронизации.
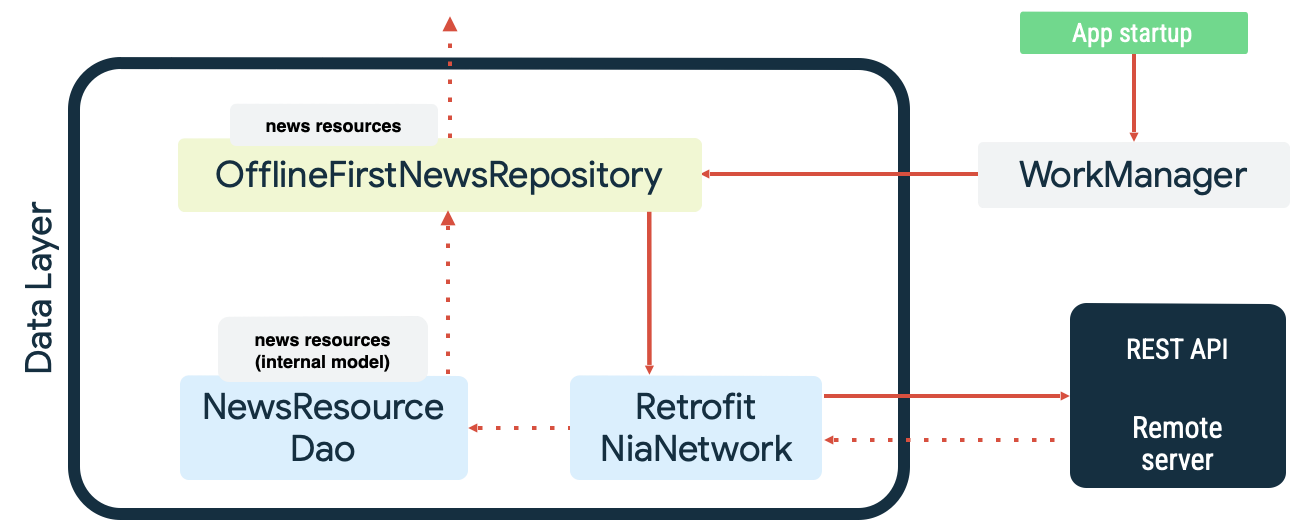
Оба случая являются примерами продуктивной работы , в которой WorkManager проявляет себя наилучшим образом. Например, в демонстрационном приложении Now in Android WorkManager используется как очередь чтения и сетевой монитор при синхронизации локального источника данных. При запуске приложение выполняет следующие действия:
- Синхронизация чтения из очередей обеспечивает соответствие между локальным и сетевым источниками данных.
- Очищает очередь синхронизации чтения и начинает синхронизацию, когда приложение подключено к сети.
- Выполняет чтение данных из сетевого источника с использованием экспоненциальной задержки.
- Сохраняет результаты чтения в локальный источник данных и разрешает любые возникающие конфликты.
- Предоставляет доступ к данным из локального источника данных для использования другими уровнями приложения.
Эти действия проиллюстрированы на следующей диаграмме:
Для добавления задачи синхронизации в очередь с помощью WorkManager необходимо указать ее как уникальную задачу, используя политику KEEP ExistingWorkPolicy :
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() определен следующим образом:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
В частности, Constraints определенные в SyncConstraints требуют, чтобы NetworkType был NetworkType.CONNECTED . То есть, выполнение программы начинается только после того, как сеть станет доступной.
Как только сеть станет доступна, Worker очищает уникальную очередь задач, указанную в SyncWorkName , делегируя задачи соответствующим экземплярам Repository . Если синхронизация не удалась, метод doWork() возвращает Result.retry() . WorkManager автоматически повторит синхронизацию с экспоненциальной задержкой. В противном случае он возвращает Result.success() , завершая синхронизацию.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Образцы
Следующие примеры от Google демонстрируют приложения, ориентированные на работу в автономном режиме. Изучите их, чтобы увидеть применение этих рекомендаций на практике:
Рекомендуем вам
- Примечание: текст ссылки отображается, когда JavaScript отключен.
- Производство состояния пользовательского интерфейса
- слой пользовательского интерфейса
- Слой данных